/proc/sys/net/ipv4:
-
ip_local_port_range:限制了作为TCP或UDP对目标发起连接所选择的本地端口范围,其定义受内核版本影响。具体可以参见net.ipv4.ip_local_port_range 的值究竟影响了啥
-
ip_forward:允许本机路由转发。特别在容器环境下需要开启该功能
-
tcp_window_scaling:表示是否启用TCP窗口因子。窗口因子只能位于TCP SYN/SYN_ACK报文选项中。window size在TCP首部只占16字节,最大为2^16=65536,相对于现代系统来说太小了,使用窗口因子可以增加TCP接收窗口(rwnd,即tcpdump显示的win)大小,窗口因子最大值为14(RFC1323),计算逻辑为:window_size*(2^tcp_window_scaling),因此接收窗口最大为2^16*2^14=1GB。TCP 建链报文中的窗口因子计算方式如下,如sysctl_tcp_rmem[2]=6291456时,窗口因子为7
2
3
4
5
6
7
8
9
10
11
12
2 2 /* Set window scaling on max possible window
3 3 * See RFC1323 for an explanation of the limit to 14
4 4 */
5 5 space = max_t(u32, sysctl_tcp_rmem[2], sysctl_rmem_max);
6 6 space = min_t(u32, space, *window_clamp);
7 7 while (space > 65535 && (*rcv_wscale) < 14) {
8 8 space >>= 1;
9 9 (*rcv_wscale)++;
1010 }
1111 }
12
对于TCP的初始接收窗口大小,linux和centos的实现是不一样的,如linux内核3.10版本的初始接收窗口定义为10mss,但centos 3.10内核中的初始窗口大小定义为TCP_INIT_CWND * 2,即20*MSS大小。(看着linux源码在centos7.4系统上测试,纠结了好久。。)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2u32 tcp_default_init_rwnd(u32 mss)
3{
4 /* Initial receive window should be twice of TCP_INIT_CWND to
5 * enable proper sending of new unsent data during fast recovery
6 * (RFC 3517, Section 4, NextSeg() rule (2)). Further place a
7 * limit when mss is larger than 1460.
8 */
9 u32 init_rwnd = TCP_INIT_CWND * 2;
10
11 if (mss > 1460)
12 init_rwnd = max((1460 * init_rwnd) / mss, 2U);
13 return init_rwnd;
14}
15
16/* TCP initial congestion window as per draft-hkchu-tcpm-initcwnd-01 */
17
2
3
2#define TCP_INIT_CWND 10
3
ps:cwnd为拥塞窗口大小,表示一个RTT时间内可以发送的报文的个数,2.6.32内核之后的初始值设置为TCP_INIT_CWND,可以使用ss -it查看实时状态。
-
tcp_rmem:调节(tcp_moderate_rcvbuf)并限制TCP接收缓存区。包含3个值,第一个值是为每个socket接收缓冲区分配的最少字节数;第二个值是默认值(该值会覆盖net.core.rmem_default。较大的默认值会浪费内存,影响性能),缓冲区在系统负载不重的情况下可以增长到这个值;第三个值是接收缓冲区空间的最大字节数。通过查看源码发现TCP socket接收缓存区的最大值仅在通过SO_RCVBUF设置的时候才会受net.core.rmem_max限制。tcp_rmem影响TCP建链时的窗口因子以及socket接收缓存大小。
-
tcp_adv_win_scale:用于划分网络缓存区和应用缓存区的比例。内核将 socket 接收缓冲区会划分为网络缓冲区和应用缓冲区,网络缓冲区及通常所提到的数据,而应用缓冲区为 skb 头部一类的数据。具体划分比率主要依赖 sysctl 中设置的 tcp_select_initial_window,tcp_adv_win_scale 大于 0 时,网络缓冲区(即socket最大接收窗口)的计算逻辑为 space – (space >> tcp_adv_win_scale);否则计算逻辑为 space>>(-tcp_adv_win_scale) (本段描述来自这里)。
2
3
4
5
6
7
8
9
10
11
12
13
14
2{
3 return sysctl_tcp_adv_win_scale<=0 ?
