一、朴素贝叶斯分类的基本原理
给定的待分类项的特征属性,计算该项在各个类别出现的概率,取最大的概率类别作为预测项。
二、贝叶斯定理
根据条件概率的定义。在事件B发生的条件下事件A发生的概率是:
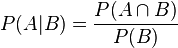
同样地,在事件A发生的条件下事件B发生的概率:
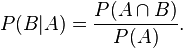
整理与合并这两个方程式,我们可以得到:
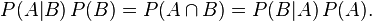
这个引理有时称作概率乘法规则。上式两边同除以P(A),若P(A)是非零的,我们可以得到贝叶斯定理:
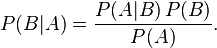
三、贝叶斯定理的变式应用
现有一个待分类项x,拥有n个特征,归于类别c的概率可表示为:
使用贝叶斯定理可变式为:
由于在计算其他类别的概率时,均会除以,并不影响最后结果的判断预测,因此可省略,即:
变式后:
例:
现给出10个被分类项的特征和已确定的类别,用来训练该分类器。
U1
1
0
1
0
1
0
a
U2
1
1
0
1
0
0
a
U3
1
0
0
1
1
1
b
U4
0
0
1
0
1
1
a
U5
1
0
0
1
1
0
c
U6
1
1
1
1
1
0
b
U7
1
1
1
0
1
1
a
U8
1
0
1
0
1
0
c
U9
0
1
0
0
1
0
c
U10
0
1
1
0
1
0
a
由上示表格可计算出 P(F1|c)=0.66 ; P(F5|a)=0.8 ; P(F3|b)=0.5 ; P(c)=0.3…
现给出 U11 项的特征,进行预测推断该项应属于a,b,c中的哪一类
U11
0
0
1
0
1
0
未知
由表格可得知:被分类项 U11 拥有特征F3和F5
预测分到类别a的概率:
预测分到类别b的概率:
预测分到类别c的概率:
因此可预测该项应分至类别a
四、贝叶斯分类运用于文本分类中
实例:对邮件进行垃圾邮件和正常邮件的分类
基本思路:
1、将邮件中的文本的每一个词都作为特征,是否存在这个词可视为该邮件是否存在这个特征。
2、首先给出了已人工划分好的邮件作为训练集,创建关于邮件的完整词库。
3、对每条邮件都创建关于词库的向量,邮件若存在某词语则为1,不存在则为0.
4、创建如下图的向量表。
Email01
1
0
1
0
1
1
0
1
1
1
Email02
0
0
0
0
1
0
1
0
1
1
Email03
1
1
1
1
0
1
1
1
0
1
Email04
0
0
0
0
1
0
0
0
0
0
Email05
1
1
0
1
1
1
1
0
0
1
Email06
0
0
1
0
0
0
0
0
1
0
Email07
0
1
0
1
1
1
1
0
0
0
Email08
0
1
1
1
0
0
0
1
1
1
Email09
1
1
1
1
1
1
1
0
0
1
Email10
0
0
0
0
0
0
0
1
0
0
…
Email n
0
0
1
0
1
0
0
1
0
0
5、待分类的邮件则可以利用上图表使用贝叶斯定理,计算出归于垃圾邮件和正常邮件的概率,并进行预测。
代码实例
1、首先读入数据集 spam 文件夹中的垃圾邮件和 ham 文件夹中的正常邮件,并对它进行解码、分词处理和小写处理,最后合并成一个列表。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2 test_list = []
3 for i in range(21)[1:]:
4 file1 = open(r'spam/%s.txt'%i)
5 text = file1.read()
6 code = chardet.detect(text)['encoding']
7 text = text.decode(code).lower()
8 words = nltk.word_tokenize(text)
9 test_list.append(words)
10 file1.close()
11
12 for i in range(21)[1:]:
13 file1 = open(r'ham/%s.txt'%i)
14 text = file1.read()
15 code = chardet.detect(text)['encoding']
16 text = text.decode(code).lower()
17 words = nltk.word_tokenize(text)
18 test_list.append(words)
19 file1.close()
20 classVec = [1 for i in range(20)]
21 classVec.extend([0 for j in range(20)])#1 代表垃圾邮件 0代表普通邮件
22 return test_list,classVec
23
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
2、利用set类型操作,对列表进行处理,删除重复单词,最后合并成一个词库
2
3
4
5
6
2 vocabSet = set([])
3 for i in dataSet:
4 vocabSet = vocabSet | set(i) #取并集,消除重复集
5 return list(vocabSet)
6
-
1
-
2
-
3
-
4
-
5
-
1
-
2
-
3
-
4
-
5
3、对单条邮件创建向量
2
3
4
5
6
7
8
9
10
2 vector = [0]*len(vocabList)
3 for i in unit:
4 if i in vocabList:
5 vector[vocabList.index(i)] = 1
6 else:
7 print "the word %s is not in my vocabList"%i
8 continue
9 return vector
10
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
4、利用已分好类型的邮件数对贝叶斯分类器进行训练。训练结束后能够得到:正常邮件中和垃圾邮件词库中每个词出现的概率列表(p1Vect,p0Vect),以及垃圾邮件和正常邮件的概率(p1,p0)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2 train_num = len(train_matrix)
3 words_num = len(train_matrix[0])
4 sum_1 = [0 for i in range(words_num)]
5 sum_0 = [0 for i in range(words_num)]
6 _1_num = 0 #是垃圾邮件的邮件数
7 _0_num = 0 #非垃圾邮件的邮件数
8 for i in range(train_num): #将训练矩阵向量进行相加
9 if train_bool[i]==1:
10 for j in range(words_num):
11 sum_1[j] += train_matrix[i][j]
12 _1_num = _1_num + 1
13
14 if train_bool[i]==0:
15 for j in range(words_num):
16 sum_0[j] += train_matrix[i][j]
17 _0_num = _0_num + 1
18
19 print "正常邮件数:",_0_num," 垃圾邮件数:",_1_num
20 p1Vect = [(float(sum_1[j])/_1_num) for j in range(words_num)]
21 p0Vect = [(float(sum_0[j])/_0_num) for j in range(words_num)]
22 p1 = float(_1_num)/train_num
23 p0 = float(_0_num)/train_num
24
25 return p1Vect,p0Vect,p1,p0
26
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
14
-
15
-
16
-
17
-
18
-
19
-
20
-
21
-
22
-
23
-
24
-
25
5、将已转化成向量的邮件,进行类别推测。
2
3
4
5
6
7
8
9
10
11
12
13
14
2 p1 = 1.
