一、CPU最大性能模式
cpu利用特点
-
5.1 最高可用4个核
-
5.5 最高可用24核
-
5.6 最高可用64核心
-
一次query对应一个逻辑CPU
你仔细检查的话,有些服务器上会有的一个有趣的现象:你cat /proc/cpuinfo时,会发现CPU的频率竟然跟它标称的频率不一样:
2
3
4
5
6
2processor : 5
3model name : Intel(R) Xeon(R) CPU E5-2620 0 @2.00GHz
4...
5cpu MHz : 1200.000
6
这个是Intel E5-2620的CPU,他是2.00G * 24的CPU,但是,我们发现第5颗CPU的频率为1.2G
**原因:**其实都源于CPU最新的技术:节能模式。操作系统和CPU硬件配合,系统不繁忙的时候,为了节约电能和降低温度,它会将CPU降频。这对环保人士和抵制地球变暖来说是一个福音,但是对MySQL来说,可能是一个灾难。
为了保证MySQL能够充分利用CPU的资源,建议设置CPU为最大性能模式,这个设置可以在BIOS和操作系统中设置
二、关闭numa
非一致存储访问结构 (NUMA : Non-Uniform Memory Access) 也是最新的内存管理技术。它和对称多处理器结构 (SMP : Symmetric Multi-Processor) 是对应的。简单的队别如图:
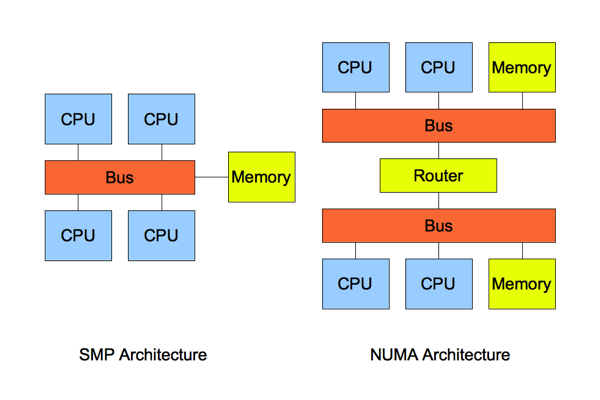
但是我们可以直观的看到:SMP访问内存的都是代价都是一样的;但是在NUMA架构下,本地内存的访问和非本地内存的访问代价是不一样的。对应的根据这个特性,操作系统上,我们可以设置进程的内存分配方式。目前支持的方式包括:
2
3
4
5
6
7
2--membind=nodes
3--cpunodebind=nodes
4--physcpubind=cpus
5--localalloc
6--preferred=node
7
简而言之,就是说,你可以指定内存在本地分配,在某几个CPU节点分配或者轮询分配。除非是设置为–interleave=nodes轮询分配方式,即内存可以在任意NUMA节点上分配这种方式以外。
其他的方式就算其他NUMA节点上还有内存剩余,Linux也不会把剩余的内存分配给这个进程,而是采用SWAP的方式来获得内存。有经验的系统管理员或者DBA都知道SWAP导致的数据库性能下降 ,所以最简单的方法,还是关闭掉这个特性
关闭特性的方法,分别有:
-
可以从BIOS设置关闭
-
启动MySQL的时候,关闭NUMA特性 numactl –interleave=all mysqld &
-
OS内核,启动时设置numa=off
-
在操作系统中关闭,可以直接在/etc/grub.conf的kernel行最后添加numa=off,如下所示
2
2
设置vm.zone_reclaim_mode=0尽量回收内存
三、关闭vm.swappiness
vm.swappiness是操作系统控制物理内存交换出去的策略。它允许的值是一个百分比的值,最小为0,最大运行100,该值默认为60
vm.swappiness设置为0表示尽量少swap,100表示尽量将inactive的内存页交换出去。
当内存基本用满的时候,系统会根据这个参数来判断是把内存中很少用到的inactive 内存交换出去,还是释放数据的cache。cache中缓存着从磁盘读出来的数据,根据程序的局部性原理,这些数据有可能在接下来又要被读取;inactive 内存顾名思义,就是那些被应用程序映射着,但是“长时间”不用的内存。
我们可以查看inactive的内存的数量:
2
3
4
5
6
7
8
9
10
11
12
13
2procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
3 r b swpd free inact active si so bi bo in cs us sy id wa st
4 0 0 61432 1533944 1553788 3190400 0 0 9 216 0 0 5 2 88 4 0
5 0 0 61432 1533564 1553900 3190568 0 0 0 120 616 349 2 1 97 1 0
6 1 0 61432 1533068 1553844 3191096 0 0 0 5748 1604 455 1 1 95 3 0
7 2 1 61432 1531952 1553812 3191984 0 0 172 700 1033 416 2 1 74 23 0
8
9[root@locahost ~]# cat /proc/meminfo | grep -i inact
10Inactive: 1557236 kB
11Inactive(anon): 279888 kB