4 (space>>(-sysctl_tcp_adv_win_scale)) :
5 space - (space>>sysctl_tcp_adv_win_scale);
6}
7
8/* Note: caller must be prepared to deal with negative returns */
9static inline int tcp_space(const struct sock *sk)
10{
11 return tcp_win_from_space(sk->sk_rcvbuf -
12 atomic_read(&sk->sk_rmem_alloc));
13}
14
- tcp_app_win:tcp_adv_win_scale划分出来的应用缓存区保留的字节数,参见Linux网络相关参数
- tcp_wmem:限制TCP发送缓存区大小,包含3个值。第一个值是为每个socket发送缓冲区分配的最少字节数;第二个值是默认值(该值会覆盖wmem_default),缓冲区在系统负载不重的情况下可以增长到这个值;第三个值是发送缓冲区空间的最大字节数。不建议修改。
- tcp_mem:限制总的TCP缓存区的大小。包含3个以页(4k字节)为单位的值,意义与上面类似。不建议修改
- tcp_moderate_rcvbuf:默认开启,用于自动调节发送/接收缓存区大小,初始值为tcp_rmem和tcp_wmem的默认值。不能大于tcp_rmem[2]
- tcp_keepalive_time:TCP保活时间,默认2小时
- tcp_keepalive_intvl:保活报文发送周期,默认90秒
- tcp_keepalive_probes:保活报文发送次数。keepalive routine每2小时(7200秒)启动一次,发送第一个probe(探测包),如果在75秒内没有收到对方应答则重发probe,当连续9个probe没有被应答时,认为连接已断
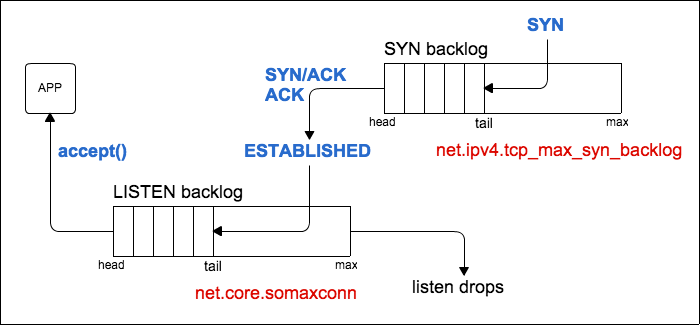
- tcp_max_syn_backlog:TCP半连接队列大小,队列中的连接处理SYN-RECV状态(即为接收到对端的ACK报文)。表示可以保存的未完成TCP握手的连接的数目。下图来自这篇博客,建链完成后连接会转移到LISTEN backlog中。当该队列满后,会直接丢弃SYN报文。
当tcp_syncookies设置为1后,当半连接队列满时,将不会丢弃SYN,而是会返回一个带有cookie的SYN/ACK报文。
位于syn backlog中的连接状态为SYN_RECV,可以通过如netstat -antp|grep SYN_RECV|wc -l 查看当前处于syn backlog中的连接的数目。可以通过nstat -az TcpExtListenDrops查看是否有因为syn backlog满而丢弃的报文(如syn攻击)。更多参见另一篇博文。
- tcp_syncookies:当启动sync cookies功能后,当syn backlog队列满时,系统不会丢弃新的SYN报文,而是会发送syncookie报文来校验是否是正常的连接,主要用于防止syn flood攻击。下图来自SYN-Cookies,可以看到syn cookies充当了类似连接缓存的作用。syncookie的方式修改了正常的TCP交互,可能在高负荷的服务器下出现一些问题,如计算cookie的hash会加重CPU负担,不支持某些TCP选项等。官方并不建议将该参数作为性能调参,而推荐使用tcp_max_syn_backlog, tcp_synack_retries, 和 tcp_abort_on_overflow。

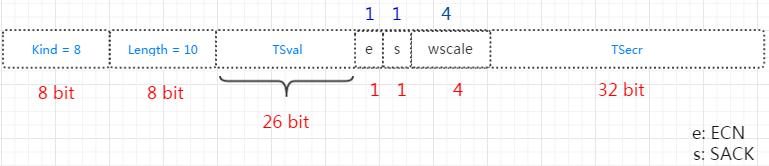
开启tcp_syncookies时通常需要开启tcp_timestamps,用来将tcp选项编码到时间戳中。如下图可以看到窗口因此wscale编码在时间戳中,不启用时间戳将无法使用该选项。
- tcp_abort_on_overflow:在TCP全连接队列(net.core.somaxconn)满之后,当新的连接到来之后会丢弃握手阶段的最后一个ack(值为0)报文;或发送rst(值为1)报文直接断链。默认值为0。只有在确认服务端长时间内无法处理新连接的情况下才会置为1,否则置为1会影响客户端使用。当全连接队列满且该值为0的情况下,客户端会根据net.ipv4.tcp_synack_retries继续尝试建立连接。
