这个练习项目来自《Python基础教程(第2版)》,案例原名为“使用XML-RPC进行文件共享”。
原文是基于Pyhton2.7,其中使用的一些模块在Python3中已经发生改变,这里使用Python3完成这个练习项目 。
练习过程分为两个阶段:
- 实现基本文件共享功能
- 实现基于CMD客户端界面的文件分享功能
在开始练习之前,我们先了解一下P2P(Peer to Peer)的基本原理。
P2P原为网络通信技术名词,意思是“对等网络”。
在了解对等网络之前,我们先来看一下网络连接模式中另外一种形式的网络,即客户端/服务器网络(Client/Server)。在客户端/服务器网络中,服务器是网络的核心,而客户端是网络的基础,客户端依靠服务器获得所需要的网络资源,而服务器为客户端提供网络必须的资源。
为了更清楚的理解,我用一张简单的图来表示。
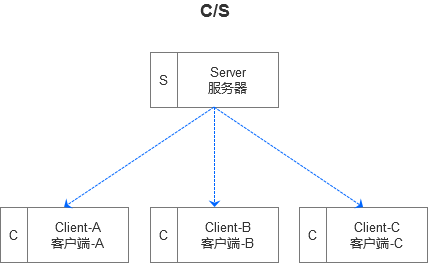
而对等网络则是另外一种形式,在对等网络上,各台计算机有相同的功能,无主从之分,一台计算机都是既可作为服务器,设定共享资源供网络中其他计算机所使用,也可以作为客户端获取其他计算机上的共享资源。
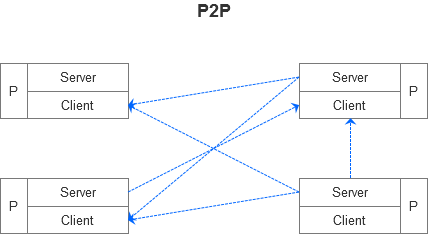
大家常用的BT下载,就是对等网络的一种具体实现。
当我们使用BT下载软件时,我们的计算机既是服务器又是客户端,不但能够下载自己需要的资源,同时也在上传他人需要的资源(即为其他计算机提供资源共享服务)。

在对等网络中,每一台计算机都是一个节点,当一个节点进行资源下载的时候,是如何工作的呢?
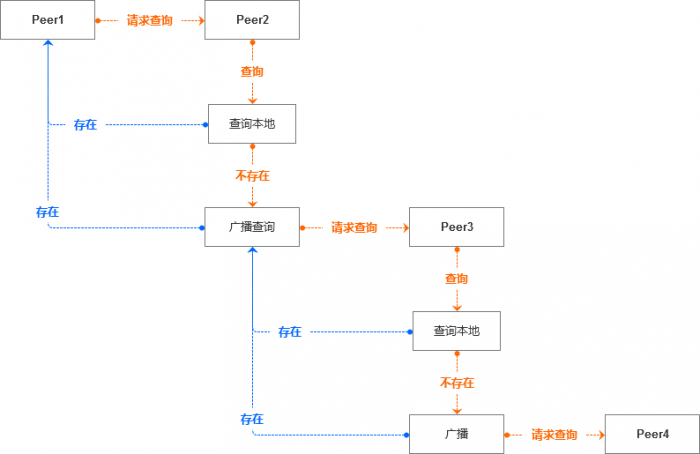
如上图所示,当节点Peer1进行资源下载时,会先通过广播功能向所有已知节点发出请求,当某个节点(例如Peer2)收到请求,立即对请求进行处理,先对本地资源进行查询。如果找到相应的资源,则回复Peer1节点;如果没有找到可以提供的资源,则通过广播功能向自己的所有已知节点转发Peer1的请求。以此类推。
不过,大家能够想到,这样一层一层的进行请求,几乎是没有尽头的。

说明:上图中数字表示访问链长度。
所以,一般会对这个访问链的长度加以限制,例如,只能进行6次广播,如果查询不到资源即终止。
综上所述,每个节点都能够应该具备下图中的功能。
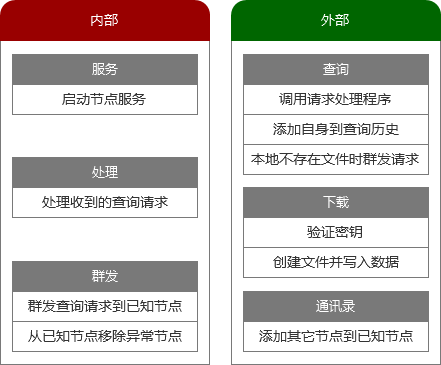
了解了P2P的概念以及文件共享的原理,接下来,我们先尝试创建一个简单的服务器和客户端。
这里需要的是xmlrpc模块。
示例代码:(服务器)
2
3
4
5
6
7
8
9
10
11
12
2'''
3想要学习Python?Python学习交流群:984632579满足你的需求,资料都已经上传群文件,可以自行下载!