12Inactive(file): 1277348 kB
13
Linux中,内存可能处于三种状态:free,active和inactive
Linux Kernel在内部维护了很多LRU列表用来管理内存,比如LRU_INACTIVE_ANON, LRU_ACTIVE_ANON, LRU_INACTIVE_FILE , LRU_ACTIVE_FILE, LRU_UNEVICTABLE。其中LRU_INACTIVE_ANON, LRU_ACTIVE_ANON用来管理匿名页,LRU_INACTIVE_FILE , LRU_ACTIVE_FILE用来管理page caches页缓存。系统内核会根据内存页的访问情况,不定时的将活跃active内存被移到inactive列表中,这些inactive的内存可以被交换到swap中去。
MySQL,特别是InnoDB管理内存缓存,它占用的内存比较多,不经常访问的内存也会不少,这些内存如果被Linux错误的交换出去了,将浪费很多CPU和IO资源。 InnoDB自己管理缓存,cache的文件数据来说占用了内存,对InnoDB几乎没有任何好处。
所以,我们在MySQL的服务器上最好设置vm.swappiness=0。
我们可以通过在sysctl.conf中添加一行:
2
2
四、文件系统
建议在文件系统的mount参数上加上noatime,nobarrier两个选项
用noatime mount的话,文件系统在程序访问对应的文件或者文件夹时,不会更新对应的access time。一般来说,Linux会给文件记录了三个时间,change time, modify time和access time。
我们可以通过stat来查看文件的三个时间:
2
3
4
5
6
7
8
9
2 File: `mysql-test.sh'
3 Size: 970 Blocks: 8 IO Block: 4096 regular file
4Device: ca01h/51713d Inode: 33883111 Links: 1
5Access: (0644/-rw-r--r--) Uid: ( 0/ root) Gid: ( 0/ root)
6Access: 2015-12-16 19:55:58.962535495 +0800
7Modify: 2015-12-11 09:15:38.410196493 +0800
8Change: 2015-12-11 09:15:38.493196460 +0800
9
-
access time指文件最后一次被读取的时间
-
modify time指的是文件的文本内容最后发生变化的时间
-
change time指的是文件的inode最后发生变化(比如位置、用户属性、组属性等)的时间
一般来说,文件都是读多写少,而且我们也很少关心某一个文件最近什么时间被访问了。所以,我们建议采用noatime选项,这样文件系统不记录access time,避免浪费资源
现在的很多文件系统会在数据提交时强制底层设备刷新cache,避免数据丢失,称之为write barriers。但是,其实我们数据库服务器底层存储设备要么采用RAID卡,RAID卡本身的电池可以掉电保护;要么采用Flash卡,它也有自我保护机制,保证数据不会丢失。所以我们可以安全的使用nobarrier挂载文件系统。设置方法如下: 对于ext3, ext4和 reiserfs文件系统可以在mount时指定barrier=0;对于xfs可以指定nobarrier选项
文件系统上还有一个提高IO的优化万能钥匙,那就是deadline
在Flash技术之前,我们都是使用机械磁盘存储数据的,机械磁盘的寻道时间是影响它速度的最重要因素,直接导致它的每秒可做的IO(IOPS)非常有限,为了尽量排序和合并多个请求,以达到一次寻道能够满足多次IO请求的目的,Linux文件系统设计了多种IO调度策略,已适用各种场景和存储设备。
Linux的IO调度策略包括:Deadline scheduler,Anticipatory scheduler,Completely Fair Queuing(CFQ),NOOP
CFQ是Linux内核2.6.18之后的默认调度策略,它声称对每一个 IO 请求都是公平的,这种调度策略对大部分应用都是适用的。但是如果数据库有两个请求,一个请求3次IO,一个请求10000次IO,由于绝对公平,3次IO的这个请求都需要跟其他10000个IO请求竞争,可能要等待上千个IO完成才能返回,导致它的响应时间非常慢。并且如果在处理的过程中,又有很多IO请求陆续发送过来,部分IO请求甚至可能一直无法得到调度被“饿死”。而deadline兼顾到一个请求不会在队列中等待太久导致饿死,对数据库这种应用来说更加适用
