HashMap 和 HashTable 的区别(源码层)
1、HashMap 是非线程安全的,HashTable 是线程安全的。
2、HashMap 的键和值都允许有 null 值存在,而 HashTable 则不行。
3、因为线程安全的问题,HashMap 效率比 HashTable 的要高。
HashMap put(K key, V value) 方法的内部存储结构(jdk 1.7)
jdk 1.7 中 HashMap 内部采用 单向链表+数组的方式存储数据
1、HashMap<String, Object> hashMap = new HashMap<String, Object>(); 的时候会通过构造函数初始化 map 的大小和扩容因子。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2public HashMap() {
3 this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR );
4}
5
6public HashMap(int initialCapacity, float loadFactor) {
7 if (initialCapacity < 0)
8 throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
9 if (initialCapacity > MAXIMUM_CAPACITY)
10 initialCapacity = MAXIMUM_CAPACITY;
11 if (loadFactor <= 0 || Float.isNaN(loadFactor))
12 throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
13
14 this.loadFactor = loadFactor;
15 threshold = initialCapacity;
16 init();
17}
18
2、map 的初始化大小和扩容因子设置完成之后,map 准备就绪,调用 map.put() 方法向 map 中添加元素。在 put 方法中,如果当前 table(也就是 entry 数组)为空,就在 inflateTable 方法中初始化 table,
2
3
4
5
6
7
8
2 if (table == EMPTY_TABLE) {
3 inflateTable(threshold);
4 }
5 ...
6 return null;
7}
8
3、在 inflateTable 方法中通过 roundUpToPowerOf2 方法计算当前要初始化的大小是否大于等于 MAXIMUM_CAPACITY(2的 30次方),如果大于等于就设置成 MAXIMUM_CAPACITY 的值,不大于就调用Integer.highestOneBit 方法计算初始化的大小。
highestOneBit 方法简单的说就是:
3.1、如果一个数是0, 则返回0;
3.2、如果是负数, 则返回 -2147483648;
3.3、如果是正数, 则返回的是比参数小的且最靠近参数的 2 的N次方;例如:参数是 17 则返回 16;参数是 15 则返回 8;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2 // Find a power of 2 >= toSize
3 int capacity = roundUpToPowerOf2(toSize);
4
5 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
6 table = new Entry[capacity];
7 initHashSeedAsNeeded(capacity);
8}
9
10private static int roundUpToPowerOf2(int number) {
11 // assert number >= 0 : "number must be non-negative";
12 return number >= MAXIMUM_CAPACITY
13 ? MAXIMUM_CAPACITY
14 : ( number > 1) ? Integer.highestOneBit(( number - 1) << 1) : 1;
15}
16
4、初始化完成之后再回到 put 方法中,往下看会看到判断 key 值是否是空值,当 key 是空值的时候,调用 putForNullKey 处理。首先取出下标为0的元素,如果当前元素是空元素,就将当前key的 hashcode 设置为0,放在 table 下标为 0 的位置。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2 ...
3 if (key == null)
4 return putForNullKey(value);
5 ...
6 return null;
7}
8
9private V putForNullKey(V value) {
10 for (Entry<K,V> e = table[0]; e != null; e = e.next) {
11 if (e.key == null) {
12 V oldValue = e.value;
13 e.value = value;
14 e.recordAccess(this);
15 return oldValue ;
16 }
17 }
18 modCount++;
19 addEntry(0, null, value , 0);
20 return null;
21}
22
5、如果不是空的key,先计算 key 的 hash 值,然后调用 indexFor 方法根据 hash 值和 table 的长度计算出当前的 key 存储在 table 中的位置 i 。计算完位置之后,再取出位置 i 处是否已经有数据,如果有数据并且数据中也有相同的 hash 并且 key 也相同的时候,就将当前的值替换掉旧的值并返回旧的值。循环完之后没有相同的 hash key 的时候,就调用 addEntry 方法向 table 位置 i 处添加元素。添加规则是将当前 key 存放在位置 i 处链表的最顶部。
hash() 这个方法计算过程还没弄明白,希望弄明白的大神帮忙指点指点
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
2 ....