- tcp_timestamps:默认打开。enable时间戳会启用Round Trip Time Measurement (RTTM) 和Protect Against Wrapped Sequences (PAWS)功能,前者用于计算rto;后者用于解决高带宽下的序列号回环问题,使用时间戳作为维度来判断数据包是否有效。启用时间戳功能可以提高系统性能。tcp_timestamps可以用于NAT环境,并不会对连接造成影响,只有tcp_timestamps与tcp_tw_recycle同时启用时才会在NAT环境下导致连接超时。如下图,假设server启用了tcp_timestamps与tcp_tw_recycle,2个client通过NAT连接到一个server,此时对server来说,client1和client2的地址都变成了NAT后的地址。当server主动断开与client的TCP连接,如果在client1锻炼后的TCP_PAWS_MSL时间内,client2发起连接,但client2的SYN报文的timestamps小于先前server保存的时间戳,会导致该SYN报文被丢弃,而不回复任何报文,最后client2会timeout。参见stackoverflow的这篇文章。单独timestamp功能不会导致此问题

- tcp_timestamps必须在两端同时开启的情况下才会生效。
- tcp的timestamp功能是在TCP握手阶段协商的。
- tcp timestamp的
- tcp_tw_recycle:默认关闭,仅在tcp_timestamps开启条件下生效,用于server端在一个rto时间内快速回收TIME_WAIT状态的socket。生产环境建议关闭。内核 4.12 之后已移除: remove tcp_tw_recycle。更多参考这里
- tcp_tw_reuse:默认关闭,仅在tcp_timestamps开启条件下生效,仅使适用于客户端复用处于TIME-WAIT状态(超过1s)的socket。主要用于客户端高并发测试场景,减少socket消耗。
- tcp_fin_timeout:FIN_WAIT_2状态的时长
- tcp_max_tw_buckets:限制了处理TIME_WAIT状态的连接的数目。多余的连接会直接释放。
- tcp_syn_retries:TCP建链时syn报文的重传次数,默认为6,即syn报文最多发送7次,重传间隔为2<<(n-1)秒。
- tcp_synack_retries:设置了TCP建链时syn-ack报文的重传次数,重传间隔为2<(n-1)秒
- tcp_retries1:默认3。当TCP数据重传超过这个值计算出的超时时间后(见retries2),会进行刷新底层路由的操作,防止由于网络链路发生变化而导致TCP传输失败
- tcp_retries2:默认15。(如果socket设置了TCP_USER_TIMEOUT参数,则TCP数据重传超时由该参数决定,不受tcp_retries2控制)。总的重传超时时间通过如下方式计算得出,其中变量boundary对应的就是tcp_retries1或tcp_retries2的值。可以看到tcp_retries1和tcp_retries2其实计算的是最大超时时间,而不是重传次数。
linear_backoff_thresh用于计算使用/不使用指数退避算法的超时时间点,ilog2(TCP_RTO_MAX / rto_base)就是求底数为2,反对数为(120000/200)的整数,值为9,即当总的重传时间小于(2<<9-1)*200ms=204.6s时,重传间隔时间使用指数退避方式;当总的重传时间大于204.6时,后续重传时间为TCP_RTO_MAX,即120s。
按照如下方式可以计算出,tcp_retries2=15时,最大超时时间为(2<<9-1)*0.2+(15-9)*120=924.6s,即当总的重传时间大于924.6s后,停止重传。
重传次数受路由rto影响,可以使用使用如下方式设置一条连接的rto_min,非200ms时可能会使得总的重传次数大于或小于15。(可以使用ss -i查看TCP连接上的rto大小)
2
2
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2static unsigned int tcp_model_timeout(struct sock *sk,
3 unsigned intboundary,
4 unsigned int rto_base)
5{