4'''
5server = SimpleXMLRPCServer(('', 6666)) # 创建服务器对象
6
7def twice(x): # 定义供客户端调用的函数
8 return 2 * x
9
10server.register_function(twice) # 注册开放给客户端的函数到服务器对象
11server.serve_forever() # 运行服务器
12
示例代码:(客户端)
2
3
4
5
2
3server = ServerProxy('http://219.142.209.7:6666') # 连接服务器,创建服务器代理对象。
4print(server.twice(6)) # 调用服务器提供的函数,显示输出结果为:12
5
先运行服务器,再运行客户端,我们能够看到显示输出的结果。
了解了服务器的创建与访问,接下来我们就完成一个功能相对完整的服务器,并模拟客户端的一些访问请求。
首先,先编写服务器代码。
一、导入模块
实现上述服务器功能,需要用到多个模块。
每个模块的用途请参考代码中的注释。
示例代码:
2
3
4
5
2from xmlrpc.client import ServerProxy # 用于向其它节点发出请求
3from urllib.parse import urlparse # 用于URL解析
4from os.path import join, isfile # 用于路径处理和文件查询
5
二、定义常量
常量和变量一样,用于保存值。
区别在于,变量的值会在程序中发生改变,而常量的值是固定的。
在Python中常量的命名通常是全大写字母的单词。
这里的常量用于访问链长度限制和表示查询状态等。
示例代码:
2
3
4
5
2OK = 1 # 查询状态:正常
3FAIL = 2 # 查询状态:无效
4EMPTY = '' # 空数据
5
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2 def __init__(self, url, dir_name, secret):
3 self.url = url
4 self.dirname = dir_name
5 self.secret = secret
6 self.known = set()
7
8 def _start(self): # 定义启动服务器的内部方法
9 pass
10
11 def _handle(self, filename): # 定义处理请求的内部方法
12 pass
13
14 def _broadcast(self, filename, history): # 定义广播的内部方法
15 pass
16
17 def query(self, filename, history=[]): # 定义接受请求的方法
18 pass
19
20 def hello(self, other): # 定义向添加其它节点到已知节点的方法
21 pass
22
23 def fetch(self, filename, secrt): # 定义下载的方法
24 pass
25
在上方代码中,类的构造函数不但创建了类的变量保存传入的参数,并且创建了一个已知节点的集合(利用了集合可以去重的特点)。
另外,大家要注意内部方法的名称都是单下划线“_”开头,表示受保护的方法,仅限在模块中的内部调用。
还记得双下划线”__”开头的方法吗?表示是类的私有方法,仅限类中可以调用。
其实,不管单下划线还是双下划线开头的方法,如果你非要在外部调用,也是拦不住的……(前面的教程中提到过)
四、定义启动服务器的方法
在创建服务器对象时,我们将Node类的实例注册到服务器对象,这样就不需要为每个方法进行注册。
示例代码:
2
3
4
5
2 server = SimpleXMLRPCServer(('', get_port(self.url)), logRequests=False)
3 server.register_instance(self) # 注册类的实例到服务器对象
4 server.serve_forever()
5
五、定义处理请求的方法
在这个方法中,我们需要通过请求的文件名称和目录路径组成文件路径,通过文件路径检查文件是否存在。
如果文件不存在返回无效的状态和空数据,否则返回正常的状态和读取的文件数据。
示例代码:
2
3
4
5
6
2 file_path = join(self.dirname, filename) # 获取请求路径
3 if not isfile(file_path): # 如果路径不是一个文件
4 return FAIL, EMPTY # 返回无效状态和空数据
5 return OK, open(file_path).read() # 返回正常状态和读取的文件数据
6
六、定义广播请求的方法
广播请求时,需要遍历已知节点,如果节点被访问过,则继续向下一节点发出请求。
如果被请求的节点发生异常,说明该节点失效,将其从已知节点中移除。
如果被请求的节点有效,返回正常的状态和数据。
如果所有已知节点都未能请求到需要的资源,返回无效的状态和空数据。
示例代码:
2
3
4
5
6
7
8
9
10
11
12
13
2 for other in self.known.copy(): # 遍历已知节点的列表
3 if other in history: # 如果已知节点存在于历史记录
4 continue # 继续下一个已知节点信息
5 try:
6 server = ServerProxy(other) # 访问非历史记录中的已知节点
7 state, data = server.query(filename, history) # 向已知节点发出请求
8 if state == OK: # 如果状态为正常
9 return OK, data # 返回有效状态和数据
