5. 计算资源相关创建问题分析
(1)Pod状态为Pending,错误信息为FailedScheduling。如果Kubernetes调度器在集群中找不到合适的节点来运行Pod,那么这个Pod会一直处于未调度状态,直到调度器找到合适的节点为止。每次调度器尝试调度失败时,Kubernetes都会产生一个事件,我们可以通过下面这种方式来查看事件的信息
2
2
Pod由于节点的CPU资源不足会调度失败(Pod ExceedsFreeCPU),同样,如果内存不足,则也可能导致调度失败(PodExceedsFreeMemory)。
如果一个或者多个Pod调度失败且有这类错误,那么可以尝试以下几种解决方法。
◎ 添加更多的节点到集群中。
◎ 停止一些不必要的运行中的Pod,释放资源。
◎ 检查Pod的配置,错误的配置可能导致该Pod永远无法被调度执行。比如整个集群中所有节点都只有1 CPU,而Pod配置的CPU Requests为2,该Pod就不会被调度执行。
我们可以使用kubectl describe nodes命令来查看集群中节点的计算资源容量和已使用量:
2
2
超过可用资源容量上限(Capacity)和已分配资源量(Allocated resources)差额的Pod无法运行在该Node上。我们还可以配置针对一组Pod的Requests和Limits总量的限制,这种限制可以作用于命名空间,通过这种方式可以防止一个命名空间下的用户将所有资源据为己有。
(2)容器被强行终止(Terminated)。如果容器使用的资源超过了它配置的Limits,那么该容器可能会被强制终止。我们可以通过kubectl describe pod命令来确认容器是否因为这个原因被终止:
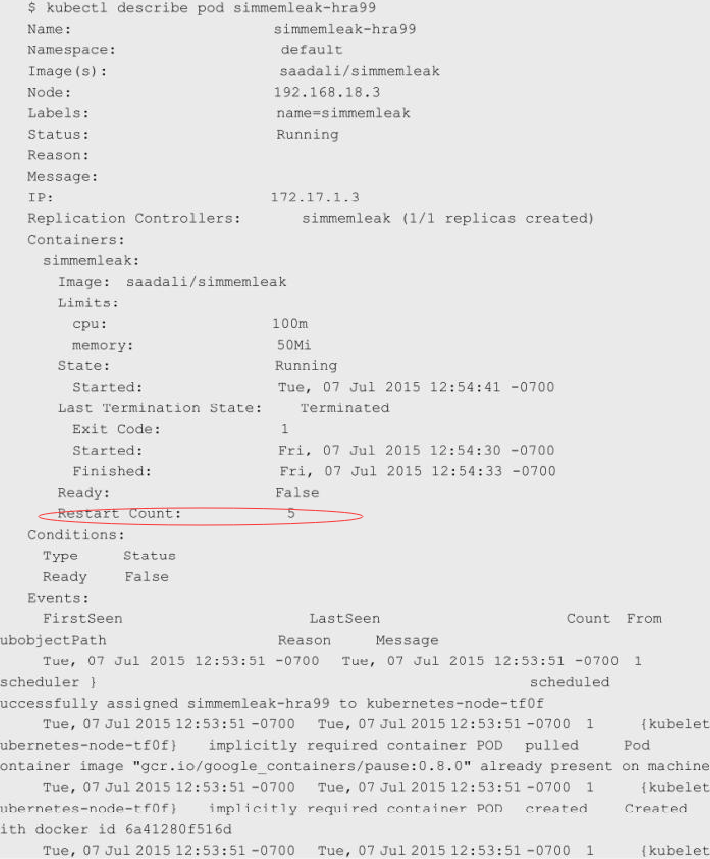
Restart Count: 5说明这个名为simmemleak的容器被强制终止并重启了5次。
我们可以在使用kubectl get pod命令时添加-o go-template=…格式参数来读取已终止容器之前的状态信息:
2
2
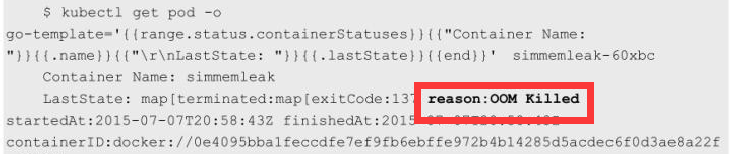
可以看到这个容器因为reason:OOM Killed而被强制终止,说明这个容器的内存超过了限制(Out of Memory)
6.对大内存页(Huge Page)资源的支持
在计算机发展的早期阶段,程序员是直接对内存物理地址编程的,并且需要自己管理内存,很容易由于内存地址错误导致操作系统崩溃,而且出现了一些恶意程序对操作系统进行破坏。后来人们将硬件和软件(操作系统)相结合,推出了虚拟地址的概念,同时推出了内存页的概念,以及CPU的逻辑内存地址与物理内存(条)地址的映射关系。
在现代操作系统中,内存是以Page(页,有时也可以称之为Block)为单位进行管理的,而不以字节为单位,包括内存的分配和回收都基于Page。典型的Page大小为4KB,因此用户进程申请1MB内存就需要操作系统分配256个Page,而1GB内存对应26万多个Page!
