文章目录
-
一丶冯诺依曼体系架构
* 二丶文件常用IO操作 -
1.open打开文件
* 2.文件指针
* 3.read、readline、readlines
* 4.write、writelines
* 5.close1
21 * 三丶StringIO和BytesIO
2 -
1.StringIO
* 2.BytesIO
* 3.file-like对象
任何程序都需要处理输入和输出,一般说IO操作指的是文件IO,如果指的是网络IO,直接描述成网络IO
一丶冯诺依曼体系架构
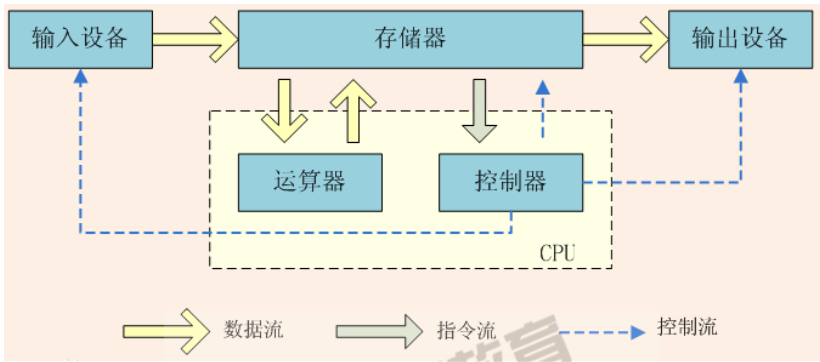
-
cpu有运算器和控制器组成
-
运算器,完成各中算数运算、逻辑运算、数据传输等数据加工处理
- 控制器,控制计算机各部件协调运行
- 存储器,用于记忆程序和数据,例如内存
- 输入设备,将数据或者程序输入到计算机中,例如键盘、鼠标
- 输出设备,将数据或者程序的处理结果展示给用户,例如显示器、打印机等
磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以读写文件就是操作系统打开一个文件对象(通常称为文件描述符),让后通过操作系统提供的接口从这个文件对象中读取数据(读文件),或者把数据写入这个文件对象。
二丶文件常用IO操作
read
读取
write
写入
close
关闭
readline
行读取
readlines
多行读取
seek
文件指针操作
tell
指针位置
1.open打开文件
open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
打开文件,返回一个文件对象(流对象)和文件描述符,如果改文件不能打开,则出发OSError。
基本使用:
2
3
4
5
6
7
2# windows <_io.TextIOWrapper name='test' mode='r' encoding='cp936'>
3# linux <_io.TextIOWrapper name='test' mode='r' encoding='UTF-8'>
4print(f.read()) # 读取文件
5f.close() # 关闭文件
6
7
文件操作中,最常用的操作是读和写。
文件访问的模式有两种:二进制模式和文本模式。
open的参数比较多,下面逐个分析:
file
file 是一个 path-like object,表示将要打开的文件的路径(绝对路径或者当前工作目录的相对路径),也可以是要被封装的整数类型文件描述符。(如果是文件描述符,它会随着返回的 I/O 对象关闭而关闭,除非 closefd 被设为 False )
mode
mode是一个可选字符串,用于指定打开文件的模式,默认值是’ r ',表示他以文本模式打开并读取
r
以只读模式打开文件,不可写,文件的指针放在文件的开头
w
以只写模式打开文件,不可读,如果改文件已存在则打开文件,原有的内容会被删除,从头开始编辑。如果改文件不存在则创建新文件
x
创建并写入一个新文件,不可读。如果文件已存在,则报FileExistsError
a
以追加写入模式打开文件,不可读,如果文件已存在则打开文件,指针放在文件的结尾EOF处,新的内容将被写到已有内容之后,,如果改文件不存在,则创建新文件写入
b
二进制模式,字节流,将文件就按照字节理解,二进制模式操作室,字节操作使用bytes字节串、bytearray对象等
t
文本模式,将文件的字节按照某种字符编码理解,按照字符操作。 这是默认模式
+
读写打开一个文件,给原来只读、只写模式打开提供缺失的读或者写能力,但是获取文件对象依旧按照r、w、a、x自己的特征,不能单独使用。仔细体会
注意+模式:
"a+"模式,即使seek(0),写入内容依然是在尾部追加,小心。其余模式使用带有+的增强模式时,如果想移动完指针再进行写操作,最好先测试是以怎样的覆盖进行写操作
buffering
buffering是用一个可选的整数,用于设置缓冲策略
- -1 表示使用缺省大小的buffering
如果是二进制模式,使缺省值,默认是4096或者8192也就是4kib或者8kib,
如果是文本模式,如果是终端设备,默认使用行缓冲
如果不是,使用二进制模式的策略
使用io.DEFAULT_BUFFER_SIZE查看缺省值大小
2
3
4
5
6
7
2
3In [2]: io.DEFAULT_BUFFER_SIZE
4Out[2]: 8192
5
6
7
- 0 表示只有在二进制模式下还使用,表示关闭buffering,文本模式不支持会报错
- 1 只有在文本模式下使用,表示行缓存模式,意思就是见到换行符就flush,上限是缓冲区大小就flush(),如果下一次数据中间出现一个换行符,无视换行符位置,直接全部写入
