引言
按照Kafka默认的消费逻辑设定,一个分区只能被同一个消费组(ConsumerGroup)内的一个消费者消费。假设目前某消费组内只有一个消费者C0,订阅了一个topic,这个topic包含7个分区,也就是说这个消费者C0订阅了7个分区,参考下图(1)。
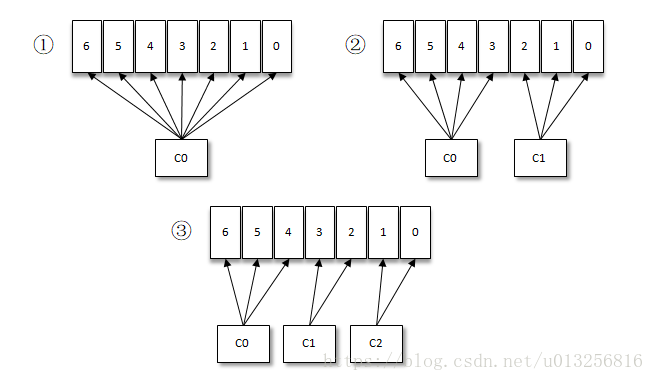
此时消费组内又加入了一个新的消费者C1,按照既定的逻辑需要将原来消费者C0的部分分区分配给消费者C1消费,情形上图(2),消费者C0和C1各自负责消费所分配到的分区,相互之间并无实质性的干扰。
接着消费组内又加入了一个新的消费者C2,如此消费者C0、C1和C2按照上图(3)中的方式各自负责消费所分配到的分区。
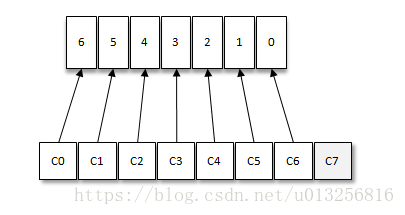
如果消费者过多,出现了消费者的数量大于分区的数量的情况,就会有消费者分配不到任何分区。参考下图,一共有8个消费者,7个分区,那么最后的消费者C7由于分配不到任何分区进而就无法消费任何消息。
上面各个示例中的整套逻辑是按照Kafka中默认的分区分配策略来实施的。Kafka提供了消费者客户端参数partition.assignment.strategy用来设置消费者与订阅主题之间的分区分配策略。默认情况下,此参数的值为:org.apache.kafka.clients.consumer.RangeAssignor,即采用RangeAssignor分配策略。除此之外,Kafka中还提供了另外两种分配策略: RoundRobinAssignor和StickyAssignor。消费者客户端参数partition.asssignment.strategy可以配置多个分配策略,彼此之间以逗号分隔。
RangeAssignor分配策略
RangeAssignor策略的原理是按照消费者总数和分区总数进行整除运算来获得一个跨度,然后将分区按照跨度进行平均分配,以保证分区尽可能均匀地分配给所有的消费者。对于每一个topic,RangeAssignor策略会将消费组内所有订阅这个topic的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
假设n=分区数/消费者数量,m=分区数%消费者数量,那么前m个消费者每个分配n+1个分区,后面的(消费者数量-m)个消费者每个分配n个分区。
为了更加通俗的讲解RangeAssignor策略,我们不妨再举一些示例。假设消费组内有2个消费者C0和C1,都订阅了主题t0和t1,并且每个主题都有4个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t0p3、t1p0、t1p1、t1p2、t1p3。最终的分配结果为:
2
3
4
2消费者C1:t0p2、t0p3、t1p2、t1p3
3
4
这样分配的很均匀,那么此种分配策略能够一直保持这种良好的特性呢?我们再来看下另外一种情况。假设上面例子中2个主题都只有3个分区,那么所订阅的所有分区可以标识为:t0p0、t0p1、t0p2、t1p0、t1p1、t1p2。最终的分配结果为:
2
3
4
2消费者C1:t0p2、t1p2
3
4
可以明显的看到这样的分配并不均匀,如果将类似的情形扩大,有可能会出现部分消费者过载的情况。对此我们再来看下另一种RoundRobinAssignor策略的分配效果如何。