为了实现快速内存寻址,CPU内部以硬件方式实现了一个高性能的内存地址映射的缓存表——TLB(Translation Lookaside Buffer),用来保存逻辑内存地址与物理内存的对应关系。若目标地址的内存页物理地址不在TLB的缓存中或者TLB中的缓存记录失效,CPU就需要切换到低速的、以软件方式实现的内存地址映射表进行内存寻址,这将大大降低CPU的运算速度。针对缓存条目有限的TLB缓存表,提高TLB效率的最佳办法就是将内存页增大,这样一来,一个进程所需的内存页数量会相应减少很多。如果把内存页从默认的4KB改为2MB,那么1GB内存就只对应512个内存页了,TLB的缓存命中率会大大增加。这是不是意味着我们可以任意指定内存页的大小,比如1314MB的内存页?答案是否定的,因为这是由CPU来决定的,比如常见的Intel X86处理器可以支持的大内存页通常是2MB,个别型号的高端处理器则支持1GB的大内存页。
在Linux平台下,对于那些需要大量内存(1GB以上内存)的程序来说,大内存页的优势是很明显的,因为Huge Page大大提升了TLB的缓存命中率,又因为Linux对Huge Page提供了更为简单、便捷的操作接口,所以可以把它当作文件来进行读写操作。Linux使用Huge Page文件系统hugetlbfs支持巨页,这种方式更为灵活,我们可以设置Huge Page的大小,比如1GB、2GB甚至2.5GB,然后设置有多少物理内存用于分配Huge Page,这样就设置了一些预先分配好的Huge Page。可以将hugetlbfs文件系统挂载在/mnt/huge目录下,通过执行下面的指令完成设置:
2
3
2mount -t hugetlbfs nodev /mnt/huge
3
在设置完成后,用户进程就可以使用mmap映射Huge Page目标文件来使用大内存页了,Intel DPDK便采用了这种做法,测试表明应用使用大内存页比使用4KB的内存页性能提高了10%~15%。
Kubernetes 1.14版本对Linux Huge Page的支持正式更新为GA稳定版。我们可以将Huge Page理解为一种特殊的计算资源:拥有大内存页的资源。而拥有Huge Page资源的Node也与拥有GPU资源的Node一样,属于一种新的可调度资源节点(Schedulable Resource Node)
Huge Page也支持ResourceQuota来实现配额限制,类似CPU或者Memory,但不同于CPU或者内存,Huge Page资源属于不可超限使用的资源,拥有Huge Page能力的Node会将自身支持的Huge Page的能力信息自动上报给Kubernetes Master。
为此,Kubernetes引入了一个新的资源类型hugepages-<size>,来表示大内存页这种特殊的资源,比如hugepages-2Mi表示2MiB规格的大内存页资源。一个能提供2MiB规格Huge Page的Node,会上报自己拥有Hugepages-2Mi的大内存页资源属性,供需要这种规格的大内存页资源的Pod使用,而需要Huge Page资源的Pod只要给出相关的Huge Page的声明,就可以被正确调度到匹配的目标Node上了。相关例子如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2kind: Pod
3metadata:
4 generateName: hugepages-volume
5spec:
6 containers:
7 - image: fedora: latest
8 command:
9 - sleep
10 - inf
11 name: example
12 volumeMounts:
13 - mountPath: /hugepages
14 name: hugepage
15 resources:
16 limits:
17 hugepages-2Mi: 100Mi
18 memory: 100Mi
19 requests:
20 memory: 100Mi
21 volumes:
22 - name: hugepage
23 emptyDir:
24 mediym: HigePages
25
在上面的定义中有以下几个关键点:
◎ Huge Page需要被映射到Pod的文件系统中;
◎ Huge Page申请的request与limit必须相同,即申请固定大小的Huge Page,不能是可变的;
◎ 在目前的版本中,Huge Page属于Pod级别的资源,未来计划成为Container级别的资源,即实现更细粒度的资源管理;
◎ 存储卷emptyDir(挂载到容器内的/hugepages目录)的后台是由Huge Page支持的,因此应用不能使用超过request声明的内存大小。
在Kubernetes未来的版本中,计划继续实现下面的一些高级特性:
◎ 支持容器级别的Huge Page的隔离能力;
◎ 支持NUMA亲和能力以提升服务的质量;
◎ 支持LimitRange配置Huge Page资源限额。
资源配置范围管理(LimitRange)
在默认情况下,Kubernetes不会对Pod加上CPU和内存限制,这意味着Kubernetes系统中任何Pod都可以使用其所在节点的所有可用的CPU和内存。通过配置Pod的计算资源Requests和Limits,我们可以限制Pod的资源使用,但对于Kubernetes集群管理员而言,配置每一个Pod的Requests和Limits是烦琐的,而且很受限制。更多时候,我们需要对集群内Requests和Limits的配置做一个全局限制。常见的配置场景如下。