需要小心的是:二进制模式下的1还是默认的达到缓冲区阈值才会写入
- 大于1的情况,也适用于二进制模式;文本模式没用还是会采用默认缓冲区的大小
缓冲区一个内存空间,一般来说是一个FIFO队列,到缓冲区满了或者达到阈值,数据才会flush到磁盘
文本模式一般默认缓冲区大小
二进制模式时一个个字节的操作.可以指定buffer的大小
一般来说默认缓冲区大小是个比较好的选择,除非明确知道,否则不用调整它
一般编程中,明确知道需要写磁盘了,都会手动调用一次flush操作,而不是自动等它flush()
encoding
是用于解码或者编码文件的编码的名称,仅文本模式使用
None表示使用缺省编码,依赖操作系统
Windows下缺省GBK(0xBOA1),Linux下默认UTF-8
errors
是一个可选的字符串参数,用于指定如何处理编码和解码,仅适用于文本模式,用的不多
- ‘ignore’ 忽略错误。请注意,忽略编码错误可能会导致数据丢失。
- ‘replace’ 会将替换标记(例如 ‘?’ )插入有错误数据的地方。
- ‘surrogateescape’ 将表示任何不正确的字节作为Unicode专用区中的代码点,范围从U+DC80到U+DCFF。当在写入数据时使用 surrogateescape 错误处理程序时,这些私有代码点将被转回到相同的字节中。这对于处理未知编码的文件很有用。
更多请参考官方文档,后面爬虫的时候这个参数用的多点…
newline
让我疑惑半天的参数,这里我要详细的说下,如果还是不懂结合notepad++仔细理解
不同操作系统系统换行符不统一,linux:\n, windows:’\r\n’, mac: '\r’
文本模式中: newline的值可以为None、’’ 空串、’\r’、’\n’、’\r\n’
- 写的时候,None表示"\n"都会被替换成系统却省行分隔符os.linesp(也就是系统换行符):
newline = “\n"或者”",表示"\n"不替换
其他合法字符"\n"会替换成指定的字符
- 读的时候,None表示"\n","\r","\r\n"都被转换成"\n",并以它为分隔符
newline="" 表示不会自动转换通用换行符,该是啥还是啥,显示多少行,就分多少行
其他合法字符表示换行符就是指定字符,就会按照指定字符分行
二进制模式下写入没问题,二进制读写没有newline参数,读的时候默认以\n作为换行符
closefd
关闭文件描述符,True表示关闭它。False会在文件关闭后保持这个描述符。
fileobj.fileno()查看
2.文件指针
文件指针指向当前字节位置
seek(offset[, whence])
- offset为+表示向右偏移,为-则相反,为0则表示偏移量为0
- whence为0,表示指针移动到头部,whence为1,表示指针移动到当前位置,whence为2,表示指针移动到末尾EOF处
①文本模式下:
文本模式支持从开头像后偏移的方式
whence为1或者2的时候,不支持偏移,向右偏移可以"越界"
②二进制模式下
可以任意位置偏移,但是不可以像做偏移越界,向右没事
查看指针位置
2
3
4
5
6
2f.tell()
3
40
5
6
3.read、readline、readlines
- read(size=-1)
这将读取一定数目的数据,然后作为字符串或者字节对象返回。
size是一个可选的数字类型的参数,默认为-1表示全部读取。
2
3
4
5
6
7
8
9
10
2f.write('aaaa\rbbbb\rcccc\r\ndddd')
3f.seek(0)
4f.read()
5
6'aaaa\nbbbb\ncccc\n\ndddd' # 结果你可能不理解,这就是newline的作用
7
8f.close()
9
10
- readline(size=-1)
表示一行行读取文件内容,换行符为’\n’
size设置一次能读取几个字符或字节
- readines(hint=-1)
返回文件中包含的所有航的列表
hint返回指定的行数
另一种更好的方式是迭代一个文件对象然后读取每行
2
3
4
5
6
7
8
9
10
11
12
2for line in f:
3 print(line,end="")
4
5aaaa
6bbbb
7cccc
8dddd
9
10f.close()
11
12
调用read()会一次性读取文件的全部内容,如果文件有10G,内存就报了,所以,要保险起见,可以反复调用read(size)方法,每次最多读取size的字节的内容。另外调用readline每次读取一行内容,readlines一次性读取所有内容并返回list,要根据需求决定怎么调用。
如果文件很小,read()一次性读取最方便;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便