3 int hash = hash(key); // 计算 key 的 hash 值,这一步是关键,暂时还没看明白计算方法
4 int i = indexFor(hash, table.length); // 计算得到的 hash 应该存放在 map entry 的哪个下标的位置
5 for (Entry<K,V> e = table[i]; e != null; e = e .next) {
6 Object k;
7 if (e.hash == hash && ((k = e.key) == key || key.equals( k))) {
8 V oldValue = e.value;
9 e.value = value;
10 e.recordAccess(this);
11 return oldValue ;
12 }
13 }
14
15 modCount++;
16 addEntry(hash, key , value, i);
17 return null;
18}
19
20
21final int hash(Object k) {
22 int h = hashSeed;
23 if (0 != h && k instanceof String) {
24 return sun.misc.Hashing.stringHash32((String) k);
25 }
26
27 h ^= k.hashCode();
28
29 h ^= (h >>> 20) ^ (h >>> 12);
30 return h ^ (h >>> 7) ^ (h >>> 4);
31}
32
33static int indexFor(int h, int length ) {
34 return h & (length-1);
35}
36
6、添加的时候判断当前位置 i 是否已经大于要扩容的极限(总长度 * 扩容因子),扩容是当前 table 大小的 2 倍。扩容之后重新"散列掩码值 ",然后循环旧 table,将每一个元素都重新计算存储在扩容之后新 table 中的哪个位置上。转换完之后,再计算下次要扩容的极限大小是多少。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
2 if ((size >= threshold) && (null != table[bucketIndex])) {
3 // 扩容
4 resize(2 * table.length);
5 hash = (null != key) ? hash(key) : 0;
6 bucketIndex = indexFor(hash, table.length);
7 }
8
9 // 将新 put 进来的 key/value 放入扩容后的 map 对应的 table 中
10 createEntry(hash, key, value, bucketIndex);
11}
12
13// 扩容
14void resize(int newCapacity) {
15 Entry[] oldTable = table ;
16 int oldCapacity = oldTable.length;
17 if (oldCapacity == MAXIMUM_CAPACITY) {
18 threshold = Integer.MAX_VALUE;
19 return;
20 }
21 Entry[] newTable = new Entry[newCapacity];
22 // initHashSeedAsNeeded 用来初始化哈希值
23 // transfer 循环旧的 map 中的数据,存放到扩容后的 map 中
24 transfer(newTable, initHashSeedAsNeeded(newCapacity));
25 table = newTable ;
26 threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
27}
28
29// 初始化哈希值
30final boolean initHashSeedAsNeeded(int capacity) {