10 except OSError:
11 self.known.remove(other) # 如果发生异常从已知节点列表中移除节点
12 return FAIL, EMPTY # 返回无效状态和空数据
13
七、定义接收请求的方法
当服务器接收到请求之后,交由内部处理程序进行处理,查询当前节点的资源状态并读取数据。
如果获取到正常状态,返回状态和数据;否则,向所有已知节点广播请求。
这里要注意,在广播请求之前,要把当前节点的URL存放在历史记录列表中,这样能够避免对当前节点的重复请求,并形成访问链;并且,每一层接收请求处理过后,如果没有获取到资源,也都要将当前节点的URL在再次广播请求前存入历史记录列表。
当访问链长度(即历史记录数量)大于等于限定长度时,要返回无效的状态和空数据,不再广播请求。
示例代码:
2
3
4
5
6
7
8
9
10
2 state, data = self._handle(filename) # 获取处理请求的结果
3 if state == OK: # 如果是正常状态
4 return state, data # 返回状态和数据
5 else: # 否则
6 history.append(self.url) # 历史记录添加已请求过的节点
7 if len(history) >= MAX_HISTORY_LENGTH: # 如果历史请求超过6次
8 return FAIL, EMPTY # 返回无效状态和空数据
9 return self._broadcast(filename, history) # 返回广播结果
10
八、定义向添加其它节点到已知节点的方法
这个方法比较简单,只需要将其他节点的URL添加到已知节点。
示例代码:
不过要注意,服务器中的每个方法都必须有返回值,否则,会发生错误。错误提示为:“annot marshal None unless allow_none is enabled”,意思是不能返回None值,除非参数allow_none(允许为空)为启用。这个参数allow_none是指ServerProxy类进行实例化时的参数之一。
2
3
4
2 self.known.add(other) # 添加其它节点到已知节点
3 return OK # 返回值是必须的
4
九、定义下载的方法
为了避免通过未经许可的渠道获取资源,我们需要在实例化节点时设定密钥,并在下载节点资源时验证密钥。
当密钥验证成功,我们通过接收请求的方法进行请求处理,获取到资源状态和读取的数据。
当资源状态正常时,进行文件的创建,将读取到的数据写入到文件中。
示例代码:
2
3
4
5
6
7
8
9
10
11
2 if secrt != self.secret: # 如果密钥不匹配
3 return FAIL, EMPTY # 返回无效状态和空数据
4 state, data = self.query(filename) # 处理请求获取文件状态与与数据
5 if state == OK: # 如果返回正常的状态
6 with open(join(self.dirname, filename), 'w') as file: # 写入模式打开文件
7 file.write(data) # 将获取到的数据写入文件
8 return OK # 返回值是必须的
9 else:
10 return FAIL # 返回值是必须的
11
十、启动服务器
最后,我们编写启动服务器的代码。
示例代码:
2
3
4
5
6
7
2 url = 'http://127.0.0.1:6666'
3 directory = 'NodeFiles01'
4 secret = '123456'
5 node = Node(url, directory, secret)
6 node._start()
7
接下来,编写客户端代码。
一、发出请求
在客户端中发出请求,我们需要准备请求的文件名称和正确的密钥。
然后,通过ServerProxy类创建服务器代理对象,调用接收请求的方法。
示例代码:
2
3
4
5
6
7
8
9
10
11
12
2
3filename = 'file.txt' # 请求的资源文件名称
4
5url1 = 'http://127.0.0.1:7777' # 请求的服务器URL
6peer1 = ServerProxy(url1) # 创建服务器代理对象
7print(peer1.query(filename)) # 调用服务器的接收请求方法
8
9url2 = 'http://127.0.0.1:6666'
10peer2 = ServerProxy(url2)
11print(peer2.query(filename))
12
进行这一步测试时,大家需要先启动多个服务器。
如果是本机测试,这些服务器要有不同的端口、目录名称以及密钥,并且在部分目录中放入被请求的文件。
例如:
Node(‘http://127.0.0.1:6666’, ‘NodeFiles01’, ‘123456’) # 目录中有文件“file.txt”
Node(‘http://127.0.0.1:7777’, ‘NodeFiles02’, ‘654321’)
当我们运行上方客户端代码时,我们会看到结果:
[2, ”]
[1, ‘这是一个用于下载测试的文件!’]
二、添加节点到已知节点
我们将存在被请求文件的节点URL添加到已知节点。
示例代码:
2
3
2print(peer1.query(filename))
3
运行上方代码,显示结果为:
[2, ”]
[1, ‘这是一个用于下载测试的文件!’]
[1, ‘这是一个用于下载测试的文件!’]
三、下载文件
下载文件只需要添加一句代码,对用服务器代理对象的fetch()方法。
因为在上一段代码中,我们已经将存有请求文件的节点添加到了peer1的已知节点中,所以peer1节点能够完成文件下载。
示例代码:
2
2
