1. 关系型数据库
常见的关系型数据库:SqlServer,Mysql,oracle。
特点:数据和数据之间,表和字段之间,表和表之间是存在关系的。
例如:部门表中的员工ID,与员工表的员工ID。
用户表中的用户名、密码字段。
商品分类表和商品表,就是一对多的关系。
特点:
1、数据之间有关系,在进行对数据的增删改查的时候就非常方便。
如查部门下的所有员工信息时,只要写一条SQL语句,就能搞定。
2、关系型数据库是有事务操作,能够保证数据的一致性、完整性。
缺点:
1、因为数据与数据之间是有关系,这种关系不是空穴来风,它是由底层大量算法来保证的。如select * from product;语句,其实会进行底层大量算法的运算。虽然查询出来你所想要的数据,但是大量算法会拉低系统运行速度、消耗系统性能。
2、关系型数据库在面对海量数据的增删改查时会显示得无能为力。很有可能会宕机(未响应、卡住了)。
3、海量数据环境下对数据表进行维护/扩展,也会变得无能无力。
如:update product set cname = ‘手机数码’;
//如果数据量在几百万以上会直接卡到
如:要将商品表的cname字段,由varchar(64)修改为char(100) 由于数据量大,每一条语句都要去运行关系算法,这样直接会卡死。
特点:关系型数据库适合处理一般量级数据,但是安全。
2. 非关系型数据库
为了处理海量数据,需要将关系型数据库的关系去掉。
非关系型数据库设计之初是为了替代关系型数据库。
常用的非关系型数据库:Redis。
优点:
1、海量数据的增删改查,非常轻松应对。因为数据与数据之间是没有关系的,所以就不存在大量算法。
2、海量数据的维护也是非常轻松,如在海量数据中扩充一个字段(非关系数据库不用去运行关系算法)。
1. 缺点:
1、数据和数据之间没有有关系,所以不能一目了然。如在关系型数据库中存储一个部门表,一看就能 知道部门表里有哪些数据(部门名、部门下的员工)。非关系型数据库数据与数据之间是没有关系的,它们之 间是单独存在的。把数据查询出来时,就好比一盘散沙一样,然后自己再将它们整理成为一个有关系的表。
2、非关系型数据库数据与数据之间是没有关系了,也没有强大的事务保证数据的完整性与安全性。
特点:适合处理海量数据,效率高。但是不一定安全。
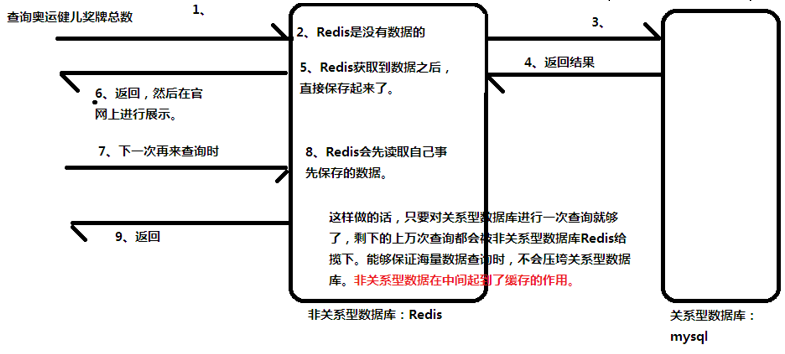
如:查询奥运健儿奖牌总数。 这些数据一般都是在官网上进行展示,它的查询是极为频繁的,可能 几秒钟就会有上万次查询,像这种几秒钟查询上万次查询,如果交给关系型数据库,它不一定能扛得住。 而非关系型数据库会非常轻松应对。
结论:将来看开发都是关系型数据库+非关系型数据库一起共同带起一个项目。在这个 项目中, 重要 的数据保存到关系型数据库中,而海量且不重要的数据就保存到非关系型数 据库中。
3.Redis充当的角色
充当关系型数据库的缓存而存在,缓解关系型数据库的查询压力(也叫缓存数据库)。
4.Redis部署
使用docker在Linux系统部署Redis
2
3
4
5
6
7
8
9
10
11
2docker pull Redis
3
4# --name:名称 -p:端口 ‐v:目录映射关系
5 docker run ‐di ‐‐name=redis‐p 6379:6379 redis
6
7客户端测试 在你的本地电脑命令提示符下,用window版本redis测试
8redis‐cli ‐h 192.168.247.135
9
10
11
5.Redis数据结构介绍
1.redis是使用键值对去保存数据的,类似于java中的map集合。(redis中是没有表概念)
2.这个map集合是有key和value,key全部都是字符串,value有五种数据类型。

6.使用redisTemplate进行各类型的CURD操作
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
2
3import org.junit.Test;
4import org.junit.runner.RunWith;
5import org.springframework.beans.factory.annotation.Autowired;
6import org.springframework.data.redis.core.RedisTemplate;
7import org.springframework.test.context.ContextConfiguration;
8import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
9
10import java.util.List;
11import java.util.Set;
12
13@RunWith(SpringJUnit4ClassRunner.class)
14@ContextConfiguration(locations = "classpath:spring/applicationContext_redis.xml")
15public class AllTest {
16 //注入template对象
17 @Autowired
18 private RedisTemplate redisTemplate;
19//----------------------Hash类型的操作:经常用---------------------------------
20//(1)存入值
21@Test
22public void boundHashOpsSet(){
23 redisTemplate.boundHashOps("namehash").put("country1","中国");
24 redisTemplate.boundHashOps("namehash").put("country2","日本");
25 redisTemplate.boundHashOps("namehash").put("country3","韩国");
26}
27//(2)提取所有的KEY
28@Test
29public void boundHashOpsKeys(){
