预训练的语言模型已经在自然语言处理的各项任务上取得了有目共睹的效果。
目前有两种途径应用语言模型的预训练
feature-base: 就是将预训练后语言模型作为特征提取器,供下游模型使用。例如 ELMo
fine-tune:将预训练后的语言模型经过微调,使之适应下游任务,保留预训练后的参数等,直接应用到下游任务中。
无论是feature-base还是fine-tune,在预训练阶段都是采用单向的语言模型来学习语言表征。这种“单向”严重限制了模型的能力,特别是在fine-tune中。例如在QA任务中,我们需要结合上下两个方向的文章内容来找答案。
为了解决单向的缺陷,论文中提出了两种预训练方法,分别是 “Masked Language model” 和 “next sentence prediction”
论文中同样用到了transformer,不过是双向深层的transformer encoder。
特别注意:这里面讲的双向并不是类似于bi-lstm上的时序上的双向,而是指语义上的方向,代码上是可以并行运行的。
BERT
输入表征
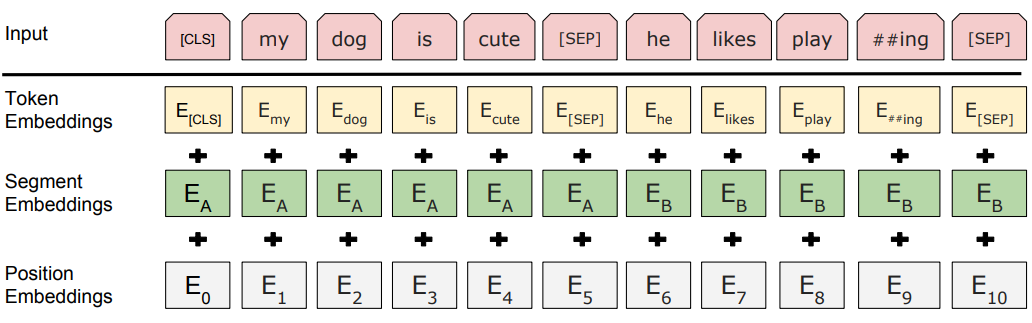
- Token Embeddings: 表示词的embedding
- Segment Embedding:表示词所在句子的index Embedding
- Position Embedding:表示词所在位置的index Embedding
这里无所谓输入的一对句子和单句,如果一对句子,则用sep连接即可。
预训练
Masked LM
直观上,双向网络肯定比单向网络更有威力。对于标准的语言模型,只能是从左向右,或从右向左的单向预测,为了能双向的预训练,论文中提出了类似于“完形填空”的方式来双向的预训练语言模型。简单来说,就是把一段句子随机的15%词扣除掉(用mask token替换),然后在网络中被扣除对应位置出做softmax预测扣除出去的词。是不是于word2vec的BOW训练方式有异曲同工之妙。
但是这样做有两点不妥:
- pre_train阶段和fine_tune阶段,存在一些mismatch,在fine_tune时,是没有mask token的,论文中是这样解决的:
在预训练阶段,对于随机扣除的15%的token,采取不同的替换策略:
1、80%概率用mask token替换
2、10%概率随机用文章出现过的词替换
3、10%概率不变,使用原来的词
- 因为预测的只有15%的词,故相对标准的语言模型,收敛较慢。
注意:Masked LM模型在被扣除词的位置处的输入是mask token或者被替换的词,而不是原本的词。
Next Sentence Prediction
对于一些任务,需要学习到句子间的关系,例如QA、NLI。这种句子间关系,语言模型是不能很好的学习到的。因此论文中提出了Next Sentence Prediction任务。简单来说,就是从单语料库中随机选择两条句子A、B。如果句子B是句子A的下一句,则label为 IsNext,反正为 NotNext。
训练集中,有50%的样本是IsNext,50%样本是NotNext,并且NotNext的样本是随机选取的。
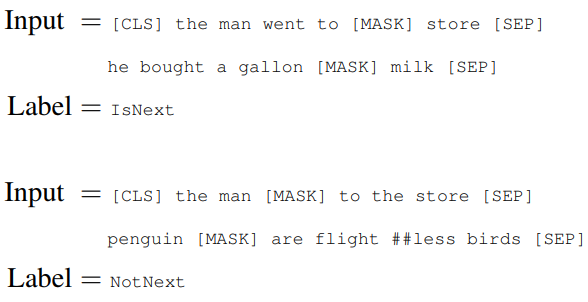
论文中说该分类模型达到97%-98%的准确率。
注意:
- Masked LM是捕捉词之间的关系
- Next Sentence Prediction是捕捉句子之间的关系
- Masked LM和 Next Sentence Prediction是放在一起训练的
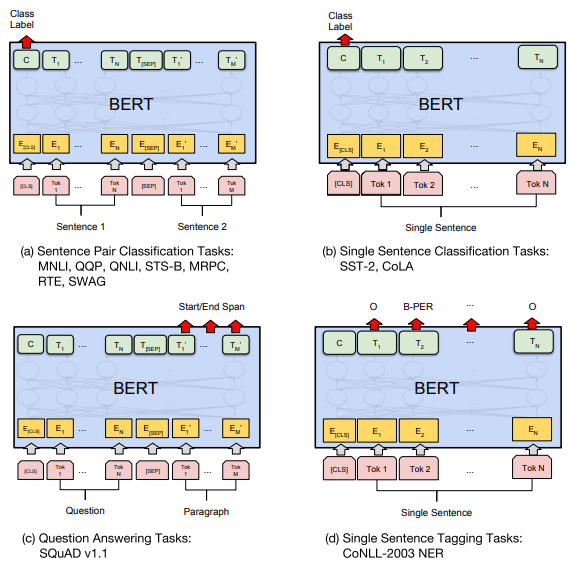
fine-tune
不同类型的任务需要对模型做不同的修改,但是修改都是非常简单的,最多加一层神经网络即可。如下图所示
ELMo、openAI GPT、BERT比较
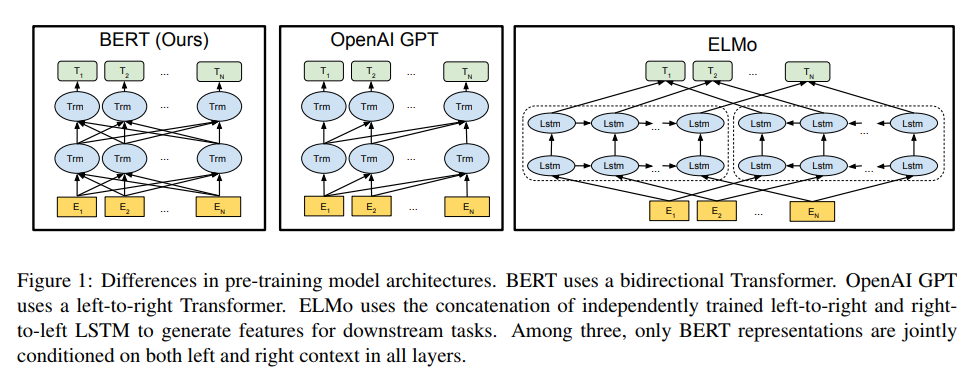
- ELMo模型
是有两个方向相反的LSTM网络组合而成
单向的语言模型做预训练。
Feature-base方式
- OpenAI GPT
1、是transform decoder,图中每一层所有的Trm是一个transformer层,每层间做self attention(masked,只和之前的做self attention),然后将输出结果喂给下一层,这就相当于下一层的一个trm会和上一层该位置之前的trm做了连接,后面的信息被屏蔽(代码实现上用一个mask 矩阵屏蔽)。