CFQ与Deadline,NOOP性能差异很小,但是一旦有大的连续IO,CFQ可能会造成小IO的响应延时增加,所以数据库环境建议修改为deadline算法,表现更稳定。我们的环境统一使用deadline算法。
IO调度算法都是基于磁盘设计,所以减少磁头移动是最重要的考虑因素之一,但是使用Flash存储设备之后,不再需要考虑磁头移动的问题,可以使用NOOP算法。NOOP的含义就是NonOperation,意味着不会做任何的IO优化,完全按照请求来FIFO的方式来处理IO。
减少预读:/sys/block/sdb/queue/read_ahead_kb,默认128,调整为16
增大队列:/sys/block/sdb/queue/nr_requests,默认128,调整为512
实时设置,我们可以通过
2
2
我们也可以直接在/etc/grub.conf的kernel行最后添加elevator=deadline来永久生效
五、RAID优化
关闭读cache:RAID卡上的cache容量有限,我们选择direct方式读取数据,从而忽略读cache。
关闭预读:RAID卡的预读功能对于随机IO几乎没有任何提升,所以将预读功能关闭。
关闭磁盘cache:一般情况下,如果使用RAID,系统会默认关闭磁盘的cache,也可以用命令强制关闭。
以上设置都可以通过RAID卡的命令行来完成
开启BBWC
RAID卡都有写cache(Battery Backed Write Cache),写cache对IO性能的提升非常明显,因为掉电会丢失数据,所以必须由电池提供支持。电池会定期充放电,一般为90天左右,当发现电量低于某个阀值时,会将写cache策略从writeback置为writethrough,相当于写cache会失效,这时如果系统有大量的IO操作,可能会明显感觉到IO响应速度变慢。目前,新的RAID卡内置了flash存储,掉电后会将写cache的数据写入flash中,这样就可以保证数据永不丢失,但依然需要电池的支持。
解决方案有两种:1.人工触发充放电,可以选择在业务低谷时做,降低对应用的影响;2.设置写cache策略为force write back,即使电池失效,也保持写cache策略为writeback,这样存在掉电后丢失数据的风险。
六、Flashcache
创建flashcache:flashcache_create -b 4k cachedev /dev/sdc /dev/sdb
指定flashcache的block大小与Percona的page大小相同。
Flashcache参数设置:
2
3
4
5
6
2flashcache.reclaim_policy = 1:脏块刷出策略,0:FIFO,1:LRU
3flashcache.dirty_thresh_pct = 90:flashcache上每个hash set上的脏块阀值
4flashcache.cache_all = 1:cache所有内容,可以用黑名单过滤
5flashecache.write_merge = 1:打开写入合并,提升写磁盘的性能
6
七、IOPS
磁盘寻道能力(磁盘I/O),以目前高转速SCSI硬盘(7200转/秒)为例,这种硬盘理论上每秒寻道7200次,这是物理特性决定的,没有办法改变。 MySQL每秒钟都在进行大量、复杂的查询操作,对磁盘的读写量可想而知。所以,通常认为磁盘I/O是制约MySQL性能的最大因素之一,对于日均访问量 在100万PV以上的Discuz!论坛,由于磁盘I/O的制约,MySQL的性能会非常低下!解决这一制约因素可以考虑以下几种解决方案: 使用RAID-0+1磁盘阵列,注意不要尝试使用RAID-5,MySQL在RAID-5磁盘阵列上的效率不会像你期待的那样快
2
3
4
5
6
7
8
9
2innodb_adaptive_checkpoint:如果使用fusionio,设置为3,提高刷新频率到0.1秒;使用SAS磁盘,设置为2,采用estimate方式刷新脏页。
3innodb_io_capacity:根据IOPS能力设置,使用fuionio可以设置10000以上。
4innodb_flush_neighbor_pages = 0:针对fusionio或者SSD,因为随机IO足够好,所以关闭此功能。
5innodb_flush_method=ALL_O_DIRECT:公版的MySQL只能将数据库文件读写设置为DirectIO,对于Percona可以将log和数据文件设置为direct方式读写。但是我不确定这个参数对于innodb_flush_log_at_trx_commit的影响,
6innodb_read_io_threads = 1:设置预读线程设置为1,因为线性预读的效果并不明显,所以无需设置更大。
7innodb_write_io_threads = 16:设置写线程数量为16,提升写的能力。
8innodb_fast_checksum = 1:开启Fast checksum特性。
9
