一、商业理解
1、网络数据分析的数据来源:Server保存的网络日志
2、网络数据分析的分类
- 网站级别
• 对网站级别的数据挖掘,通常会将网站作为一个整体进行分析,主要任务包括:
– 访问网站的用户识别;
– 网站购买情况分析;
– 网站销售金额分析;
– 网站访问的错误情况分析。
• 通常情况下,只需要根据网络日志就可以进行网站级别的数据分析工作。
- 页面级别
• 对于页面级别的数据挖掘,还要关注各个页面的访问情况,主要回答如下问题:
– 哪些网页访问量最大;
– 访问者进入哪个网页;
– 访问者退出哪个网页。
• 同样,只需要根据网络日志就可以进行网页级别的数据分析工作。
- 访问级别
• 从访问事件的角度进行数据分析工作,主要回答如下问题:
– 网站访问的逗留时间如何;
– 哪些网站\网页会在一次访问中被依次访问 ,访问的次序如何;
– 哪些网站\网页的访问容易最终导致购买行为发生。
• 主要依赖于网络日志数据,结合Cookie数据效果会更好。
- 访问者级别
• 访问者级别与访问级别的网络数据分析问题类似,但它们针对的对象不同。主要任务包括:
– 特定访问者的网站访问情况;
– 识别不同的访问是否由同一个访问者发起;
– 对访问者不同时间的访问行为做进一步的分析与挖掘。
• 除了需要网络日志数据和Cookie数据外,通常还需要网站注册信息等数据。
二、数据理解
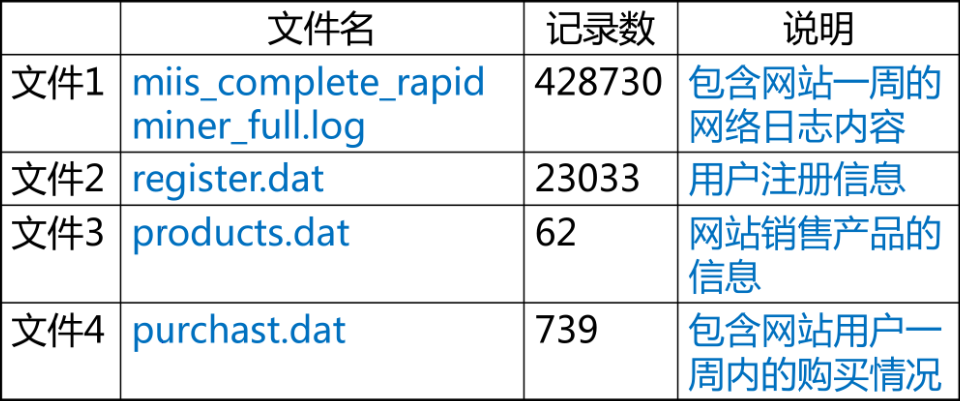
三、数据准备
- 识别访问用户
根据日志识别不同的访问(Visit)及访问者(Visitor),基本假设:
• 同一访问(Visit)
– IP地址(IPAddress)相同
– 浏览器(UserAgent)相同
– 并且操作间隔不超过30分钟(1800秒)
• 同一访问者(Visitor)
– Cookie相同
- 提取用户访问习惯数据
日志信息经过整理提取出用户访问习惯数据
用户访问习惯数据包括:
1.用户名(username)和订单信息(order_no)
2.访问时间(visit_time)和每页停留时间(time_per_page)
3.访问第1页到第2页之间(time_gap1)和第2页到第3页之间(time_gap2)的时间间隔
4.顶级目录信息(first_dir)
5.访问来源信息(Referer)
- 合并网络日志与相关数据
四、建立模型
4.1 访问用户购买行为预测 ——访问级别数据分析
4.2 访问者访问网页细分模型 ——访问者级别数据分析
4.3 已购买产品特征模型
4.4�用聚类分析建立推荐模型
五、 模型应用
使用聚类分析结果向用户推荐产品