2、单向的语言模型做预训练
3、fine-tune方式
- BERT
1、同OpenAI GPT,只不过变成双向深层transformer encoder,同样每层之间做self attention,然后将输出结果喂给下一层,这就相当于与上一层前后两个方向的Trm做了连接。
2、Masked LM和Next Sentence Prediction做预训练
3、fine-tune方式。
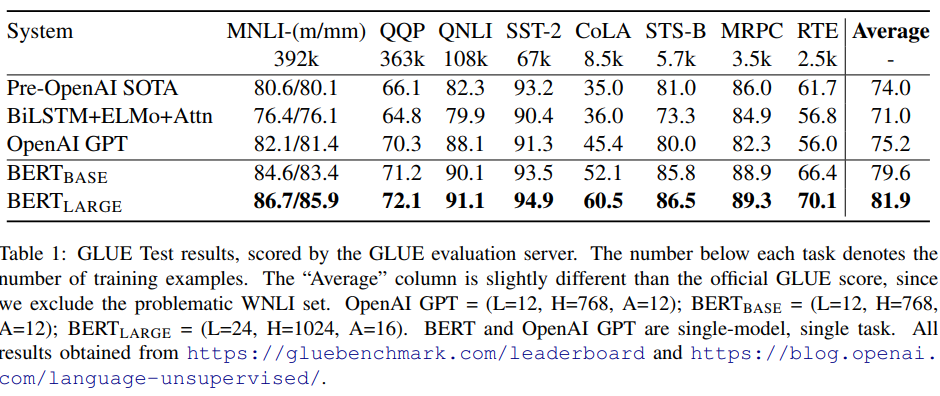
实验部分
实验部分是一片大好咯,各种牛逼。
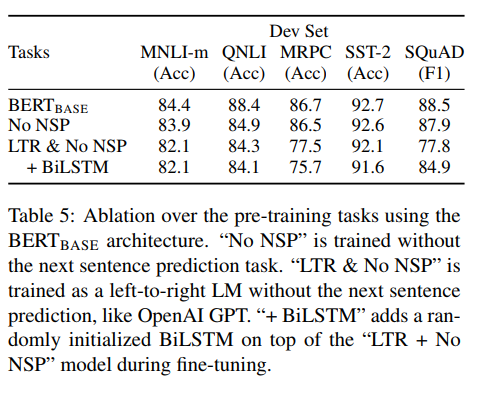
论文中也分析了不加Masked LM或不加Next Sentence Prediction预训练对模型结果的影响如下
关键代码分析
Masked token、Next Sentence
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2n_pred = min(max_pred, max(1, int(round(len(input_ids) * 0.15)))) # 15 % of tokens in one sentence
3cand_maked_pos = [i for i, token in enumerate(input_ids)
4 if token != word_dict['[CLS]'] and token != word_dict['[SEP]']]
5shuffle(cand_maked_pos)
6masked_tokens, masked_pos = [], []
7for pos in cand_maked_pos[:n_pred]:
8 masked_pos.append(pos)
9 masked_tokens.append(input_ids[pos])
10 if random() < 0.8: # 80%
11 input_ids[pos] = word_dict['[MASK]'] # make mask
12 elif random() < 0.5: # 10%
13 index = randint(0, vocab_size - 1) # random index in vocabulary
14 input_ids[pos] = word_dict[number_dict[index]] # replace
15
16
17if tokens_a_index + 1 == tokens_b_index and positive < batch_size/2:
18 batch.append([input_ids, segment_ids, masked_tokens, masked_pos, True]) # IsNext
19 positive += 1
20elif tokens_a_index + 1 != tokens_b_index and negative < batch_size/2:
21 batch.append([input_ids, segment_ids, masked_tokens, masked_pos, False]) # NotNext
22 negative += 1
23
24
ScaledDotProductAttention
2
3
4
5
6
7
8
2 scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
3 scores.masked_fill_(attn_mask, -1e9) #,注意把 padding部分的注意力去掉
4 attn = nn.Softmax(dim=-1)(scores)
5 context = torch.matmul(attn, V)
6 return context, attn
7
8
MultiHeadAttention
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2 def __init__(self):
3 super(MultiHeadAttention, self).__init__()
