一、进程创建概述
-
**其他的操作系统产生进程的机制:**许多其他的操作系统都提供了产生(spawn) 进程的机制,首先在新的地址空间里创建进程,读入可执行文件,最后开始执行
-
**Unix创建进程的机制:**它把上述步骤分解到两个单独的函数中去执行:fork()、exec()
-
1.首先,fork()通过拷贝当前进程创建一个子进程。子进程与父进程的区别仅仅在于PID (每个进程唯一) 、PPID (父进程的进程号,子进程将其设置为被拷贝进程的PID)和某些资源和统计量(例如,挂起的信号,它没有必要被继 )
- 2.exec()函数负责读取可执行文件并将其载入地址空间幵始运行。把这两个函数组合起来使用的效果跟其他系统使用的单一函数的效果相似
二、进程创建之写时拷贝
- **传统的的fork:**传统的fork()系统调用直接把所有的资源复制给新创建的进程。这种实现过于简单并且效率低下,因为它拷贝的数据也许并不共享,更糟的情况是,如果新进程打算立即执行一个新的映像 ,那么所有的拷贝都将前功尽弃
- Linux的fork:Linux的fork使用写时拷贝(copy-on-write)页实现。写时拷贝是一种可以推迟甚至免除拷贝数据的技术。内核此时并不复制整个进程地址空间,而是让父进程和子进程共享同一个拷贝
写时拷贝
- 只有在需要写入的时候(父进程写或者子进程写),数据才会被复制,从而使各个进程拥有各自的拷贝。也就是说,资源的复制只有在需要写入的时候才进行,在此之前,
只是以只读方式共享。这种技术使地址空间上的页的拷贝被推迟到实际发生写入的时候才进行。在页根本不会被写入的情况下(举例来说,fork()后立即调用exec())它们就无须复制了
- fork()的实际开销就是复制父进程的页表以及给子进程创建唯一的进程描述符。在一般情况下,进程创建后都会马上运行一个可执行的文件,这种优化
可以避免拷贝大量根本就不会被使用的数据(地址空间里常常包含数十兆的数据)。由于Unix强调进程快速执行的能力,所以这个优化是很重要的
三、进程创建之fork
-
fork创建进程的函数调用流程:
-
fork()、vfork()、__clone()库函数都根据各自需要的参数标志去调用
clone()
* clone()调用通过一系列的参数标志来指明父、子进程需要共享的资源,然后由clone()去调用
do_fork()
* do_fork()完成了创建中的大部分工作,它的定义在kernel/fork.c文件中。该函数
**调用copy_process()**函数
clone()
普通的fork调用的clone()如下:
2
2
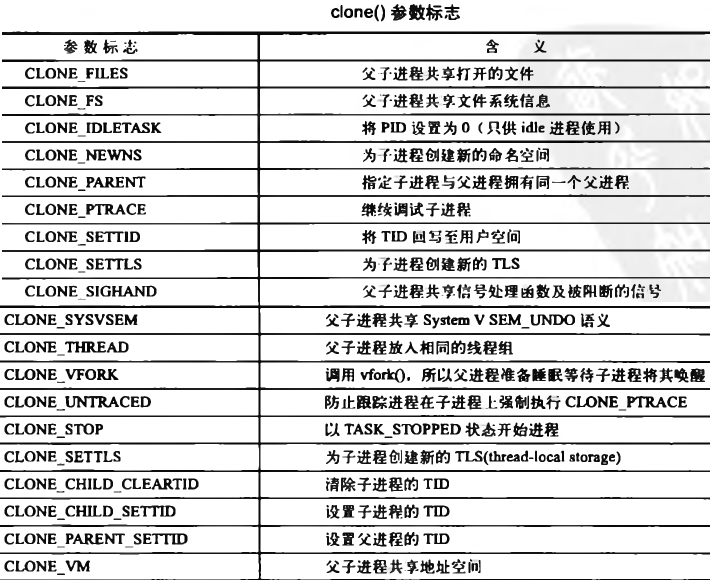
- 传递给clone()的参数标志决定了新创建进程的行为方式和父子进程之间共亨的资源种类。 下标列举这些clone()用到的参数标志以及它们的作用,这些是在<linux/sched.h>中定义的:
do_fork()源码
以下代码来自于Linux-2.6.22/kernel/fork.c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
2 unsigned long stack_start,
3 struct pt_regs *regs,
4 unsigned long stack_size,
5 int __user *parent_tidptr,
6 int __user *child_tidptr)
7{
8 struct task_struct *p;
9 int trace = 0;
10 struct pid *pid = alloc_pid();
11 long nr;
12
13 if (!pid)
14 return -EAGAIN;
15 nr = pid->nr;
16 if (unlikely(current->ptrace)) {
17 trace = fork_traceflag (clone_flags);
18 if (trace)
19 clone_flags |= CLONE_PTRACE;
20 }
21
22 p = copy_process(clone_flags, stack_start, regs, stack_size, parent_tidptr, child_tidptr, pid);
23 /*
24 * Do this prior waking up the new thread - the thread pointer
25 * might get invalid after that point, if the thread exits quickly.
