释放双眼,带上耳机,听听看~!
问题
mysql使用limit分页,当limit offset,rows的offset数值过大时,会出现效率问题。
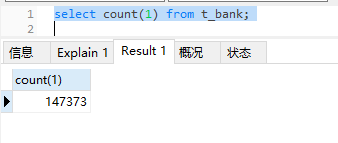
准备数据

正常查询:
2
3
2
3

查询三次,时间分别是0.684s,0.901s,0.708s.

执行计划,走的range索引。
优化方法
2
3
2
3

查询三次,耗时分别为0.151s,0.401s,0.211s。
分析
为什么这样写可以提高效率?
select * from t_bank where bank_code like ‘0%’ limit 145000,5; 的查询过程:
- 找到非聚簇索引叶子节点上的主键值;
- 根据主键值去聚簇索引上查询需要的全部字段值。
- 叶子节点:指InnoDB索引(数据结构:B+Tree,由二叉查找树,平衡二叉树,B树演化而来)的一个存储单元。
- 聚簇索引:又称聚集索引,InnoDB的表一定有一个聚簇索引,有主键就是主键,没有主键就会选择一个唯一非空索引,没有唯一非空索引就会隐式创建一个聚簇索引。
- 聚集索引(主键索引)的叶子节点存的是索引key(主键)和数据行,非聚集索引的叶子节点存的是索引key和主键键值。
由此可以看出,非聚簇索引的查询有两个过程。而limit查询,偏移的所有数据,都会走着两个过程。如果只查id,就可以省略第2个步骤。
证实
为了证实select * from t_bank where bank_code like ‘0%’ limit 145000,5是扫描了145005个索引节点和145005个聚簇索引节点,只能用间接的方法来证明。
InnoDB有个buffer pool,里面存有最近访问的数据页,包括数据页和索引页。我们需要运行两个SQL,比较buffer pool里数据页的数量即可得到结果。
2
3
4
2
3
4
遇到的问题
为了在每次重启时确保清空buffer pool,我们需要关闭innodb_buffer_pool_dump_at_shutdown和innodb_buffer_pool_load_at_startup,这两个选项能够控制数据库关闭时dump出buffer pool中的数据和在数据库开启时载入在磁盘上备份buffer pool的数据。