4 self.W_Q = nn.Linear(d_model, d_k * n_heads)
5 self.W_K = nn.Linear(d_model, d_k * n_heads)
6 self.W_V = nn.Linear(d_model, d_v * n_heads)
7 def forward(self, Q, K, V, attn_mask):
8 # q: [batch_size x len_q x d_model], k: [batch_size x len_k x d_model], v: [batch_size x len_k x d_model]
9 residual, batch_size = Q, Q.size(0)
10 # (B, S, D) -proj-> (B, S, D) -split-> (B, S, H, W) -trans-> (B, H, S, W)
11 q_s = self.W_Q(Q).view(batch_size, -1, n_heads, d_k).transpose(1,2) # q_s: [batch_size x n_heads x len_q x d_k]
12 k_s = self.W_K(K).view(batch_size, -1, n_heads, d_k).transpose(1,2) # k_s: [batch_size x n_heads x len_k x d_k]
13 v_s = self.W_V(V).view(batch_size, -1, n_heads, d_v).transpose(1,2) # v_s: [batch_size x n_heads x len_k x d_v]
14
15 attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1) # attn_mask : [batch_size x n_heads x len_q x len_k]
16
17 # context: [batch_size x n_heads x len_q x d_v], attn: [batch_size x n_heads x len_q(=len_k) x len_k(=len_q)]
18 context, attn = ScaledDotProductAttention()(q_s, k_s, v_s, attn_mask)
19 context = context.transpose(1, 2).contiguous().view(batch_size, -1, n_heads * d_v) # context: [batch_size x len_q x n_heads * d_v]
20 output = nn.Linear(n_heads * d_v, d_model)(context)
21 return nn.LayerNorm(d_model)(output + residual), attn # output: [batch_size x len_q x d_model]
22
23
BERT
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
2 def __init__(self):
3 super(PoswiseFeedForwardNet, self).__init__()
4 self.fc1 = nn.Linear(d_model, d_ff)
5 self.fc2 = nn.Linear(d_ff, d_model)
6
7 def forward(self, x):
8 # (batch_size, len_seq, d_model) -> (batch_size, len_seq, d_ff) -> (batch_size, len_seq, d_model)
9 return self.fc2(gelu(self.fc1(x)))
10
11class EncoderLayer(nn.Module):
12 def __init__(self):
13 super(EncoderLayer, self).__init__()
14 self.enc_self_attn = MultiHeadAttention()
15 self.pos_ffn = PoswiseFeedForwardNet()