6 unsigned int linear_backoff_thresh, timeout;
7
8 linear_backoff_thresh = ilog2(TCP_RTO_MAX / rto_base);
9 if (boundary <= linear_backoff_thresh)
10 timeout = ((2 << boundary) - 1) * rto_base;
11 else
12 timeout = ((2 << linear_backoff_thresh) - 1) * rto_base +
13 (boundary - linear_backoff_thresh) * TCP_RTO_MAX;
14 return jiffies_to_msecs(timeout);
15}
16
- tcp_max_orphans:系统所能维护的孤儿socket(不与任何文件描述符关联)的最大数目(可以通过ss -s命令查看当前tcp的orphan socket数目)。当orphan socket数目超过该值后,会通过reset来关闭连接。每个orphan socket会占用64Bb且不可swap的内存。该参数可以用于防止DDoS攻击。可以查看netstat的TcpExtTCPAbortOnMemory统计信息。
- tcp_orphan_retries:规定了orphan socket的重传次数。减小该值可以快速回收orphan socket。net.ipv4.tcp_orphan_retries的默认值为0,内核计算时会重置为8。orphan socket为调用内核tcp_close
(
struct
sock
*
sk
,
long
timeout
)函数产生的。orphan socket包含FIN_WAIT1、LAST_ACK、CLOSING(同时关闭)状态的socket(TIME_WAIT状态不属于orphan socket–实测验证)。更多详细参见这篇博文
* tcp_sack:用于提高重传多个报文时的速率(重传特定报文),sack的缺点可以查看When to turn TCP SACK off?
* tcp_ecn:配合中间路由器实现感知中间路径的拥塞,并主动减缓TCP的发送速率,从而从早期避免拥塞而导致的丢包,实现网络性能的最大利用。网络中的路由器按照1999年的ECN草案方案实现,将只识别ECN=10的报文作为支持ECN功能,而不识别ECN=01的报文,这类路由器可能将ECN=01的报文将按照ECN=00的行为处理,最后进行RED丢包。但并不影响网络的正常功能默认值为2(即二进制10)。参考不要乱用 TCP ECN flag
* tcp_fastopen:TCP Fast Open(TFO)是用来加速连续TCP连接的数据交互的TCP协议扩展,原理如下:在TCP三次握手的过程中,当用户首次访问Server时,发送SYN包,Server根据用户IP生成Cookie(已加密),并与SYN-ACK一同发回Client;当Client随后重连时,在SYN包携带TCP Cookie;如果Server校验合法,则在用户回复ACK前就可以直接发送数据;否则按照正常三次握手进行。其中1表示客户端开启,2表示服务端开启,3表示客户端和服务器同时开启。在高版本的Linux中,默认为1
* tcp_reordering:通知内核在一条TCP中需要重组的报文数目,此时不考虑报文丢失。如果大于该值,会认为有报文丢失,TCP栈会自动切换到慢启动。默认3
* tcp_fack:基于sack的拥塞避免控制。
* tcp_challenge_ack_limit:每秒发送的挑战报文(challenge ack用于防止Blind In-Window Attacks,分为接收到数据,RST报文,SYN报文的处理,用于避免盲数据注入和断链攻击)的数量,默认1000。参见TCP挑战ACK报文限速
- tcp_invalid_ratelimit:用于控制响应如下无效TCP报文的重复ACK报文的最大速率(挑战ACK受此限制),默认500ms:
-
无效的序列号
- 无效的确认号
- PAWS 校验失败
-
tcp_limit_output_bytes:用于控制TCP Small Queue队列长度,TSQ属于Qdisc的一种。
-
tcp_autocorking:是否允许TCP auto corking。在进行一些小的写操作时,如果此时Qdisc或驱动的传输队列中已经有至少一个报文,此时会合并发送,用以减小发送的报文数量。默认允许。socket可以使用TCP_CORK 参数来取消或允许该特性