26 */
27 if (!IS_ERR(p)) {
28 struct completion vfork;
29
30 if (clone_flags & CLONE_VFORK) {
31 p->vfork_done = &vfork;
32 init_completion(&vfork);
33 }
34
35 if ((p->ptrace & PT_PTRACED) || (clone_flags & CLONE_STOPPED)) {
36 /*
37 * We'll start up with an immediate SIGSTOP.
38 */
39 sigaddset(&p->pending.signal, SIGSTOP);
40 set_tsk_thread_flag(p, TIF_SIGPENDING);
41 }
42
43 if (!(clone_flags & CLONE_STOPPED))
44 wake_up_new_task(p, clone_flags);
45 else
46 p->state = TASK_STOPPED;
47
48 if (unlikely (trace)) {
49 current->ptrace_message = nr;
50 ptrace_notify ((trace << 8) | SIGTRAP);
51 }
52
53 if (clone_flags & CLONE_VFORK) {
54 freezer_do_not_count();
55 wait_for_completion(&vfork);
56 freezer_count();
57 if (unlikely (current->ptrace & PT_TRACE_VFORK_DONE)) {
58 current->ptrace_message = nr;
59 ptrace_notify ((PTRACE_EVENT_VFORK_DONE << 8) | SIGTRAP);
60 }
61 }
62 } else {
63 free_pid(pid);
64 nr = PTR_ERR(p);
65 }
66 return nr;
67}
68copy_process()函数执行流程
copy_process()函数执行操作如下:
1.调用dup_task_struct()为新进程创建一个内核栈,thread_ifno结构和task_struct,这些值与当前进程的值相同。此时,子进程和父进程的描述符是完全相同的
- 2.检查并确保新创建这个子进程后,当前用户所拥有的进程数目没有超出给它分配的资源的限制
- 3.子进程着手使自己与父进程区别开来。进程描述符内的许多成员都要被清0或设为初始值。那些不是继承而来的进程描述符成员,主要是统计信息。task_struct中的大多数数据都依然未被修改
- 4.子进程的状态被设置为TASK_UNINTERRUPTIBLE,以保证它不会投入运行
- 5.copy_process()调用copy_flags()以更新task_struct的flags成员。表明进程是否拥有超级用户权限的PF_SUPERPRIV标志被清0。表明进程还没有调用exec()函数的PF_FORKNOEXEC标志被设置
- 6.调用alloc_pid为新进程分配一个有效的PID
- 7.根据传递给clone()的参数标志,copy_process()拷贝或共享打开的文件、文件系统信息、 信号处理函数、进程地址空间和命名空间等。在一般情况下,这些资源会被给定进程的所有线程共享;否则,这些资源对每个进程是不同的,因此被拷贝到这里
- 8.最后,copy_process()做扫尾工作并返回一个指向子进程的指针
copy_process()函数执行完之后再回到do_fork()函数,如果copy_process()函数成功返回,
新创建的子进程被唤醒并让其投入运行。内核有意选择子进程首先执行
(备注:虽然想让子进程先运行,但是并非总能如此)。因为一般子进程都会马上调用exec()函数,这样可以避免写时拷贝的额外开销,如果父进程首先执行的话,有可能会开始向地址空间写入
四、进程创建之vfork
-
vfork除了不拷贝父进程的页表项外,vfork()系统调用和fork()相同
-
vfork的特点:
-
子进程作为父进程的一个单独的线程在它的地址空间里运行,父进程被阻塞,直到子进程退出或执行exec()。子进程不能向地址空间写入。在过去的3BSD时期,这个优化是很有意义的,那时并未使用写时拷贝页来实现fork()
- 现在由于在执行fork()时引入了写时拷贝页并且明确了子进程先执行,
vfork()的好处就仅限于不拷贝父进程的页表项了。如果Linux将来fork()有了写时拷贝页表项,
那么vfork()就彻底没用了
* 另外由于vfork语意非常微妙(试想,如果exec()调用失败会发生什么),所以理想情况下,系统最好不要调用vfork(),内核也不用实现它。
完全可以把vfork()实现成一个普普通通的fork()——实际上,Linux 2.2以前都是这么做的
-
vfork创建进程的函数调用流程:
-
与fork()的流程一致相同(见上面的fork流程),只是在调用clone()系统调用时传递一个特殊标志来进行
clone()
vfork()系统调用的实现如下:
2
2
- 传递给clone()的参数标志决定了新创建进程的行为方式和父子进程之间共亨的资源种类。 下标列举这些clone()用到的参数标志以及它们的作用,这些是在<linux/sched.h>中定义的:
copy_process()函数执行流程
copy_process()函数执行操作如下:
1.在调用copy_process()时,task_struct的vfor_done成员被设置为NULL
- 2.在执行do_fork()时,如果给定特别标志,则vfork_done会指向一个特定地址
- 3.子进程先开始执行后,父进程不是马上恢复执行,而是一直等待,直到子进程通过vfork_done指针向它发送信号
- 4.在调 mm_release 时,该 数用于进程退出内存地址空间,并且检査Vf rk_d ne是否 为空,如果不为空,则会向父进程发送信号
- 5.回到do_fork(),进程醒来并返回
如果一切执行顺利,子进程在新的地址空间里运行而父进程也恢复了在原地址空间的运行。 这样,开销确实降低了,不过它的实现并不是优良的
五、进程终结之exec
-
进程终结的情景:
-
**①主动终结:**一般来说,进程的析构是自身引起的。它发生在进程调用exot()系统调用时,既可能显式地调用这个系统调用,也可能隐式地从某个程序的主函数返回(其实C语言编译器会在main()函数数的返回点后面放置调用exit()的代码)
- **②被动终结:**当进程接受到它既不能处理也不能忽略的信号或异常时,它还可能被动地终结
-
**do_exit():**不管进程是怎么终结的,该任务大部分都要靠do_exit()(定义于kernel/exit.c)来完成
do_exit()源码
do_exit()要做的工作如下:
1.将 tast_struct中的标志成员设置为PF_EXITING
- 2.调用del_timer_sync()删除任一内核定时器。根据返回的结果,它确保没有定时器在排队,也没有定时器处理程序在运行
- 3.如果BSD进程记账功能是开启的,do_exit()调用acct_update_integrals()来输出记账信息
- 4.然后调exit_mm()函数释放进程占用的mm_struct,如果没有别的进程使用它们(也就是说,这个地址空间没有被共享),就彻底释放它们
- 5.接下来调用sem_exit()函数。如果进程排队等候IPC信号,它则离开队列
- 6.调用exit_files()和exit_fs(),以分别递减文件描述符、文件系统数据的引用计数。如果其中某个引用计数的数值降为零,那么就代表没有进程在使用相应的资源,此时可以释放
- 7.接着把存放在task_struct的exit_code成员中的任务退出代码为由exit()提供的退出代码,或者去完成任何其他由内核机制规定的退出动作。退出代码存放在这里供父进程随时检索
- 8.调用exit_notify()向父进程发送信号,给子进程重新找养父,养父为线程组中的其它线程或者为init进程,并把进程状态(存放在task_struct结构的exit_state中)设成EXIT_ ZOMBIE
- 9.do_exit()调用schedule()切换到新的进程。因为处于EXIT_ZOMBIE状态的进程不会再被调度,所以这是进程所执行的最后一段代码。do_exit()永不返回
以下代码来自于Linux 2.6.22/kernel/exit.c
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
2{
3 struct task_struct *tsk = current;
4 int group_dead;
5
6 profile_task_exit(tsk);
7
8 WARN_ON(atomic_read(&tsk->fs_excl));
9
10 if (unlikely(in_interrupt()))
11 panic("Aiee, killing interrupt handler!");
12 if (unlikely(!tsk->pid))
13 panic("Attempted to kill the idle task!");
14 if (unlikely(tsk == child_reaper(tsk))) {
15 if (tsk->nsproxy->pid_ns != &init_pid_ns)
16 tsk->nsproxy->pid_ns->child_reaper = init_pid_ns.child_reaper;
17 else
18 panic("Attempted to kill init!");
19 }
20
21
22 if (unlikely(current->ptrace & PT_TRACE_EXIT)) {
23 current->ptrace_message = code;
24 ptrace_notify((PTRACE_EVENT_EXIT << 8) | SIGTRAP);
25 }
26
27 /*
28 * We're taking recursive faults here in do_exit. Safest is to just
29 * leave this task alone and wait for reboot.