◎ 集群中的每个节点都有2GB内存,集群管理员不希望任何Pod申请超过2GB的内存:因为在整个集群中都没有任何节点能满足超过2GB内存的请求。如果某个Pod的内存配置超过2GB,那么该Pod将永远都无法被调度到任何节点上执行。为了防止这种情况的发生,集群管理员希望能在系统管理功能中设置禁止Pod申请超过2GB内存。
◎ 集群由同一个组织中的两个团队共享,分别运行生产环境和开发环境。生产环境最多可以使用8GB内存,而开发环境最多可以使用512MB内存。集群管理员希望通过为这两个环境创建不同的命名空间,并为每个命名空间设置不同的限制来满足这个需求。
◎ 用户创建Pod时使用的资源可能会刚好比整个机器资源的上限稍小,而恰好剩下的资源大小非常尴尬:不足以运行其他任务但整个集群加起来又非常浪费。因此,集群管理员希望设置每个Pod都必须至少使用集群平均资源值(CPU和内存)的20%,这样集群能够提供更好的资源一致性的调度,从而减少了资源浪费。
针对这些需求,Kubernetes提供了LimitRange机制对Pod和容器的Requests和Limits配置进一步做出限制。在下面的示例中,将说明如何将LimitsRange应用到一个Kubernetes的命名空间中,然后说明LimitRange的几种限制方式,比如最大及最小范围、Requests和Limits的默认值、Limits与Requests的最大比例上限等。
下面通过LimitRange的设置和应用对其进行说明。
1.创建一个Namespace
2
2
2.为Namespace设置LimitRange
为Namespace“limit-example”创建一个简单的LimitRange。创建limits.yaml配置文件,内容如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2kind: LimitRange
3metadata:
4 name: mylimits
5spec:
6 limits:
7 - max:
8 cpu: "4"
9 memory: 2Gi
10 min:
11 cpu: 200m
12 memory: 6Mi
13 maxLimitRequestRatio:
14 cpu: 3
15 memory: 2
16 type: Pod
17 - default:
18 cpu: 300m
19 memory: 200Mi
20 defaultRequest:
21 cpu: 200m
22 memory: 100Mi
23 max:
24 cpu: "2"
25 memory: 1Gi
26 min:
27 cpu: 100m
28 memory: 3Mi
29 maxLimitRequestRatio:
30 cpu: 5
31 memory: 4
32 type: Container
33
2
2
查看namespace limit-example中的LimitRange:
2
2
下面解释LimitRange中各项配置的意义和特点。
(1)不论是CPU还是内存,在LimitRange中,Pod和Container都可以设置Min、Max和Max Limit/Requests Ratio参数。Container还可以设置Default Request和Default Limit参数,而Pod不能设置Default Request和Default Limit参数。
(2)对Pod和Container的参数解释如下。
◎ Container的Min(上面的100m和3Mi)是Pod中所有容器的Requests值下限;Container的Max(上面的2和1Gi)是Pod中所有容器的Limits值上限;Container的Default Request(上面的200m和100Mi)是Pod中所有未指定Requests值的容器的默认Requests值;Container的Default Limit(上面的300m和200Mi)是Pod中所有未指定Limits值的容器的默认Limits值。对于同一资源类型,这4个参数必须满足以下关系:Min ≤ Default Request ≤ Default Limit ≤ Max。
◎ Pod的Min(上面的200m和6Mi)是Pod中所有容器的Requests值的总和下限;Pod的Max(上面的4和2Gi)是Pod中所有容器的Limits值的总和上限。当容器未指定Requests值或者Limits值时,将使用Container的Default Request值或者Default Limit值。
◎ Container的Max Limit/Requests Ratio(上面的5和4)限制了Pod中所有容器的Limits值与Requests值的比例上限;而Pod的Max Limit/Requests Ratio(上面的3和2)限制了Pod中所有容器的Limits值总和与Requests值总和的比例上限。
(3)如果设置了Container的Max,那么对于该类资源而言,整个集群中的所有容器都必须设置Limits,否则无法成功创建。Pod内的容器未配置Limits时,将使用Default Limit的值(本例中的300m CPU和200MiB内存),如果也未配置Default,则无法成功创建。