参考:
- Linux之TCPIP内核参数优化
- TCP protocol
- Tuning TCP – sysctl.conf
- 聊一聊重传次数
- TCP timestamp
- TCP SOCKET中backlog参数的用途是什么? —图解
- Coping with the TCP TIME-WAIT state on busy Linux servers
- SYN Flood攻击及防御方法
- TCP SYN-Cookie的原理和扩展
- TCP 接收窗口
/proc/sys/net/core:
-
somaxconn:TCP LISTEN backlog 队列大小,默认128。表示挂起的(未被accept处理的)请求的最大数目。可以通过listen函数的第二个参数指定int listen(int sockfd, int backlog) ,如果设置的backlog值大于net.core.somaxconn值,将被置为net.core.somaxconn值大小。可以使用ss -ntl 查看当前LISTEN backlog队列长度以及队列中待处理的连接长度。如下面表示LISTEN backlog长度为128,当前有1个连接待(accept)处理。LISTEN backlog队列满之后的动作与net.ipv4.tcp_abort_on_overflow相关。
2
3
4
2State Recv-Q Send-Q Local Address:Port Peer Address:Port
3LISTEN 1 128 :::19090 :::*
4
-
rmem_default:设置了TCP/UDP/Unix等socket的接收缓存区默认值,由内核自动调整,不建议修改。TCP下设置为net.ipv4.tcp_rmem的默认值
-
wmem_default:设置了TCP/UDP/Unix等socket的发送缓存区默认值,由内核自动调整,不建议修改。TCP下设置为net.ipv4.tcp_wmem的默认值
-
rmem_max:设置了TCP/UDP/Unix等socket的接收缓存区的上限值。rmem_max的作用如下:
-
限制通过socket选项SO_RCVBUF设置(sock_setsockopt)的接受缓存区的大小
- 用于计算TCP建链的窗口因此(参见本文tcp_window_scaling描述)
更多参见TCP receiving window size higher than net.core.rmem_max
- wmem_max:设置了TCP/UDP/Unix等socket的发送缓存区的上限值
参考:
- 关于TCP 半连接队列和全连接队列
/proc/sys/net/netfilter:
-
nf_conntrack_acct:enable该值后会在/proc/net/nf_conntrack的条目中增加连接交互的总package count和总package bytes参数。参见What does nf_conntrack.acct really do?
-
nf_conntrack_timestamp:enable该值后会在/proc/net/nf_conntrack的条目中增加连接存活累计时间(单位s)参数delta-time。
-
nf_conntrack_buckets:只读文件,表示HASHSIZE。系统启动后无法修改,但可以通过如下方式修改。
2
2
- nf_conntrack_max:设置连接跟踪数的最大值,当系统达的连接跟踪数达到该值后,再创建连接跟踪时会报“nf_conntrack: table full, dropping packet”错误。由于连接跟踪数比较占内存,因此不能盲目增加该值大小。nf_conntrack_max=HASHSIZE*(bucket size),(bucket size)默认为4。bucket size不能直接修改,只能通过修改nf_conntrack_max/nf_conntrack_buckets的比值来间接修改。

/proc/net/nf_conntrack中的两个特殊字段含义如下:
-
- [
ASSURED]: 在两个方面(即请求和响应)方向都看到了流量。
* [UNREPLIED]: 尚未在响应方向上看到流量。如果连接跟踪缓存溢出,则首先删除这些连接。
-
nf_conntrack_count:当前使用的连接跟踪数目,只读。
-