3 p0 = 1.
4 words_num = len(unitVector)
5 for i in range(words_num):
6 if unitVector[i]==1:
7 p1 *= p1_vect[i]
8 p0 *= p0_vect[i]
9 p1 *= P1
10 p0 *= P0
11 if p1>p0:
12 return 1
13 else:return 0
14
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
-
1
-
2
-
3
-
4
-
5
-
6
-
7
-
8
-
9
-
10
-
11
-
12
-
13
完整代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
2__author__ = 'Eric Chan'
3import nltk
4import chardet
5
6def loadDataSet(): #导入垃圾邮件和正常邮件作为训练集
7 test_list = []
8 for i in range(21)[1:]:
9 file1 = open(r'spam/%s.txt'%i)
10 text = file1.read()
11 code = chardet.detect(text)['encoding']
12 text = text.decode(code).lower()
13 words = nltk.word_tokenize(text)
14 test_list.append(words)
15 file1.close()
16
17 for i in range(21)[1:]:
18 file1 = open(r'ham/%s.txt'%i)
19 text = file1.read()
20 code = chardet.detect(text)['encoding']
21 text = text.decode(code).lower()
22 words = nltk.word_tokenize(text)
23 test_list.append(words)
24 file1.close()
25 classVec = [1 for i in range(20)]
26 classVec.extend([0 for j in range(20)])#1 代表垃圾邮件 0代表普通邮件
27 return test_list,classVec
28
29def createVocabList(dataSet):#创建词库
30 vocabSet = set([])
31 for i in dataSet:
32 vocabSet = vocabSet | set(i) #取并集,消除重复集
33 return list(vocabSet)
34
35def createVector(unit,vocabList): #对每条邮件创建向量
36 vector = [0]*len(vocabList)
37 for i in unit:
38 if i in vocabList:
39 vector[vocabList.index(i)] = 1
40 else:
41 print "the word %s is not in my vocabList"%i
42 continue
43 return vector
44
45def trainNBO(train_matrix,train_bool):
46 train_num = len(train_matrix)
47 words_num = len(train_matrix[0])
48 sum_1 = [0 for i in range(words_num)]
49 sum_0 = [0 for i in range(words_num)]
50 _1_num = 0 #是垃圾邮件的邮件数
51 _0_num = 0 #非垃圾邮件的邮件数
52 for i in range(train_num): #将训练矩阵向量进行相加
53 if train_bool[i]==1:
54 for j in range(words_num):
55 sum_1[j] += train_matrix[i][j]
56 _1_num = _1_num + 1
57
58 if train_bool[i]==0:
59 for j in range(words_num):
60 sum_0[j] += train_matrix[i][j]
61 _0_num = _0_num + 1
62
63 print "正常邮件数:",_0_num," 垃圾邮件数:",_1_num
64 p1Vect = [(float(sum_1[j])/_1_num) for j in range(words_num)]
65 p0Vect = [(float(sum_0[j])/_0_num) for j in range(words_num)]
66 p1 = float(_1_num)/train_num
67 p0 = float(_0_num)/train_num
68
69 return p1Vect,p0Vect,p1,p0
70vocabList = [] #定义全局变量 创建词库
71def createClassifier():
72 mail_list,spam_bool = loadDataSet()
73 global vocabList
74 vocabList = createVocabList(mail_list)
75 vocabList.sort()
76
77 train_matrix = [] #训练贝叶斯分类器的数据集 向量矩阵
78 for i in range(len(mail_list)):
79 train_matrix.append(createVector(mail_list[i],vocabList))
80
81 return trainNBO(train_matrix,spam_bool)
82
83def classing(p1Vect,p0Vect,P1,P0,unitVector):
84 p1 = 1.
85 p0 = 1.
86 words_num = len(unitVector)
87 for i in range(words_num):
88 if unitVector[i]==1:
89 p1 *= p1_vect[i]
90 p0 *= p0_vect[i]
91 p1 *= P1
92 p0 *= P0
93 if p1>p0:
94 return 1
95 else:return 0
96
97text_data = []
98for i in [21,22,23,24,25]:
99 file1 = open(r'spam/%s.txt'%i)
100 text = file1.read()
101 code = chardet.detect(text)['encoding']
102 text = text.decode(code).lower()
103 words = nltk.word_tokenize(text)
104 text_data.append(words)
105 file1.close()
106
107for i in [21,22,23,24,25]:
108 file1 = open(r'ham/%s.txt'%i)
109 text = file1.read()
110 code = chardet.detect(text)['encoding']
111 text = text.decode(code).lower()
112 words = nltk.word_tokenize(text)
113 text_data.append(words)
114 file1.close()
115
116p1_vect,p0_vect,p1,p0 = createClassifier()
117print vocabList
118for i in text_data:
119 temp = createVector(i,vocabList)
120 print classing(p1_vect,p0_vect,p1,p0,temp)," "
121
