公众号
前言
从这周开始,我们关注基于attention机制的推荐模型,首先看下较早提出的AFM(Attentional Factorization Machines)模型.论文链接:AFM
论文作者认为,并非所有的特征交互都包含有效信息,因此那些"less userful features"应该赋予更低的权重.很明显,当无效信息和有效信息权重相同时,相当于引入了噪声.而FM缺乏区分不同特征重要性的能力,可能会获得次优解.
怎么赋予权重呢?神经网络中最常见的就是映射,加个权重矩阵(wx+b),但这种线性的权重,有时不能满足需要.论文中使用了一层映射+sum pooling+sotfmax构建出了非线性权重系数,作者称之为"Attention-based Pooling".
模型介绍
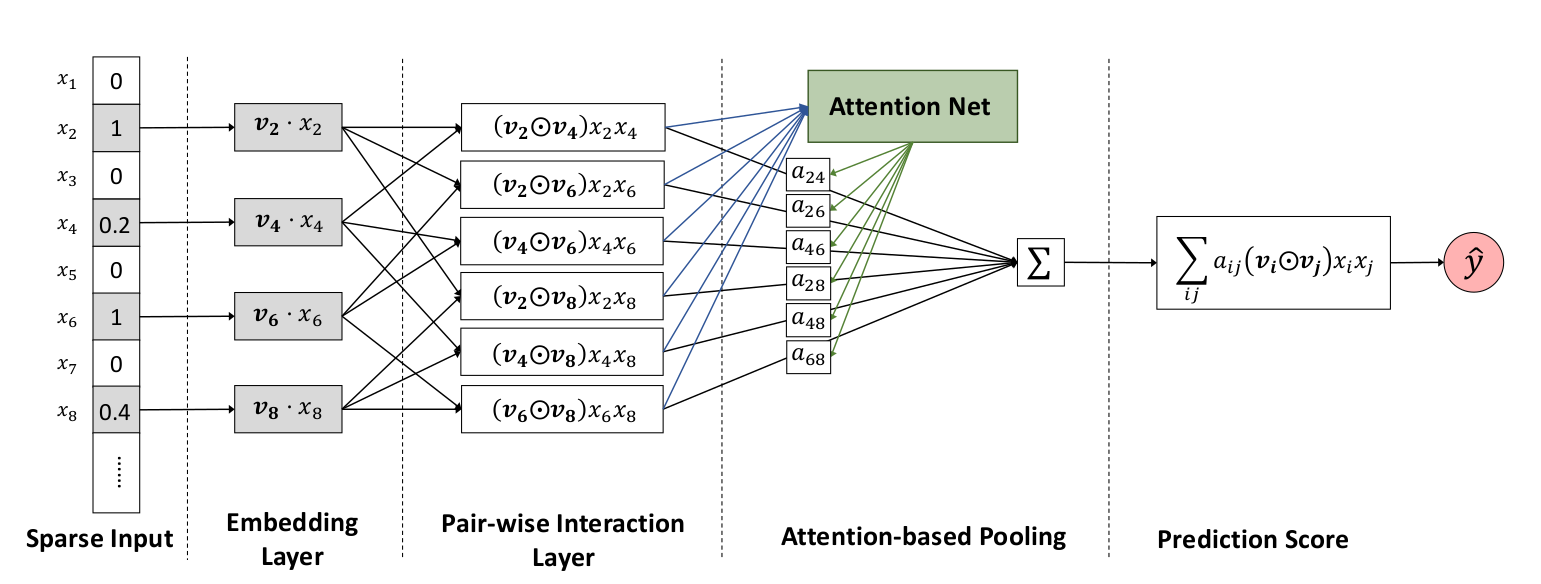
从整体上看,AFM就是FM+Attention.,前面一部分embeding和pair-wise和FM模型的是类似的,然后后面加了个attention机制,就是AFM模型.
首先看前面一部分.FM中特征的交互是’inner product’,两个向量做内积,结果是一个值.而AFM中特征交互是’element-wise product’,两个向量对应元素相乘,结果是向量:
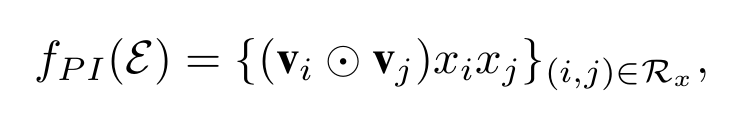
然后给向量一个映射矩阵,对向量元素求和,得到交叉特征部分的预测结果,就是论文中的’sum pooling’:
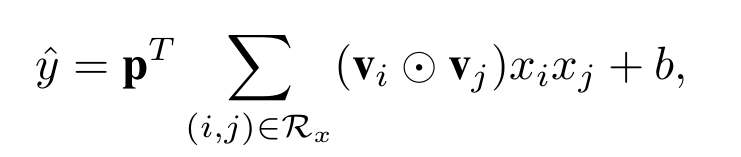
这就是AFM和FM在特征交互不同的地方,p可以看成是sum pooling,也可以认为是embedding特征的权重矩阵,加上后文交互特征的attention权重,可以说比FM多了两层权重,一层区分交互特征重要性,一层区分embedding各维特征的重要性.从而大大提高了模型的拟合能力.attention系数可以这样加上去:
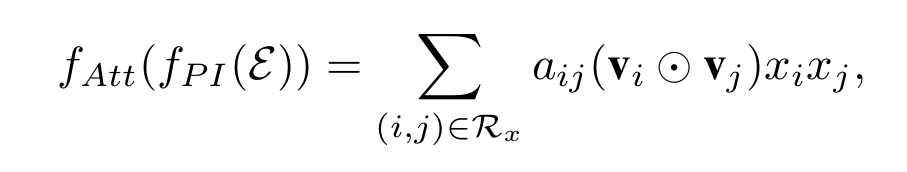
aij可以直接通过最小化损失函数求得,但是当xi,xj没有共同出现时,是求不出对应的aij的.为了获得更加通用的模型,作者将attention score–aij进行参数化(有没有似曾相识,想想FM),并使用如下公式来定义:
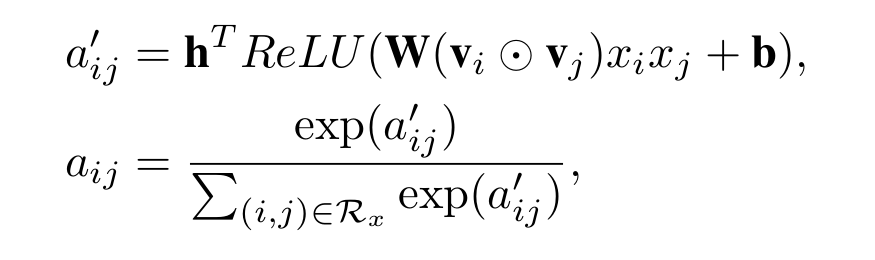
所以,最终模型的预测值可以表示为:
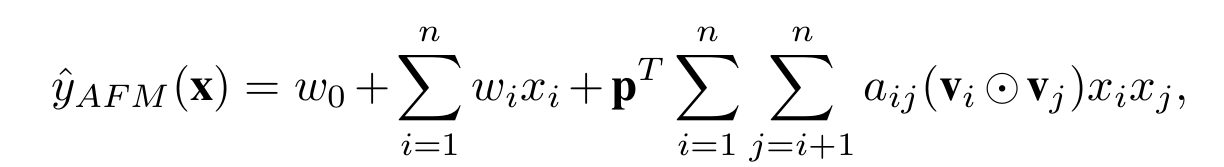
代码实战
代码通俗易懂,数据也很小,我们着重看一下attention部分怎么实现的,代码格式容易乱,直接截个图吧:
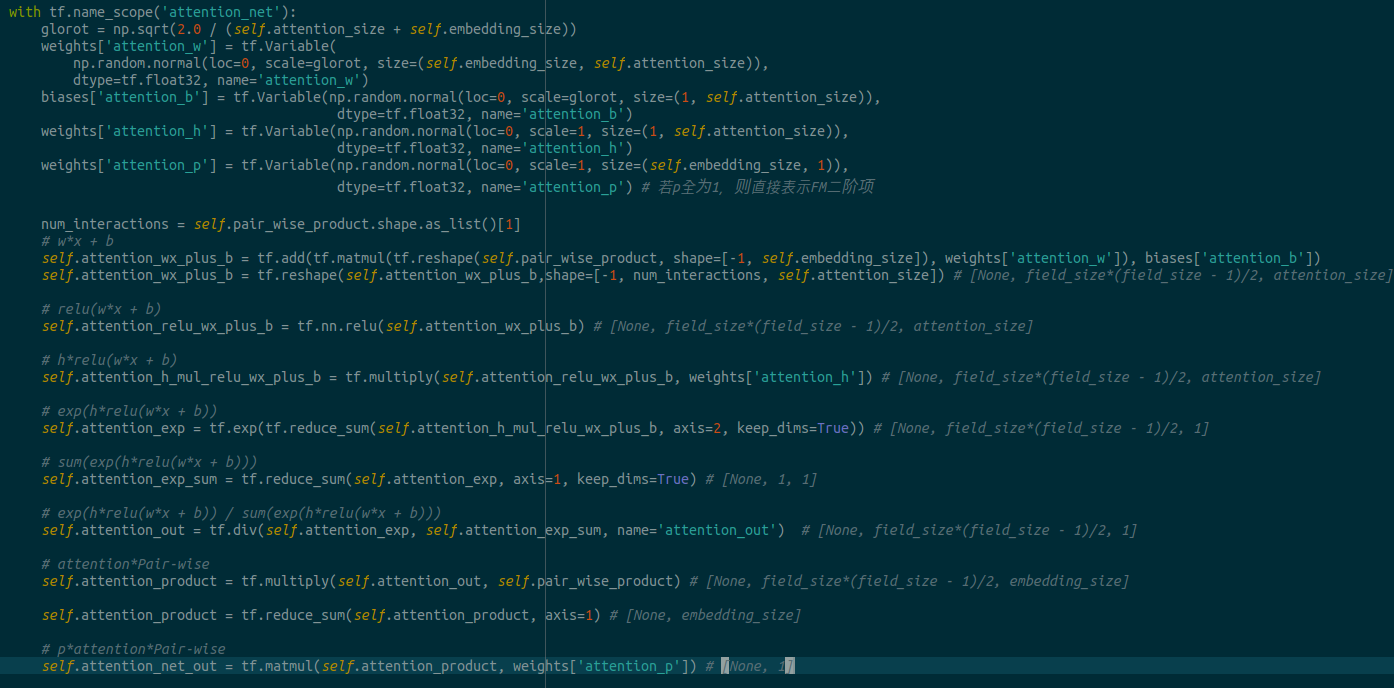
实际就是根据公式一步步计算的,清晰易懂,变量名称和论文都是保持一致的.最后的输出结果就是线性拟合和特征交叉这部分之和:

这份代码简单易懂,从前到后逻辑很清晰,可以拿来练习tensorflow.
原代码:源代码出处
我修改了一些细节,完整代码和数据