31 boolean currentAltHashing = hashSeed != 0;
32 boolean useAltHashing = sun.misc.VM.isBooted() &&
33 (capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
34 boolean switching = currentAltHashing ^ useAltHashing;
35 if (switching) {
36 hashSeed = useAltHashing
37 ? sun.misc.Hashing.randomHashSeed(this)
38 : 0;
39 }
40 return switching;
41}
42
43// 循环旧的 map 中的数据,存放到扩容后的 map 中
44void transfer(Entry[] newTable, boolean rehash) {
45 int newCapacity = newTable.length;
46 for (Entry<K,V> e : table) {
47 while(null != e) {
48 Entry<K,V> next = e.next;
49 if (rehash) {
50 e.hash = null == e.key ? 0 : hash(e.key);
51 }
52 int i = indexFor (e.hash, newCapacity);
53 e.next = newTable[i];
54 newTable[i] = e;
55 e = next ;
56 }
57 }
58}
59
60// 将新 put 进来的 key/value 放入扩容后的 map 对应的 table 中
61void createEntry(int hash, K key, V value, int bucketIndex) {
62 Entry<K,V> e = table[bucketIndex];
63 table[bucketIndex] = new Entry<>(hash, key, value, e);
64 size++;
65}
66
HashMap get(Object key) 方法的内部存储结构(jdk 1.7)
1、get 方法比较简单,进来之后先判断是否 key 是否是 null,是 null 就特殊处理,不是就常规处理并返回这个 key 对应的值。V 是泛型,声明 HashMap 的时候中的 value 类型。
2
3
4
5
6
7
8
2 if (key == null)
3 return getForNullKey();
4 Entry<K,V> entry = getEntry(key );
5
6 return null == entry ? null : entry .getValue();
7}
8
2、当 key 是 null 的情况,先判断当前 table 的 size 是否大于 0,大于 0 就继续,否则返回 null。然后再直接获取 hashMap 中 table(Entry) 下标为 0 的位置的链表,循环这个链表,依次判断每个元素的 key 是否为 null,为 null 就返回对应的值。
2
3
4
5
6
7
8
9
10
11
2 if (size == 0) {
3 return null;
4 }
5 for (Entry<K,V> e = table[0]; e != null; e = e.next) {
6 if (e.key == null)
7 return e.value;
8 }
9 return null;
10}
11
3、key 不为 null 的情况,同样是先判断当前 table 的 size 是否大于 0,大于 0 就继续,否则返回 null。然后再计算要查找 key 的 hash 码,通过 hash 码和 table 的长度计算出这个 key 对应 table 的下标,得到下标之后取出 hashMap 中对应下标的 table(Entry) 链表,循环这个链表,依次判断每个元素的 key 是否与当前 key 相同 并且 hash 码也相同,相同就返回对应的值,不相同就返回 null。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2 if (size == 0) {
