1、AdaBoost算法
1)Boosting提升算法
Boosting算法是将“弱学习算法”提升为“强学习算法”。其主要涉及两个部分,加法模型和前向分步算法。加法模型就是说强分类器由弱分类器线性相加而成。一般组合形式如下:
其中,就是一个个的弱分类器,是弱分类器学习到的最优参数,就是弱分类器在强分类器中所占比重,P是所有和的组合。
前向分布算法是指在训练过程中,下一轮迭代产生的分类器是在上一轮的基础上训练得来的,可以写成如下的形式:
由于采用的损失函数不同,Boosting算法也因此有了不同的类型,AdaBoost就是损失函数为指数函数的Boosting算法。
2)AdaBoost原理解释
基于Boosting的理解,对于AdaBoost,需要清楚两点:
(1) 每一次迭代的弱学习有何不一样,如何学习?
(2) 弱分类器权值如何确定?
(1) AdaBoost改变了训练数据的权值,也就是样本的概率分布,其思想是将关注点放在被错误分类的样本上,减少上一轮被正确分类的样本权值,提高那些被错误分类的样本权值。然后,根据所采用的基本机器学习算法进行学习。
(2) AdaBoost采用加权多数表决的方法,加大分类误差率小的弱分类器的权重,减小分类误差率大的弱分类器的权重。
3)实例
有如下的训练样本,我们需要构建强分类器对其进行分类。X是特征,y是标签。
| 序号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| y | 1 | 1 | 1 | -1 | -1 | -1 | 1 | 1 | 1 | -1 |
1 | 1 |
令权值分布
并假设一开始的权值分布是均匀分布:
现在开始训练第一个弱分类器。我们发现阈值取2.5时分类误差率最低,得到弱分类器为:
此处亦可以用其他的弱分类器,只要误差率最低即可。这里用了分段函数,得到了分类误差率
第二步计算在强分类器中的系数
第三步更新样本的权值分布,用于下一轮迭代训练。由公式:
得到新的权值分布,从各0.1变成了:
可以看出,被分类正确的样本权值减小了,被错误分类的样本权值提高了。
第四步得到第一轮迭代的强分类器:
以此类推,经过第二轮,…,第N轮,迭代多词直至得到最终的强分类器。迭代范围可以自己定义,比如限定收敛阈值,分类误差率小于某一个值就停止迭代,比如限定迭代次数,迭代1000次停止。这里数据简单,在第3轮迭代时,得到强分类器:
4) 算法流程
AdaBoost算法流程:
输入:训练数据集,其中,,迭代次数M;
初始化训练样本的权值分布:
对于
a) 使用具有权值分布的训练数据集进行学习,得到弱分类器
b) 计算在训练数据集上的分类误差率:
c) 计算在强分类器中所占的权重:
d) 更新训练数据集的权值分布(这里,是归一化因子,为了使样本的概率分布和为1):
得到最终分类器:
公式推导:

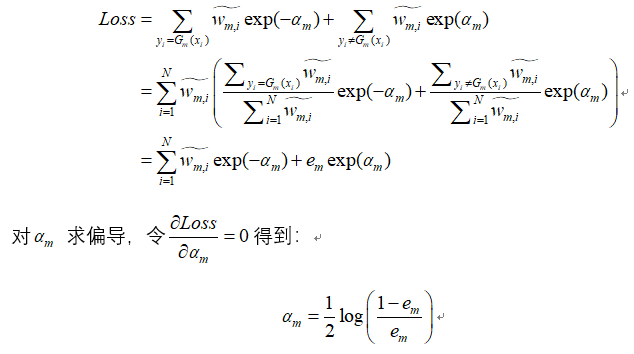
(原文链接:请戳)
更详细的案例实现过程:请戳链接
2、AdaBoost实现之sklearn
例子:鸢尾花例子
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2在scikit-learn库中,有AdaBoostRegression(回归)和AdaBoostClassifier(分类)两个
3在对和AdaBoostClassifier进行调参时,主要是对两部分进行调参:1)AdaBoost框架调参;2)弱分类器调参"""
4# 导包
5from sklearn.model_selection import cross_val_score
6from sklearn.datasets import load_iris
7from sklearn.ensemble import AdaBoostClassifier
8#载入数据,sklearn中自带的iris数据集
9"""
10AdaBoostClassifier参数解释
11base_estimator:弱分类器,默认是CART分类树: DecisionTreeClassifier
12algorithm: 在scikit-learn实现了两种AdaBoost分类算法,即SAMME和SAMME.R,
13 SAMME就是原理篇介绍到的AdaBoost分类算法,指Discrete AdaBoost
14 SAME.R指Real AdaBoost,返回值不再是离散的类型,而是一个表示概率的实数值,算法流程见后 文,两者的主要区别是弱分类器权重的度量,SAMME使用了分类效果作为弱分类器权重,SAMME.R使用了预测概率作为弱分类器权重。
15 SAMME.R的迭代一般比SAMME快,默认算法是SAMME.R。因此,base_estimator必须使用支持概率预测的分类器。
16loss: 这个只在回归中用到
17n_estimator: 最大迭代次数,默认50.在实际调参过程中,常常将n_estimator和学习率learning_rate一起考虑
18learning_rate: 每个弱分类器的权重缩减系数v。f_k(x)=f_{k-1}*a_k*G_k(x).
