写在前面
深度学习在很多情况下都涉及优化。
寻找神经网络上的一组参数$\theta$,它能显著地降低代价函数$J(\theta)$,该代价函数通常包括整个训练集上的性能评估和额外的正则化项。
机器学习是一个高度依赖经验的过程,伴随着大量迭代的过程,你需要训练诸多模型,才能找到合适的那一个,所以,优化算法能够帮助你快速训练模型。
深度学习没有在大数据领域发挥最大的效果,我们可以利用一个巨大的数据集来训练神经网络,而在巨大的数据集基础上训练速度很慢。
Mini-batch梯度下降法
之前的Batch梯度下降法是每次把整个训练集拿来训练,当训练集很大,比如上百万时,处理速度是很慢的。可以把训练集分割为小一点的子训练集,这些子集被取名为mini-batch。对于每一个mini-batch来说,梯度下降过程和之前的batch梯度下降法是一样的,只不过是样本数量变少了。执行完整个训练集称为进行“1 epoch”的训练,意味着遍历了整个训练集。
如果你有一个较大的数据集,那么mini-batch梯度下降法比batch梯度下降法运行地更快。batch梯度下降法一次遍历只做一次梯度下降,而mini-batch梯度下降法一次遍历可以做多次梯度下降。
Mini-batch梯度下降法的理解
使用batch梯度下降法时,每次迭代都需要遍历整个训练集,可以预期每次迭代成本都会下降,如果在某次迭代中增加了,那肯定出了问题,可能是你的学习率太大。
使用mini-batch梯度下降法,如果你做出成本函数在整个过程中的图,则并不是每次迭代都是下降的,因为每次迭代都在训练不同的样本集或者说训练不同的mini-batch。作出图型,你可能会看到整体趋势是下降的,但是会出现波动。
mini-batch size
如果mini-batch的大小等于样本大小m,其实就是batch梯度下降法。
如果mini-batch的大小为1,这叫做随机梯度下降法。随机梯度下降法永远不会收敛,而是会一直在最小值附近波动,但他并不会达到最小值并停留。且会失去向量化带来的加速,因为一次只处理一个样本,效率过于低下。总之随机梯度下降法计算得到的并不是准确的一个梯度,容易陷入到局部最优解中
实际上选择的mini-batch大小在二者之间,如果训练集较小(小于2000个样本),直接使用batch梯度下降法。一般的mini-batch大小为64到512,考虑到电脑内存设置和使用的方式,如果mini-batch大小是2的n次方,代码会运行地快一些。
最后需要注意的是在这里的mini-batch中,要确保每一个mini-batch符合CPU/GPU内存,这取决于你的应用方向以及训练集的大小。
指数加权平均
指数加权平均原理参考 指数平滑模型
在优化算法中的本质作用
从指数加权平均的公式并递推可以看出,预测的数值是之前所有值的加和并平均。
指数加权平均数的一个好处是占用极少内存,因为每次只需把最新数据带入公式,不断覆盖就可以了。但它不是最精准的计算平均数的方法,计算移动窗会得到更好的估测,但是要保存所有最近的数值,必须占用更多的内存。
所以在优化算法中,会计算多个变量的平均值,从计算和内存效率来说,这是一个有效的方法。只需要一行代码。
偏差修正
上面这种滑动平均的方式,在再开始是不准确的(比如最开始让第一个值为0),此时使用$\frac{v_{t}}{1-\beta^t}$,当t很大的时候,$\beta^t$接近于0,修正偏差基本没有作用,不过在开始学习阶段,偏差修正可以更好地帮助预测值。
在机器学习中,在计算指数加权平均的大部分时候,大家都不在乎执行偏差修正,因为大部分人宁愿熬过初始时期,拿到具有偏差的估测,然后继续计算下去。如果你关心初始时期的偏差,在刚开始计算指数加权平均数的时候,偏差修正能帮助你在早期获取更好的估测。
动量梯度下降法(Gradient descent with Momentum)
有一种算法叫做Momentum,或者叫做动量梯度下降法,运行速度几乎总是快于标准梯度下降算法。
基本想法就是计算梯度的指数加权平均数,并利用该梯度更新你的权重。
在之前mini-batch的优化算法中,你需要使用一个较小的学习率,防止摆动过大,使用较小的学习率,这样就导致了达到最小值需要很多计算步骤。
算法
在t次迭代的时候,计算$dW, db$
$$v_{dW} = \beta v_{dW} + (1-\beta)dW$$
$$v_{db} = \beta v_{db} + (1-\beta)db$$
$$W = W-\alpha v_{dW}, b = b – \alpha v_{db}$$
有两个超参数,学习率$\alpha$以及$\beta$,$\beta$控制着指数加权平均数,最常用的值是0.9,相当于平均了前10次迭代的梯度。
关于偏差修正,由于10次迭代后,你的移动平均已经过了初始阶段,所以在实际中,动量梯度下降法不会受到偏差修正的影响。
Nesterov accelerated gradient
上面的momentum梯度下降法,每一步都是由前面下降方向的一个累积和当前梯度方向组合而成。
而Nesterov是按照历史梯度往前走那么一小步,按照前面一小步位置的“超前梯度”来做梯度合并。如此一来,可以先往前走一步,在靠前一点的位置看到梯度,然后按照那个位置再来修正这一步的梯度方向,有了超前的眼光。
算法
在t次迭代的时候,
$$v_{t} = \beta v_{t-1} + \alpha\Delta_{\theta}J(\theta – \beta v_{t-1})$$
$$\theta = \theta – v_{t}$$
AdaGard
独立的适应于所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平方值总和的平方根。