30 */
31 if (unlikely(tsk->flags & PF_EXITING)) {
32 printk(KERN_ALERT
33 "Fixing recursive fault but reboot is needed!\n");
34 /*
35 * We can do this unlocked here. The futex code uses
36 * this flag just to verify whether the pi state
37 * cleanup has been done or not. In the worst case it
38 * loops once more. We pretend that the cleanup was
39 * done as there is no way to return. Either the
40 * OWNER_DIED bit is set by now or we push the blocked
41 * task into the wait for ever nirwana as well.
42 */
43 tsk->flags |= PF_EXITPIDONE;
44 if (tsk->io_context)
45 exit_io_context();
46 set_current_state(TASK_UNINTERRUPTIBLE);
47 schedule();
48 }
49
50 /*
51 * tsk->flags are checked in the futex code to protect against
52 * an exiting task cleaning up the robust pi futexes.
53 */
54 spin_lock_irq(&tsk->pi_lock);
55 tsk->flags |= PF_EXITING;
56 spin_unlock_irq(&tsk->pi_lock);
57
58 if (unlikely(in_atomic()))
59 printk(KERN_INFO "note: %s[%d] exited with preempt_count %d\n",
60 current->comm, current->pid,
61 preempt_count());
62
63 acct_update_integrals(tsk);
64 if (tsk->mm) {
65 update_hiwater_rss(tsk->mm);
66 update_hiwater_vm(tsk->mm);
67 }
68 group_dead = atomic_dec_and_test(&tsk->signal->live);
69 if (group_dead) {
70 hrtimer_cancel(&tsk->signal->real_timer);
71 exit_itimers(tsk->signal);
72 }
73 acct_collect(code, group_dead);
74 if (unlikely(tsk->robust_list))
75 exit_robust_list(tsk);
76#if defined(CONFIG_FUTEX) && defined(CONFIG_COMPAT)
77 if (unlikely(tsk->compat_robust_list))
78 compat_exit_robust_list(tsk);
79#endif
80 if (unlikely(tsk->audit_context))
81 audit_free(tsk);
82
83 taskstats_exit(tsk, group_dead);
84
85 exit_mm(tsk);
86
87 if (group_dead)
88 acct_process();
89 exit_sem(tsk);
90 __exit_files(tsk);
91 __exit_fs(tsk);
92 exit_thread();
93 cpuset_exit(tsk);
94 exit_keys(tsk);
95
96 if (group_dead && tsk->signal->leader)
97 disassociate_ctty(1);
98
99 module_put(task_thread_info(tsk)->exec_domain->module);
100 if (tsk->binfmt)
101 module_put(tsk->binfmt->module);
102
103 tsk->exit_code = code;
104 proc_exit_connector(tsk);
105 exit_task_namespaces(tsk);
106 exit_notify(tsk);
107#ifdef CONFIG_NUMA
108 mpol_free(tsk->mempolicy);
109 tsk->mempolicy = NULL;
110#endif
111 /*
112 * This must happen late, after the PID is not
113 * hashed anymore:
114 */
115 if (unlikely(!list_empty(&tsk->pi_state_list)))
116 exit_pi_state_list(tsk);
117 if (unlikely(current->pi_state_cache))
118 kfree(current->pi_state_cache);
119 /*
120 * Make sure we are holding no locks:
121 */
122 debug_check_no_locks_held(tsk);
123 /*
124 * We can do this unlocked here. The futex code uses this flag
125 * just to verify whether the pi state cleanup has been done
126 * or not. In the worst case it loops once more.
127 */
128 tsk->flags |= PF_EXITPIDONE;
129
130 if (tsk->io_context)
131 exit_io_context();
132
133 if (tsk->splice_pipe)
134 __free_pipe_info(tsk->splice_pipe);
135
136 preempt_disable();
137 /* causes final put_task_struct in finish_task_switch(). */
138 tsk->state = TASK_DEAD;
139
140 schedule();
141 BUG();
142 /* Avoid "noreturn function does return". */
143 for (;;)
144 cpu_relax(); /* For when BUG is null */
145}
146
- 至此,
与进程相关联的所有资源都被释放掉了(假设该进程是这些资源的唯一使用者)。
进程不可运行(实际上也没有地址空间让它运行)并处于EXIT_ZOMBIE退出状态
- 它占用的所有内存就是
内核栈、thread_info结构和task_struct结构。此时进程存在的唯一目的就是向它的父进程提供信息。父进程检索到信息后,或者通知内核那是无关的信息后,由进程所持有的剩余内存被释放,归还给系统使用
五、进程终结之删除进程描述符(wait)
- 调用了do_exit()之后,尽管线程已经僵死不能再运行了,
但是系统还保留了它的进程描述符。前面说过,这样做可以让系统有办法在子进程终结后仍能获得它的信息。因此,
进程终结时所需的清理工作和进程描述符的删除被分开执行。在父进程获得已终结的子进程的信息后,或者通知内核它并不关注那些信息后,
子进程的task_struct结构才被释放
- wait()这一族函数都是通过唯一(但是很复杂)的一个系统调用wait4()来实现的。它的标准动作是挂起调用它的进程,直到其中的一个子进程退出,此时函数会返回该进程的PID。此外,调用该函数时提供的指针会包含子函数退出时的退出代码
- 当最终需要是释放进程描述符时,
release_task()会被调用,用以完成以下工作:
- 1.它调用_exit_signal(),该函数调用_unhash_process(),后者又调用detach_pid()从pidhash上删除该进程,同时也要从任务列表中删除该进程
- 2._exit_signal()释放目前僵死进程所使用的所有剩余资源,并进行最终统计和记录
- 3.如果这个进程是线程组最后一个进程,并且领头进程已经死掉,那么release_task()就要通知僵死的领头进程的父进程
- 4.release_task()调用put_task_struct()释放进程内核栈和thread_info结构所占的页,并释放tast_struct所占的slab高速缓存
- 至此,进程描述符和所有进程独享的资源就全部释放掉了
六、进程终结之孤儿进程造成的进退维谷
- 如果父进程在子进程之前退出,必须有机制
来保证子进程能找到一个新的父亲,否则这些成为孤儿的进程就会在退出时永远处于僵死状态,白白地耗费内存
- 前面的部分已经有所暗示,对于这个问题,解决方法是
给子进程在当前线程组内找一个线程作为父亲,
如果不行,就让init做它们的父进程。在do_exit()中会调用
exit_notify(),该函数会调用
forget_original_parent(),而后者会调用
**find_new_reaper()**来执行寻父过程
find_new_reaper()函数
这段代码试图找到进程所在的线程组内的其他进程。如果线程组内没有其他的进程,它就找到到并返回的是init进程
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
2 * When we die, we re-parent all our children.
3 * Try to give them to another thread in our thread
4 * group, and if no such member exists, give it to
5 * the child reaper process (ie "init") in our pid
6 * space.