19"""
20
SAMME.R算法流程
初始化样本权值:
a) 训练一个弱分类器,得到样本的类别预测概率分布
b)
c) ,同时,要进行归一化使得权重和为1
得到强分类模型:
AdaBoostClassifier类
关于AdaBoostClassifier: sklearn.ensemble.AdaBoostClassifier的构造函数如下:
AdaBoostClassifier(base_estimator=None,n_estimators=50,learning_rate=1.0,algorithm='SAMME.R',random_state=None)
demo实现:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2import matplotlib.pyplot as plt
3from sklearn.ensemble import AdaBoostClassifier
4from sklearn.tree import DecisionTreeClassifier
5from sklearn.datasets import make_gaussian_quantiles
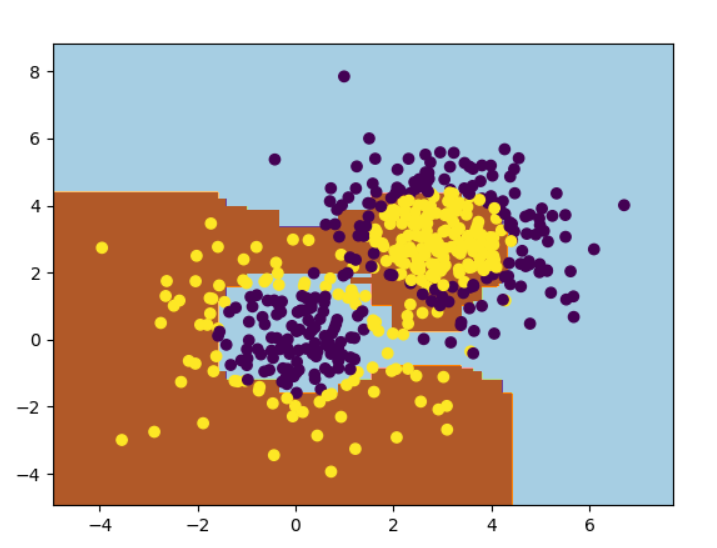
6# 用make_gaussian_quantiles生成多组多维正太分布的数据
7x1,y1 = make_gaussian_quantiles(cov=2.,n_samples=200,n_features=2,n_classes=2,shuffle=True,random_state=1)
8 x2,y2 = make_gaussian_quantiles(mean=(3,3),cov=1.5,n_samples=300,n_features=2,n_classes=2,shuffle=True,random_state=1)
9X = np.vstack((x1,x2))
10y = np.hstack((y1,1-y2))
11weakClassifier = DecisionTreeClassifier(max_depth=1)
12clf = AdaBoostClassifier(base_estimator=weakClassifier,algorithm='SAMME',n_estimators=300,learning_rate=0.8)
13clf.fit(X,y)
14x1_min = X[:,0].min()-1
15x1_max = X[:,0].max()+1
16x2_min = X[:,1].min()-1
17x2_max = X[:,1].max()+1
18x1_,x2_ = np.meshgrid(np.arange(x1_min,x1_max,0.02),np.arange(x2_min,x2_max,0.02))
19y_ = clf.predict(np.c_[x1_.ravel(),x2_.ravel()])
20plt.contourf(x1_,x2_,y_,cmap=plt.cm.Paired)
21plt.scatter(X[:,0],X[:,1],c=y)
22plt.show()
23
24