释放双眼,带上耳机,听听看~!
Tensorflow1.13
极客云GPU服务器
极客云注册地址
用这个链接可以免费获得10元优惠券,好像是不需要充值就可以用。
本系统用单核GPU,最便宜的那种就行。
该CNN的训练样本分为两类
一共10类音频,每类100首歌曲,每首歌曲分割为11张图。即每类1100张图。
训练集:每类的前1000张图。
测试集:每类的后100张图。
代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2 '/data/train6.tfrecords', '/data/train5.tfrecords','/data/train4.tfrecords',
3 '/data/train3.tfrecords', '/data/train2.tfrecords','/data/train1.tfrecords',
4 '/data/train0.tfrecords']
5test_list = ['/data/test9.tfrecords','/data/test8.tfrecords','/data/test7.tfrecords',
6 '/data/test6.tfrecords', '/data/test5.tfrecords','/data/test4.tfrecords',
7 '/data/test3.tfrecords', '/data/test2.tfrecords','/data/test1.tfrecords',
8 '/data/test0.tfrecords']
9# 随机打乱顺序
10img, label = read_and_decode_tfrecord(train_list)
11img_batch, label_batch = tf.train.shuffle_batch([img, label], num_threads=2, batch_size=batch_size_, capacity=10000,
12 min_after_dequeue=9930)
13test_img, test_label = read_and_decode_tfrecord(test_list)
14test_img_batch, test_label_batch = tf.train.shuffle_batch([test_img, test_label], num_threads=2, batch_size=batch_size_, capacity=1000,
15 min_after_dequeue=930)
16
17
输入数据是256*256*1的形状。CNN结构如下图。
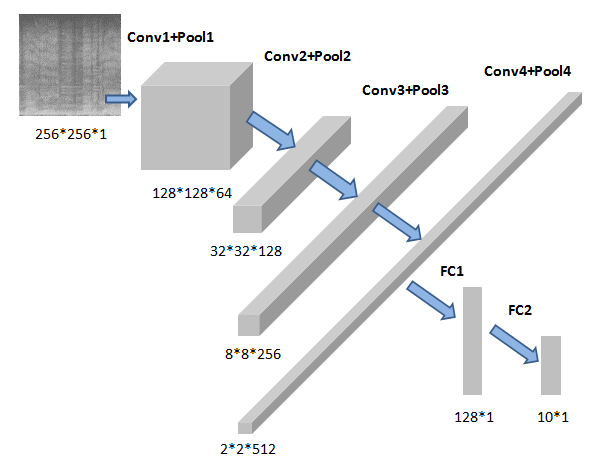
本文使用4层Conv卷积层4层Pooling池化层,卷积层使用elu()作为激励函数,一层全连接层搭建一个卷积神经网络。下面对该网络结构进行详细说明:
- 卷积层1的卷积核大小为3*3,步长为1,卷积核个数为64。池化层1采取最大值子采样max pooling的方式,步长为2,核大小为2*2,padding设置为SAME,即填充像素保持原大小。
- 卷积层2的卷积核大小为3*3,步长为1,卷积核个数为128。池化层2采取最大值子采样max pooling的方式,步长为4,核大小为4*4,padding设置为SAME,即填充像素保持原大小。
- 卷积层3的卷积核大小为3*3,步长为1,卷积核个数为256。池化层2采取最大值子采样max pooling的方式,步长为4,核大小为4*4,padding设置为SAME,即填充像素保持原大小。
- 卷积层4的卷积核大小为3*3,步长为1,卷积核个数为512。池化层2采取最大值子采样max pooling的方式,步长为4,核大小为4*4,padding设置为SAME,即填充像素保持原大小。
- 全连接层输入节点数为2*2*512,输出节点数为128。elu()函数激活全连接层。再使用随机失活(dropout)实现神经网络的正则化。
- 输出结果层,给出预测结果。
代码如下:

CNN相关参数指标:
每批大小:64
学习率:0.001
损失函数和优化器定义。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2lr = tf.Variable(0.001, dtype=tf.float32)
3x = tf.placeholder(tf.float32, [None, 256, 256, 1],name='x')
4y_ = tf.placeholder(tf.float32, [None],name='y_')
5keep_prob = tf.placeholder(tf.float32)
6predict_y = define_predict_y(x)
7tf.add_to_collection("predict", predict_y)
8
9# 将label值进行onehot编码
10one_hot_labels = tf.one_hot(indices=tf.cast(y_, tf.int32), depth=10)
11# 定义损失函数和优化器
12#loss = -tf.reduce_sum(one_hot_labels * tf.log(predict_y))
13loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=predict_y, labels=one_hot_labels))
14optimizer = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss)
15# 准确度
16a = tf.argmax(predict_y, 1)
17b = tf.argmax(one_hot_labels, 1)
18correct_pred = tf.equal(a, b)
19accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
20
训练过程:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2f=open('./ckpt/acc.txt','w')
3with tf.Session() as sess:
4 print("训练模式")
5 # 如果是训练,初始化参数
6 sess.run(tf.global_variables_initializer())
7 # 创建一个协调器,管理线程
8 coord = tf.train.Coordinator()
9 # 启动QueueRunner,此时文件名队列已经进队
10 threads = tf.train.start_queue_runners(sess=sess, coord=coord)
11 # 定义输入和Label以填充容器,训练时dropout为0.25
12 for step in range(8000):
13 #print("step:",step)
14 b_image, b_label = sess.run([img_batch, label_batch])
15 #_, train_accuracy = sess.run([optimizer, accuracy], feed_dict={x: b_image, y_: b_label,keep_prob: 1})
16 # print("step = {}\ttrain_accuracy = {}".format(step, train_accuracy))
17 optimizer.run(feed_dict={x: b_image, y_: b_label,keep_prob: 1})
18 if step % 100 == 0:
19 t_image, t_label = sess.run([test_img_batch,test_label_batch])
20 _, test_accuracy = sess.run([optimizer, accuracy], feed_dict={x: t_image, y_: t_label,keep_prob: 1})
21 print("测试集:step = {}\ttrain_accuracy = {}".format(step, test_accuracy))
22 f.write(str(step+1)+', train_accuracy: '+str(test_accuracy)+'\n')
23 #下面这一段是CNN模型参数的保存,可选
24 if test_accuracy>max_acc:
25 max_acc=test_accuracy
26 saver.save(sess,'./ckpt/music.ckpt',global_step=step+1)
27
28 f.close()
29
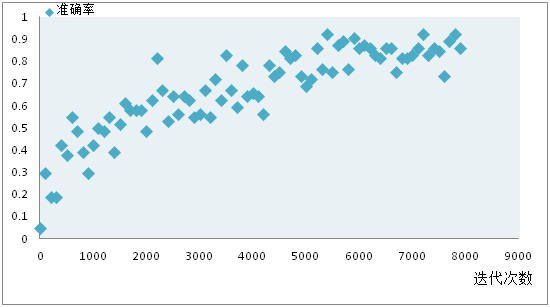
训练效果展示: