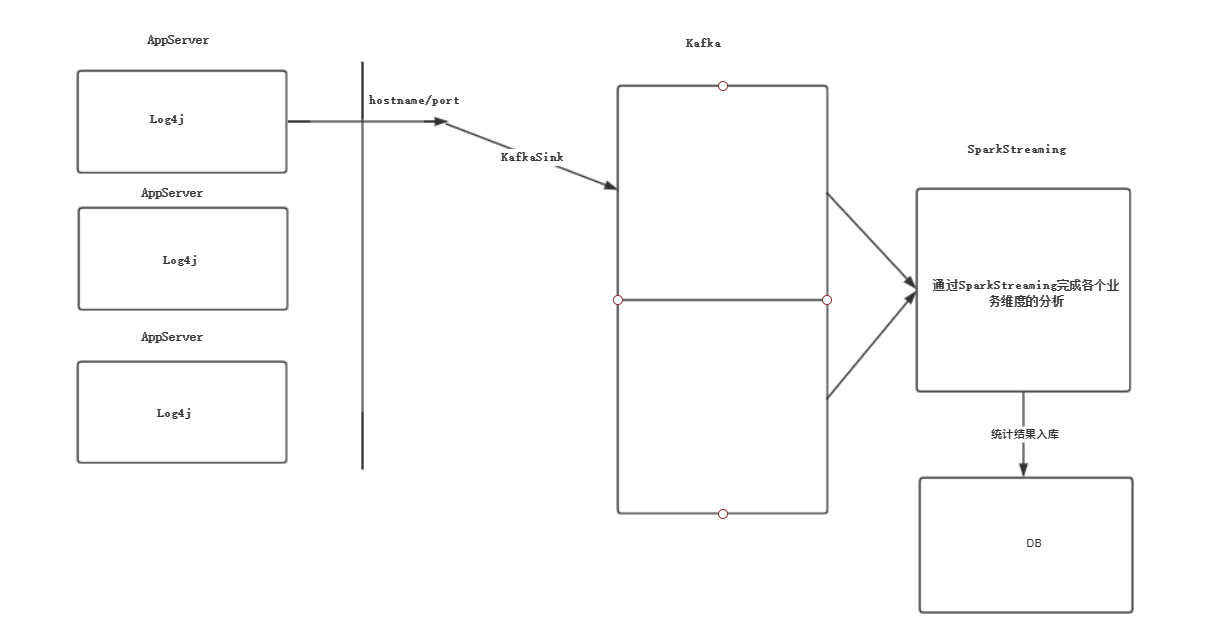
SparkStream整合Flume&Kafka打造通用的流处理平台
整个流程如图所示:

使用下面这段简单的代码模拟日志产生:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| 1import org.apache.log4j.Logger;
2
3/**
4 * Created by Zhaogw&Lss on 2019/11/27.
5 */
6public class LoggerGenerator {
7 private static Logger logger = Logger.getLogger(LoggerGenerator.class.getName());
8
9 public static void main(String[] args) throws Exception{
10 int index = 0;
11 while (true){
12 Thread.sleep(1000);
13 logger.info("values:" + index++);
14 }
15 }
16
17}
18
19
20 |
这里配置log4j日志打印格式
1
2
3
4
5
6
7
8
9
10
| 1# Configure logging for testing: optionally with log file
2log4j.rootLogger=INFO,stdout
3
4
5log4j.appender.stdout=org.apache.log4j.ConsoleAppender
6log4j.appender.stdout.target=System.out
7log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
8log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
9
10 |
运行程序的结果:
1
2
3
4
5
6
7
8
9
| 12019-11-27 10:55:24,873 [main] [LoggerGenerator] [INFO] - values:0
22019-11-27 10:55:25,910 [main] [LoggerGenerator] [INFO] - values:1
32019-11-27 10:55:26,912 [main] [LoggerGenerator] [INFO] - values:2
42019-11-27 10:55:27,913 [main] [LoggerGenerator] [INFO] - values:3
52019-11-27 10:55:28,915 [main] [LoggerGenerator] [INFO] - values:4
62019-11-27 10:55:29,918 [main] [LoggerGenerator] [INFO] - values:5
7......
8
9 |
1 整合日志输出到Flume
1.1 flume agent编写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| 1#streaming3.conf
2agent1.sources=avro-source
3agent1.channels=logger-channel
4agent1.sinks=log-sink
5
6#define soueces
7agent1.sources.avro-source.type = avro
8agent1.sources.avro-source.bind = 0.0.0.0
9agent1.sources.avro-source.port = 41414
10
11#define channel
12agent1.channels.logger-channel.type=memory
13
14#define sink
15agent1.sinks.log-sink.type=logger
16agent1.sources.avro-source.channels = logger-channel
17agent1.sinks.log-sink.channel = logger-channel
18
19 |
1.2 启动 flume agent
1
2
3
4
5
6
7
| 1flume-ng agent \
2 --name agent1 \
3 --conf conf \
4 --conf-file $FLUME_HOME/conf/streaming3.conf
5 -Dflume.root.logger=INFO,console &
6
7 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 1log4j.rootLogger=INFO,stdout,flume
2
3
4log4j.appender.stdout=org.apache.log4j.ConsoleAppender
5log4j.appender.stdout.target=System.out
6log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
7log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c] [%p] - %m%n
8
9
10log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
11log4j.appender.flume.Hostname = hadoop000
12log4j.appender.flume.Port = 41414
13log4j.appender.flume.UnsafeMode = true
14
15 |
注:这里需要新增下列依赖
1
2
3
4
5
6
7
| 1 <dependency>
2 <groupId>org.apache.flume.flume-ng-clients</groupId>
3 <artifactId>flume-ng-log4jappender</artifactId>
4 <version>1.6.0</version>
5 </dependency>
6
7 |
1.4 再次运行程序,在Flume中可以看到日志信息:
1
2
3
4
5
6
7
| 119/11/27 10:56:39 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1574823396036, flume.client.log4j.logger.name=LoggerGenerator, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: 76 61 6C 75 65 73 3A 30 values:0 }
219/11/27 10:56:39 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1574823397074, flume.client.log4j.logger.name=LoggerGenerator, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: 76 61 6C 75 65 73 3A 31 values:1 }
319/11/27 10:56:39 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1574823398076, flume.client.log4j.logger.name=LoggerGenerator, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: 76 61 6C 75 65 73 3A 32 values:2 }
419/11/27 10:56:39 INFO sink.LoggerSink: Event: { headers:{flume.client.log4j.timestamp=1574823399077, flume.client.log4j.logger.name=LoggerGenerator, flume.client.log4j.log.level=20000, flume.client.log4j.message.encoding=UTF8} body: 76 61 6C 75 65 73 3A 33 values:3 }
5
6
7 |
2 kafka zookeeper环境测试**
2.1启动kafka,需要先启动zk
1
2
3
4
5
6
7
8
9
| 1cd $ZK_HOME/bin
2./zkServer.sh start
3
4[hadoop@hadoop000 bin]$ jps -m
56368 Jps -m
66346 QuorumPeerMain /home/hadoop/app/zookeeper-3.4.5-cdh5.7.0/bin/../conf/zoo.cfg
7
8
9 |
2.2 启动kafka
1
2
3
4
5
6
7
8
9
10
11
12
| 1cd $KAFKA_HOME/bin
2./kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
3
4
5[hadoop@hadoop000 bin]$ ./kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
6[hadoop@hadoop000 bin]$ jps -m
76452 Jps -m
86391 Kafka /home/hadoop/app/kafka_2.11-0.9.0.0/config/server.properties
96346 QuorumPeerMain /home/hadoop/app/zookeeper-3.4.5-cdh5.7.0/bin/../conf/zoo.cfg