16
17 def forward(self, enc_inputs, enc_self_attn_mask):
18 enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, enc_self_attn_mask) # enc_inputs to same Q,K,V
19 enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size x len_q x d_model]
20 return enc_outputs, attn
21
22class BERT(nn.Module):
23 def __init__(self):
24 super(BERT, self).__init__()
25 self.embedding = Embedding()
26 self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
27 self.fc = nn.Linear(d_model, d_model)
28 self.activ1 = nn.Tanh()
29 self.linear = nn.Linear(d_model, d_model)
30 self.activ2 = gelu
31 self.norm = nn.LayerNorm(d_model)
32 self.classifier = nn.Linear(d_model, 2)
33 # decoder is shared with embedding layer
34 embed_weight = self.embedding.tok_embed.weight
35 n_vocab, n_dim = embed_weight.size()
36 self.decoder = nn.Linear(n_dim, n_vocab, bias=False)
37 self.decoder.weight = embed_weight
38 self.decoder_bias = nn.Parameter(torch.zeros(n_vocab))
39
40 def forward(self, input_ids, segment_ids, masked_pos):
41 output = self.embedding(input_ids, segment_ids)
42 enc_self_attn_mask = get_attn_pad_mask(input_ids, input_ids)
43 for layer in self.layers:
44 output, enc_self_attn = layer(output, enc_self_attn_mask)
45 # output : [batch_size, len, d_model], attn : [batch_size, n_heads, d_mode, d_model]
46 # it will be decided by first token(CLS)
47 h_pooled = self.activ1(self.fc(output[:, 0])) # [batch_size, d_model]
48 logits_clsf = self.classifier(h_pooled) # [batch_size, 2]
49
50 masked_pos = masked_pos[:, :, None].expand(-1, -1, output.size(-1)) # [batch_size, maxlen, d_model]
51 h_masked = torch.gather(output, 1, masked_pos) # masking position [batch_size, len, d_model]
52 h_masked = self.norm(self.activ2(self.linear(h_masked)))
53 logits_lm = self.decoder(h_masked) + self.decoder_bias # [batch_size, maxlen, n_vocab]
54
55 return logits_lm, logits_clsf
56
57
58