7 */
8static struct task_struct *find_new_reaper(struct task_struct *father)
9{
10 struct pid_namespace *pid_ns = task_active_pid_ns(father);
11 struct task_struct *thread;
12
13 thread = father;
14 while_each_thread(father, thread) {
15 //遍历该结束的进程所在线程组的下一个进程
16 if (thread->flags & PF_EXITING)//如果得到的下一个进程被标记了 PF_EXITING ,就不符合要求,需要继续遍历
17 continue;
18 if (unlikely(pid_ns->child_reaper == father))
19 /*
20 child_reaper 表示进程结束后,需要这个child_reaper指向的进程对这个结束的进程进行托管,
21 其中的一个目的是对孤儿进程进行回收。
22 若该托管进程是该结束进程本身,就需要重新设置托管进程,
23 设置为该结束进程所在线程组的下一个符合要求的进程即可。
24 */
25 pid_ns->child_reaper = thread;
26 return thread;//在该结束进程所在的线程组中找到符合要求的进程,返回即可
27 }
28
29 /*
30 如果该结束进程所在的线程组中没有其他的进程,
31 函数就返回该结束进程所在命名空间的 child_reaper 指向的托管进程
32 (前提是该托管进程不是该结束进程本身)
33 */
34 if (unlikely(pid_ns->child_reaper == father)) {
35 /*
36 如果该结束进程所在命名空间的 child_reaper 指向的托管进程就是该结束进程本身,
37 而程序运行至此,说明在该线程组中已经找不到符合要求的进程,
38 此时,需要将托管进程设置为 init 进程,供函数返回
39 */
40 write_unlock_irq(&tasklist_lock);
41 if (unlikely(pid_ns == &init_pid_ns))
42 panic("Attempted to kill init!");
43
44 zap_pid_ns_processes(pid_ns);
45 write_lock_irq(&tasklist_lock);
46 /*
47 * We can not clear ->child_reaper or leave it alone.
48 * There may by stealth EXIT_DEAD tasks on ->children,
49 * forget_original_parent() must move them somewhere.
50 */
51 pid_ns->child_reaper = init_pid_ns.child_reaper;
52 }
53
54 return pid_ns->child_reaper;
55}
56
当find_new_reaper()函数返回后,会以下3种进程之一作为新父进程::
原结束进程所在线程组中的一个符合要求的进程
- 原结束进程所在进程命名空间中 child_reaper指向的托管进程
- init进程
现在,给子进程找到合适的养父进程了,
只需要遍历所有子进程并为它们设置新的父进程,代码如下:
2
3
4
5
6
7
8
9
10
11
2
3 list_for_each_entry_safe(p, n, &father->children, sibling) {
4 p->real_parent = reaper;
5 if (p->parent == father) {
6 BUG_ON(task_ptrace(p));
7 p->parent = p->real_parent;
8 }
9 reparent_thread(father, p, &dead_children);
10 }
11exit_ptrace()
- 然后调用ptrace_exit_finish()同样进行新的寻父过程,不过这次是
给ptraced的子进程寻找父亲
- 这段代码遍历了两个链表:子进程链表和ptrace子进程链表,给每个子进程设置新的父进程。这两个链表同时存在的原因很有意思,它也是2.6内核的一个新特性。当一个进程被跟踪时,它的临时父亲设定为调试进程。此时如果它的父进程退出了,系统会为它和它的所有兄弟重新找一个父进程。在以前的内核中,这就需要遍历系统所有的进程来找这些子进程。现在的解决办法是在 一个单独的被ptrace跟踪的子进程链表中搜索相关的兄弟进程——
用两个相对较小的链表减轻了遍历带来的消耗
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2{
3 struct task_struct *p, *n;
4 LIST_HEAD{ptrace_dead);
5
6 write_lock_irq{&tasklist_lock);
7 list_for_each_entry_safe(p, n, &tracer->ptraced, ptrace_entry) {
8 if (_ptrace_detach(tracer, p))
9 listadd(&p->ptrace entry, iptracedead);
10 }
11 write_unlock_irq(&tasklist_lock);
12
13 BUG_ON(!list empty(&tracer->ptraced));
14
15 list_for_each_entry_safe(p, n, &ptrace_dead, pcrace_entry) {
16 list_del_init(&p->ptrace_entry);
17 release_task(p);
18 }
19}
20
21
- 一旦系统为进程成功地找到和设置了新的父进程,
就不会再有出现驻留僵死进程的危险了。init进程会例行调用wait()来检査其子进程,清除所有与其相关的僵死进程