10
11
12 |
3.创建topic用于测试
1
2
3
| 1kafka-topics.sh --create --zookeeper hadoop000:2181 --replication-factor 1 --partitions 1 --topic streaming_topic
2
3 |
4.查看topic
1
2
3
| 1kafka-topics.sh --list --zookeeper hadoop000:2181
2
3 |
1
2
3
4
5
6
7
8
9
10
11
| 1[hadoop@hadoop000 bin]$ kafka-topics.sh --list --zookeeper hadoop000:2181
2hello_topic
3kafka_streaming
4kafka_streaming_topic
5my-replicated-topic
6my-replicated-topic1
7streaming_topic
8streamingtopic
9topic_hello
10
11 |
3 flume整合到kafka, 修改刚刚的配置文件streaming3.conf
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| 1#streaming4.conf
2agent1.sources=avro-source
3agent1.channels=logger-channel
4agent1.sinks=kafka-sink
5
6#define soueces
7agent1.sources.avro-source.type = avro
8agent1.sources.avro-source.bind = 0.0.0.0
9agent1.sources.avro-source.port = 41414
10
11#define channel
12agent1.channels.logger-channel.type=memory
13
14#define sink
15agent1.sinks.kafka-sink.type=org.apache.flume.sink.kafka.KafkaSink
16
17agent1.sinks.kafka-sink.topic = streaming_topic
18agent1.sinks.kafka-sink.brokerList = hadoop000:9092
19agent1.sinks.kafka-sink.requiredAcks = 1
20agent1.sinks.kafka-sink.flumeBatchSize = 20
21
22
23agent1.sources.avro-source.channels = logger-channel
24agent1.sinks.kafka-sink.channel = logger-channel
25
26 |
3.1 启动flume
1
2
3
4
5
6
7
| 1flume-ng agent \
2 --name agent1 \
3 --conf conf \
4 --conf-file $FLUME_HOME/conf/streaming4.conf
5 -Dflume.root.logger=INFO,console &
6
7 |
3.2 启动消费者
1
2
3
| 1kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic streaming_topic --from-beginning
2
3 |
可以看到Flume采集的消息被正常消费了
3.3 最后使用sparkStreaming消费
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| 1package com.zgw.spark
2
3
4import kafka.serializer.StringDecoder
5import org.apache.log4j.{Level, Logger}
6import org.apache.spark.SparkConf
7import org.apache.spark.streaming.kafka.KafkaUtils
8import org.apache.spark.streaming.{Seconds, StreamingContext}
9
10/**
11 * Created by Zhaogw&Lss on 2019/11/27.
12 */
13object KafkaStreamingApp {
14 def main(args: Array[String]): Unit = {
15 if (args.length!=2){
16 System.err.print("Usage:KafkaReceiverWordCount <brokers> <topic> ")
17 System.exit(1)
18 }
19 /*val Array(hostname,port) = args*/
20
21 val Array(brokers,topics) = args
22
23 val sc: SparkConf = new SparkConf().setMaster("local[3]").setAppName("KafkaReceiverWordCount").set("spark.testing.memory", "2147480000")
24
25 Logger.getLogger("org").setLevel(Level.ERROR)
26 //创建StreamingContext两个参数 SparkConf和batch interval
27 val ssc = new StreamingContext(sc, Seconds(5))
28
29 val topicSet = topics.split(",").toSet
30
31 val kafkaParams = Map[String,String]("metadata.broker.list" -> brokers)
32
33 val messages = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaParams,topicSet)
34
35
36 messages.map(_._2).count().print()
37
38 ssc.start()
39
40 ssc.awaitTermination()
41 }
42}
43
44 |
正常消费:这里我只打印出了记录的条数
1
2
3
4
5
6
7
8
| 1-------------------------------------------
2Time: 1574833515000 ms
3-------------------------------------------
4100
5
6-------------------------------------------
7
8 |