sysctl -a | grep conntrack | grep timeout可以看出与各个协议状态相关的timeout时间。以TCP为例,如下参数描述了TCP各个状态的nf_conntrack的生存时间,如nf_conntrack_tcp_timeout_established的值为432000s(5days),表示处于建链状态的TCP的最大生存时间为5天,超时后会移除该连接跟踪数。在NAT场景下,移除连接跟踪将会导致连接中断(但不会通知两端)。非NAT场景下,其连接跟踪仅仅用于记录当前连接情况,移除这种情况下的连接跟踪不会对链路造成影响。设置如下参数时最好将设置值大于等于系统或协议规定的参数大小,否则可能导致链路异常。
2
3
4
5
6
7
8
9
10
11
2net.netfilter.nf_conntrack_tcp_timeout_close_wait = 60
3net.netfilter.nf_conntrack_tcp_timeout_established = 432000
4net.netfilter.nf_conntrack_tcp_timeout_fin_wait = 120
5net.netfilter.nf_conntrack_tcp_timeout_last_ack = 30
6net.netfilter.nf_conntrack_tcp_timeout_max_retrans = 300
7net.netfilter.nf_conntrack_tcp_timeout_syn_recv = 60
8net.netfilter.nf_conntrack_tcp_timeout_syn_sent = 120
9net.netfilter.nf_conntrack_tcp_timeout_time_wait = 120
10net.netfilter.nf_conntrack_tcp_timeout_unacknowledged = 300
11
参考
- Linux 实例常用内核网络参数介绍与常见问题处理
- Iptables之nf_conntrack模块
/proc/sys/vm:
-
vfs_cache_pressure:控制内核回收directory和inode的回收速率,当降低该值会使得内核保留dentry和inode caches,当vfs_cache_pressure=0时,内核不会回收dentry和inode caches,这种情况下可能会导致内存泄漏。增加该值可能会影响系统性能,但会加快回收dentry和inode caches,可以通过slabtop命令查看dentry/inode caches的数值。参见记一次内存使用率过高的报警
-
dirty_background_ratio:默认10,以比例规定内存脏数据最大值,dirty_background_ratio和dirty_background_bytes只能选择一种,即一个为非0,则另一个为0。当对数据的一致性要求比并发处理更高时,可以将该值调低
-
dirty_background_bytes:默认0,以具体数值规定内存脏数据最大值
-
dirty_writeback_centisecs:默认500,即5s,内存脏数据写回周期,系统以该周期定时启动pdflush/flush/kdmflush线程来将脏数据写会到磁盘。如果IO繁忙时,可能会启动多个flush线程。需要注意的是,flush对应的脏数据不一定会从内存中释放(见下)。
-
dirty_expire_centisecs:默认3000,即30s,脏数据在内存中停留的最长时间,当超过该时间后,脏数据会在下一次写回到磁盘。
-
脏数据在内存停留条件为:
-
a:dirty_expire_centisecs时间以内
* b:脏数据没有超过dirty_background_ratio阈值- dirty_ratio:默认30,内存中脏数据占总可用(available)内存的最大比例,当超过该值后系统会执行写回操作并阻塞所有进程的IO写操作,直到脏数据小于dirty_ratio。
- kswapd会在可用内存低于zone设置的low时执行内存回收。当可用内存低于zone的min时会触发内核直接回收机制(OOM)。low值通过/proc/vm/min_free_kbytes设置。pdflush用于周期性地将脏数据写回到磁盘,当脏数据大于dirty_background_ratio或dirty_background_bytes时会触发IO阻塞,kswapd和pdflush在某些功能上会有一些耦合,kswapd用于缓存管理,包含内存的swap out和page out,page cache的回收,而pdflush仅用于回收dirty cache。具体参见kswapd和pdflush