具有损失最大偏导的参数相应的有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。净效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。
算法
在t次迭代的时候,计算$dW, db$
$$S_{dW} = S_{dW} + dW^2$$
$$S_{db} = S_{db} + db^2$$
$$W = W-\alpha \frac{dW}{\sqrt{S_{dW}} + \epsilon}, b = b – \alpha \frac{dv}{\sqrt{S_{db}} + \epsilon }$$
RMSprop
全称是root mean square prop算法,它也可以加速梯度下降。和上面的AdaGrad算法类似,不过是使用了滑动平均。
假设纵轴代表参数$W$,横轴代表参数$b$,所以你想减缓$b$方向上的学习,同时加快横轴方向上的学习。
算法
在t次迭代的时候,计算$dW, db$
$$S_{dW} = \beta S_{dW} + (1-\beta)dW^2$$
$$S_{db} = \beta S_{db} + (1-\beta)db^2$$
$$W = W-\alpha \frac{dW}{\sqrt{S_{dW}+\epsilon }}, b = b – \alpha \frac{dv}{\sqrt{S_{db} + \epsilon }}$$
有两个超参数,学习率$\alpha$以及$\beta$,$\beta$控制着指数加权平均数,最常用的值是0.9,相当于平均了前10次迭代的梯度。$\epsilon$是一个很小很小的数,防止除0。
原理
纵轴方向比较大,所以会除以一个较大的值,以消除摆动。
横轴方向比较小,所以会除以一个较小的值,以增加速度。
在实际中,参数$W$,$b$可能在各个方向都有,但是我们始终是在消除摆动的维度中,除以一个较大值。
Adam优化算法(Adam optimization algorithm)
Adam代表的是Adaptive Moment Estimation。
Adam优化算法基本上就是将Momentum和RMSprop结合在一起,是一种极其常用的算法,被证明能有效适用于不同神经网络,适用于广泛的结构。
算法
初始化$v_{dW} = 0, S_{dW} = 0, v_{db} = 0, S_{db} = 0$
在t次迭代的时候,计算$dW, db$
$$v_{dW} = \beta_{1} v_{dW} + (1-\beta_{1})dW$$
$$v_{db} = \beta_{1} v_{db} + (1-\beta_{1})db$$
$$S_{dW} = \beta_{2} S_{dW} + (1-\beta_{2})dW^2$$
$$S_{db} = \beta_{2} S_{db} + (1-\beta_{2})db^2$$
偏差修正:
$$v_{dW}^{corrected} = \frac{v_{dW}}{1-\beta_{1}^t}$$
$$v_{db}^{corrected} = \frac{v_{db}}{1-\beta_{1}^t}$$
$$S_{dW}^{corrected} = \frac{S_{dW}}{1-\beta_{2}^t}$$
$$S_{db}^{corrected} = \frac{S_{db}}{1-\beta_{2}^t}$$
$$W = W – \alpha \frac{v_{dW}^{corrected}}{\sqrt{S_{dW}^{corrected}} + \epsilon}$$
$$b = b – \alpha \frac{v_{db}^{corrected}}{\sqrt{S_{db}^{corrected}} + \epsilon}$$
超参数学习率$\alpha$很重要,需要经常调试,而$\beta_{1},\beta_{2}$常用缺省值0.9和0.999,很少需要调整。
学习率衰减
加快学习算法的一个办法就是随着时间慢慢减少学习率,我们称之为学习率衰减。
使用固定的学习率,算法会在最后最小值的附近摆动,不会真正的收敛。
慢慢较小学习率$\alpha$的话,在初期的时候,学习相对较快,随着$\alpha$变小,学习的步伐会变慢变小,最后会在最小值附近的一小块区域摆动。
学习率衰减是基于epoch的,即每次要遍历完所有训练数据再进行衰减。可以使用下面的公式:
$$\alpha = \frac{1}{1+decay-rate * epoch-num}\alpha_{0}$$
示例($\alpha_{0} = 0.2$):
1
0.1
3
0.67
3
0.5
4
0.4
其他公式:
$$\alpha = 0.95^{epoch-num} \cdot \alpha_{0}$$
$$\alpha = \frac{k}{\sqrt{epoch-num}} \cdot \alpha_{0}$$
局部最优问题
在低维空间,比如三维,我们往往想到的局部最优是一个函数(梯度为0)的极小值,但是当在高维空间(比如20000维)的时候,当梯度为0的时候,可能是有多个方向,同时存在凸函数和凹函数,这个时候更像一个鞍点。
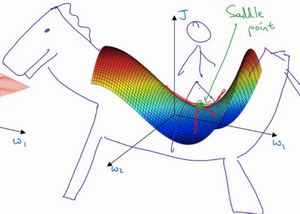
即是说,我们对低维度空间的大部分直觉并不能应用到高纬度空间。
如果局部最优不是问题,那么问题就是平稳段会减缓学习,平稳段是一块区域,其中导数长时间接近于0。所以需要向Momentum、RMSprop、Adam这样的算法。能够加速学习算法,快速的走出平稳段。
参考文献:
第二周:优化算法 (Optimization algorithms)
深度学习中的优化算法