(4)如果设置了Container的Min,那么对于该类资源而言,整个集群中的所有容器都必须设置Requests。如果创建Pod的容器时未配置该类资源的Requests,那么在创建过程中会报验证错误。Pod里容器的Requests在未配置时,可以使用默认值defaultRequest(本例中的200m CPU和100MiB内存);如果未配置而又没有使用默认值defaultRequest,那么会默认等于该容器的Limits;如果此时Limits也未定义,就会报错。
(5)对于任意一个Pod而言,该Pod中所有容器的Requests总和必须大于或等于6MiB,而且所有容器的Limits总和必须小于或等于1GiB;同样,所有容器的CPU Requests总和必须大于或等于200m,而且所有容器的CPU Limits总和必须小于或等于2。
(6)Pod里任何容器的Limits与Requests的比例都不能超过Container的Max Limit/Requests Ratio;Pod里所有容器的Limits总和与Requests的总和的比例不能超过Pod的Max Limit/Requests Ratio。
3.创建Pod时触发LimitRange限制
最后,让我们看看LimitRange生效时对容器的资源限制效果。
命名空间中LimitRange只会在Pod创建或者更新时执行检查。如果手动修改LimitRange为一个新的值,那么这个新的值不会去检查或限制之前已经在该命名空间中创建好的Pod。
如果在创建Pod时配置的资源值(CPU或者内存)超过了LimitRange的限制,那么该创建过程会报错,在错误信息中会说明详细的错误原因。
下面通过创建一个单容器Pod来展示默认限制是如何被配置到Pod上的:
2
2
查看已创建Pod的resourecs相关信息
2
2
由于该Pod未配置资源Requests和Limits,所以使用了namespace limit-example中的默认CPU和内存定义的Requests和Limits值。
下面创建一个超出资源限制的Pod(使用3CPU):
2
3
4
5
6
7
8
9
10
11
12
13
14
2apiVersion: v1
3kind: Pod
4metadata:
5 name: invalid-pod
6spec:
7 containers:
8 - name: kubernetes-serve-hostname
9 image: gcr.io/google_containers/server_hostname
10 resources:
11 limits:
12 cpu: "3"
13 memory: 100Mi
14
创建该Pod,可以看到系统报错了,并且提供的错误原因为超过资源限制:
2
2
接下来的例子展示了LimitRange对maxLimitRequestRatio的限制过程:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2kind: Pod
3metadata:
4 name: limit-test-nginx
5 labels:
6 name: limit-test-nginx
7spec:
8 containers:
9 - name: limit-test-nginx
10 image: nginx
11 resources:
12 limits:
13 cpu: "1"
14 memory: 512Mi
15 requests:
16 cpu: "0.8"
17 memory: 250Mi
18
由于limit-test-nginx这个Pod的全部内存Limits总和与Requests总和的比例为512∶250,大于在LimitRange中定义的Pod的最大比率2(maxLimitRequestRatio.memory=2),因此会创建失败。
下面的例子为满足LimitRange限制的Pod:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2kind: Pod
3metadata:
4 name: valid-pod
5 labels:
6 name: valid-pod
7spec:
8 containers:
9 - name: kubernetes-serve-hostname
10 image: gcr.io/google_containers/serve_hostname
11 resources:
12 limits:
13 cpu: "1"
14 memory: 512Mi
15
创建Pod将会成功,查看该Pod的资源信息:
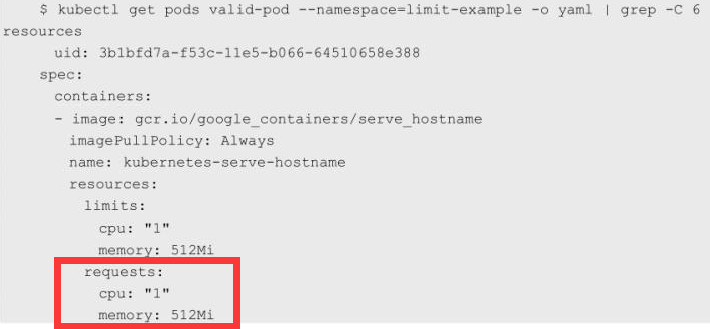
可以看到该Pod配置了明确的Limits和Requests,因此该Pod不会使用在namespace limit-example中定义的default和defaultRequest。
需要注意的是,CPU Limits强制配置这个选项在Kubernetes集群中默认是开启的;除非集群管理员在部署kubelet时,通过设置参数–cpu-cfs-quota=false来关闭该限制。
如果集群管理员希望对整个集群中容器或者Pod配置的Requests和Limits做限制,那么可以通过配置Kubernetes命名空间中的LimitRange来达到该目的。在Kubernetes集群中,如果Pod没有显式定义Limits和Requests,那么Kubernetes系统会将该Pod所在的命名空间中定义的LimitRange的default和defaultRequests配置到该Pod上。
小结:
本节内容到此结束,明天继续为大家带来资源管理方面的内容。
see you!