参考:
- linux-pdflush.htm
- linux-kernel-sysctl-vm/
- sysctl/vm.txt
- Linux_Page_Cache_Basics
/proc/sys/net/bridge:
- bridge-nf-call-arptables:表示arptables是否可以过滤bridge接口的报文。
- bridge-nf-call-ip6tables:表示ip6tables是否可以过滤bridge接口的报文
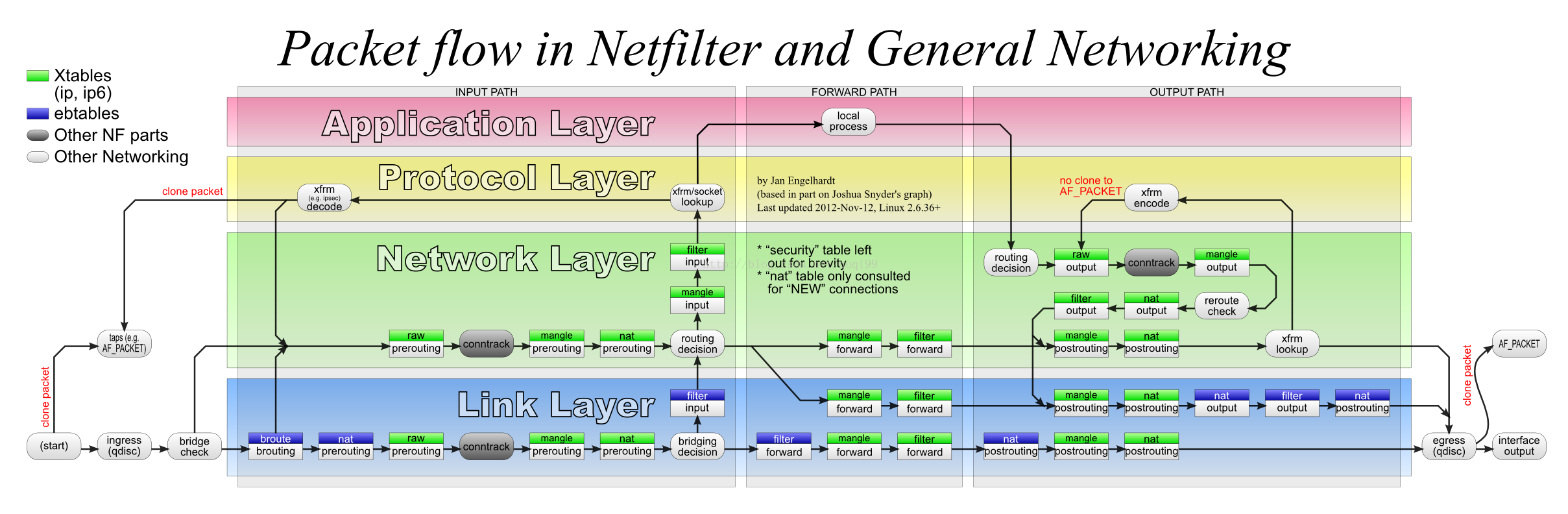
- bridge-nf-call-iptables:表示iptables是否可以过滤二层bridge接口的报文。iptables既能处理三层报文也能处理二层报文,bridge环境下使能该选项,可能会导致二层网络问题。注意下图中的"bridge check"处理节点。ps:ebtables用于对以太网帧的过滤,iptables用于对ip数据包的过滤
参考:
- What's bridge-netfilter?
- bridge-nf
- net.bridge.bridge-nf-call-iptables=1
/proc/sys/fs:
- file-max:内核可以分配的文件句柄的最大值。当遇到如“VFS: file-max limit <number> reached"错误时,说明该值过低,可以调整上限。该值通常由内核确定,为内存的10%左右
- file-nr:描述了内核文件句柄的使用情况。第一个值表示当前分配的文件句柄的数目;第二个表示已经分配但未使用的文件句柄的数目;第三个值表示可分配的文件句柄的最大值。
- nr_open:限制了单个进程可以打开的文件描述符的上限。关系为:ulimit -Sn <= ulimit -Hn <= cat /proc/sys/fs/nr_open
需要注意的是进程可打开的文件描述符的最大数目并不一定等于ulimit -Sn,如进程可以通过systemd的LimitNOFILE参数来设置其soft值。可以在/proc/$pid/limits中查看进程的ulimit值,也可以直接修改该值来修改进程的ulimit限制。
需要注意内核文件句柄和文件描述符的区别,文件描述符为用户层面的内容,可以使用lsof或在/proc/$pid/fd中查看程序打开的文件描述符。而内核文件句柄的使用情况需要查看内核参数file-nr。更多可以参考这篇文章。
内核文件句柄可以通过如下方式申请,当共享内存使用结束后需要卸载共享内容(如mmap/munmap,shmat/shmctl($shmid, IPC_RMID, NULL)),否则会导致内核文件句柄泄露(内核句柄通过引用计数来判断是否删除该文件句柄)。
- open系统调用打开文件(path_openat内核函数)
- 打开一个目录(dentry_open函数)
- 共享内存attach (do_shmat函数)
- socket套接字(sock_alloc_file函数)
- 管道(create_pipe_files函数)
- epoll/inotify/signalfd等功能用到的匿名inode文件系统(anon_inode_getfile函数)
参考:
- sysctl/fs.txt
- 资源限制(RLIMIT_NOFILE)的调整细节及内部实现
/proc/sys/kernal:
- sched_rt_period_us:该文件中的值指定了等同于100% CPU宽度的调度周期。取值范围为1到INT_MAX,即1微秒到35分钟。默认值为1000,000(1秒)
- sched_rt_runtime_us:该文件中的值指定了实时和deadline调度的进程可以使用的"period"(sched_rt_period_us)。取值范围为-1到INT_MAX-1,设置为-1标识运行时间等同于周期,即没有给非实时进程预留任何CPU。默认值为950,000(0.95秒),表示给非实时或deadline调度策略保留5%的CPU。sched_rt_period_us和sched_rt_runtime_us都与实时调度有关。
- sched_cfs_bandwidth_slice_us:设置系统层面的CPU带宽(即可占用的CPU时间),默认5ms。进程的CPU带宽可以通过cgroup的cpu.cfs_quota_us和cpu.cfs_period_us设置。