2
3
4
2 print(line.strip()) # 把末尾的'\n'删掉
3
4
4.write、writelines
-
f.write(string)将string写入文件中,饭后返回写入字符的数
-
f.writelines(lines)将字符串列表写入文件
2
3
4
5
6
7
8
9
10
11
2
3lines = ['abc', '123\n', 'magedu'] # 提供换行符
4f.writelines(lines)
5
6f.seek(0)
7print(f.read())
8f.close()
9
10
11
5.close
flush()并关闭文件对象
文件已经关闭,再次关闭没有任何效果
由于文件读写时都可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确的关闭文件, 我们可以使用try…finally来实现:
2
3
4
5
6
7
8
2 f = open('somefile', 'r')
3 print(f.read())
4finally:
5 if f:
6 f.close()
7
8
但是每次都这么写是在太繁琐,所以python’引入了with语句来帮我们调用close()方法:
2
3
4
2 print(f.read())
3
4
三丶StringIO和BytesIO
1.StringIO
很多时候,数据读写不一定是文件,也可以在内存中读写。
StringIO顾名思义就是在内存中开辟的一个文本模式的buffer,可以向文件对象一样操作它。
当close方法被调用的时候,这个buffer会被释放。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3In [2]: f = StringIO() # 可以向文件一样操作
4
5In [4]: f.readable(), f.writable(), f.seekable()
6Out[4]: (True, True, True)
7
8In [5]: f.write("hello StringIO")
9Out[5]: 14
10
11In [6]: f.seek(0)
12Out[6]: 0
13
14In [7]: f.read()
15Out[7]: 'hello StringIO'
16
17In [8]: f.getvalue() # 无视指针
18Out[8]: 'hello StringIO'
19
20In [9]: f.close()
21
22
23
getvalue()方法用于获取写入的string,无视指针
2.BytesIO
StringIO的操作只能是str,如果要操作二进制数据,就需要使用BytesIO。
内存中开辟的一个二进制模式的buffer,可以向文件对象一样操作它。
当close方法被调用的时候买这个buffer也会被释放。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3In [10]: f = BytesIO()
4
5In [11]: f.readable(),f.writable(), f.seekable()
6Out[11]: (True, True, True)
7
8In [12]: f.write("python之禅".encode()) # 写入的不是str,而是经过utf-8编码的bytes
9Out[12]: 12
10
11In [13]: f.getvalue() # 无视指针位置
12Out[13]: b'python\xe4\xb9\x8b\xe7\xa6\x85'
13
14In [14]: f.close()
15
16
优点:
一般来说,磁盘的操作比内存的操作要慢的多,内存足够的情况下,一般的优化思路是少落地,减少磁盘IO的过程,可以大大提高程序的运行效率。
StringIO和BytesIO和读写文件具有一致的接口。
应用场景:有时需要对获取到的数据进行操作,但是可能并不像把数据写到本地硬盘上,这时候可能用到StringIO(obj)
3.file-like对象
-
类文件对象,可以向文件对象一样操作
-
socket对象,输入、输出对象(stdin、stdout)都是类文件对象
2
3
4
5
6
7
8
9
10
11
12
13
2
3In [16]: from sys import stderr
4
5In [17]: f = stdout
6
7In [18]: print(type(f))
8<class 'ipykernel.iostream.OutStream'>
9
10In [19]: f.write("file-like")
11file-like
12
13