30 Set keys = redisTemplate.boundHashOps("namehash").keys();
31 System.out.println(keys);
32}
33//(3)提取所有的值
34@Test
35public void boundHashOpsValues(){
36 List values = redisTemplate.boundHashOps("namehash").values();
37 System.out.println(values);
38}
39//(4) 根据KEY提取值
40@Test
41public void boundHashOpsByKey(){
42 Object name = redisTemplate.boundHashOps("namehash").get("country1");
43 System.out.println(name);
44}
45//根据KEY移除值
46@Test
47public void boundHashOpsDelByKey(){
48 redisTemplate.boundHashOps("namehash").delete("country2");
49}
50//----------------------------值类型的操作:因为操作数量少,所以不长用---------------------------------
51 @Test
52 public void setValue(){
53 redisTemplate.boundValueOps("name").set("王五");
54 }
55 @Test
56 public void getValue(){
57 Object name = redisTemplate.boundValueOps("name").get();
58 System.out.println(name);
59 }
60 @Test
61 public void deleteValue(){
62 redisTemplate.delete("name");
63 }
64
65//----------------------set类型的操作:因为操作数量少,所以不长用---------------------------------
66 /**
67 * 存入值
68 */
69 @Test
70 public void boundSetOpsAdd(){
71 redisTemplate.boundSetOps("nameset").add("曹操"); //放入值
72 redisTemplate.boundSetOps("nameset").add("刘备");
73 redisTemplate.boundSetOps("nameset").add("孙权");
74 }
75 /**
76 * 提取值
77 */
78 @Test
79 public void boundSetOpsGet(){
80 Set names= redisTemplate.boundSetOps("nameset").members();//取出值
81 System.out.println(names);
82 }
83 /**
84 * 删除集合中的某一个值
85 */
86 @Test
87 public void boundSetOpsDelete(){
88 redisTemplate.boundSetOps("nameset").remove("曹操");
89 }
90
91 /**
92 * 删除整个集合
93 */
94 @Test
95 public void boundSetOpsDeleteAll(){
96 redisTemplate.delete("nameset");
97 }
98
99 //----------------------list类型的操作:因为操作数量少,所以不长用---------------------------------
100 /**
101 * 右压栈:后添加的对象排在后边
102 * 右压栈用的多,因为快,原理是
103 */
104 @Test
105 public void boundListrightPush(){
106 redisTemplate.boundListOps("namelist").rightPush("赵子龙");
107 redisTemplate.boundListOps("namelist").rightPush("张飞");
108 redisTemplate.boundListOps("namelist").rightPush("关羽");
109 }
110 /**
111 * 显示右压栈集合
112 */
113 @Test
114 public void boundListRange(){
115 List namelist = redisTemplate.boundListOps("namelist").range(0, 10);
116 System.out.println(namelist);
117 }
118
119
120 /**
121 * 查询:根据索引查询集合某个元素
122 */
123 @Test
124 public void boundListIndex(){
125 Object name = redisTemplate.boundListOps("namelist").index(1);
126 System.out.println(name);
127 }
128
129 /**
130 * 删除: 根据值移除集合某个元素
131 */
132 @Test
133 public void bondListRemove(){
134 redisTemplate.boundListOps("namelist").remove(1,"关羽");
135 }
136 /**
137 * 删除: 删除全部
138 */
139 @Test
140 public void bondListDelete(){
141 redisTemplate.delete("namelist");
142 }
143}
144
145