3 return null;
4 }
5
6 int hash = (key == null) ? 0 : hash(key);
7 for (Entry<K,V> e = table[indexFor(hash, table.length)];
8 e != null;
9 e = e.next) {
10 Object k;
11 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
12 return e ;
13 }
14 return null;
15}
16
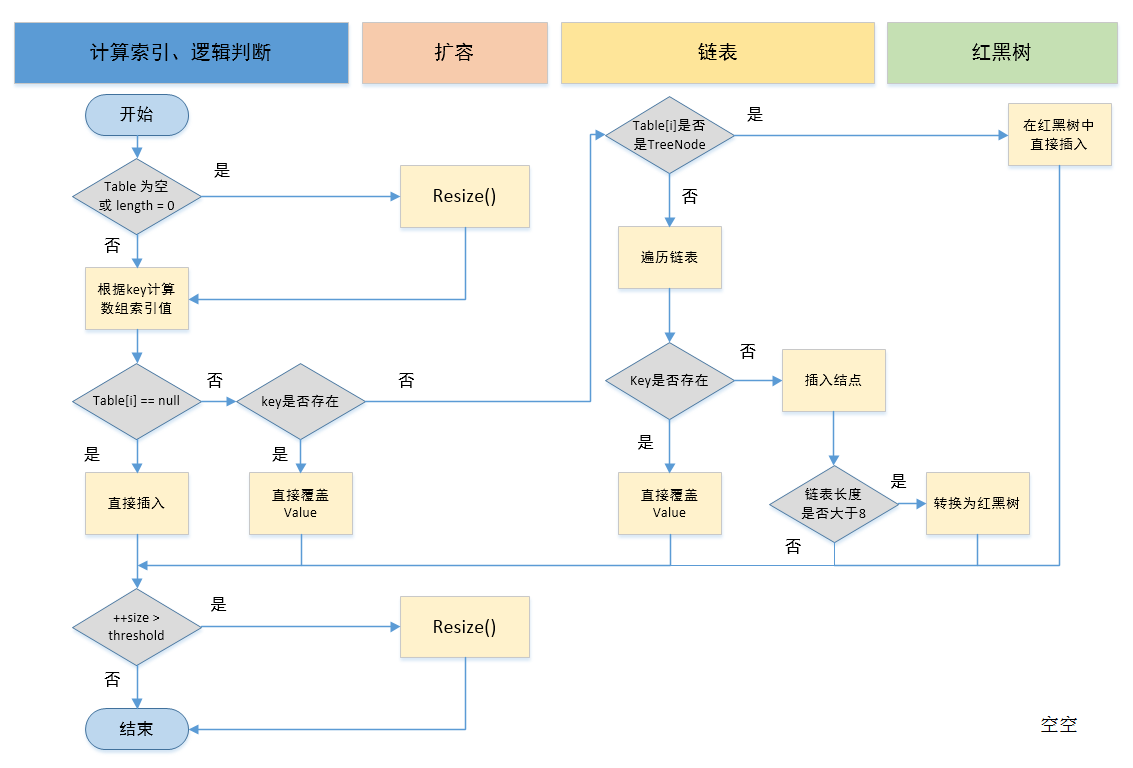
HashMap put(K key, V value) 的内部存储结构(jdk 1.8)
文末附 pu 方法的执行流程图
jdk 1.8 中 HashMap 内部采用 树+数组 的方式存储数据
1、HashMap<String, Object> hashMap = new HashMap<String, Object>(); 的时候会通过构造函数设置 map 的扩容因子,这里不在设置 map 的初始化大小,而是在 put() 方法里第一次 put 的时候初始化大小
2
3
4
5
6
7
2static final float DEFAULT_LOAD_FACTOR = 0.75f;
3
4public HashMap() {
5 this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
6}
7
2、put 方法,先计算 key 的 hash 值,调用 putVal() 方法进行设置值
2
3
4
2 return putVal(hash(key), key, value, false, true);
3}
4
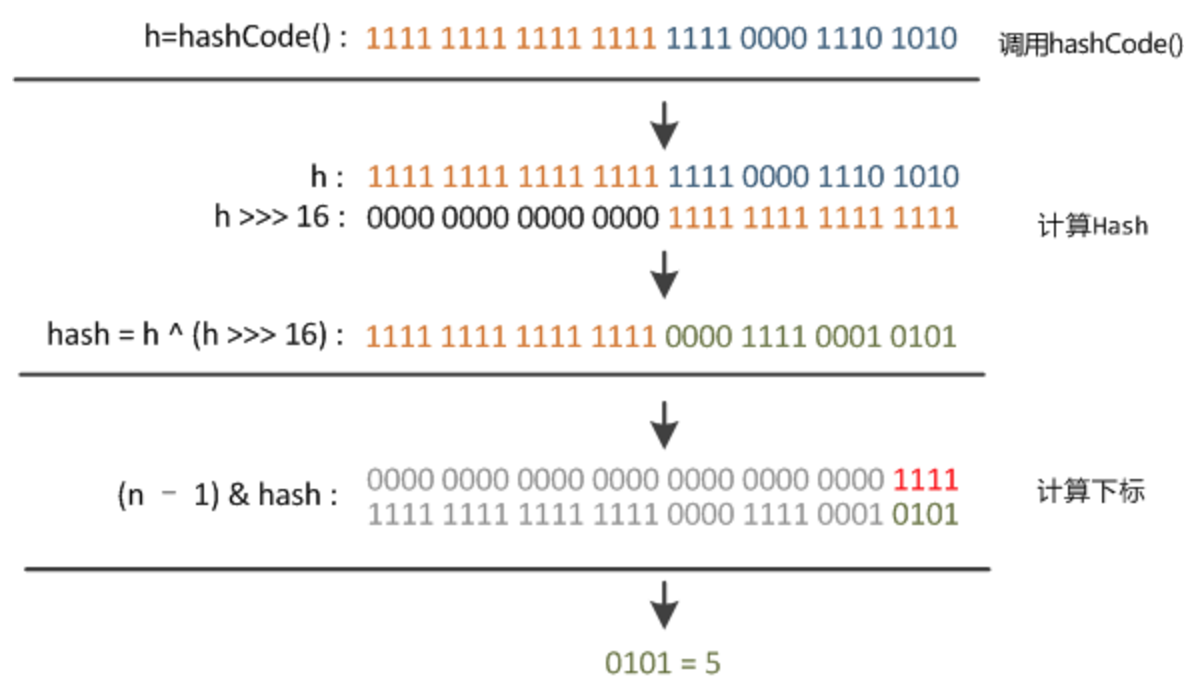
3、首先看 hash(Object key) 方法,该方法用来计算 key 的 hash 值。可以看出 key 为空的时候 hash 为 0。(h = key.hashCode()) ^ (h >>> 16) 第一步 取 key 的 hash 值,第二步 h ^ (h >>> 16) 高位‘与’运算(底层的位移和异或运算效率要高于加减乘除取模等效率)因为 hashcode 对应的二进制是 32 位,无符号右移 16 位,那生成的就是16位0加原高位的16位值,就相当于把 int 对半分开了,异或计算也就变成了高16位和低16位进行异或,原高16位不变。这么干主要用于当hashmap 数组比较小的时候所有bit都参与运算了,防止hash冲突太大。
2
3
4
5
2 int h;
3 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
4}
5
4、接下来看 putVal() 方法向 map 中添加数据,
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
2 Node<K,V>[] tab; Node<K,V> p; int n, i;
3 // 第一次 put 进来的时候 tab 为空
4 if ((tab = table) == null || (n = tab.length) == 0)
5 n = (tab = resize()).length; // resize() 可以扩容也可以初始化 map
6
7 // n 是数组的长度 length,当length 总是 2 的 n 次方时,(n - 1) & hash 运算等价于对 length 取模,也就是 hash % length
8 // tab 是 map 中数组的大小,通过 & 计算,得到插入的下标,判断该下标是否已经存在元素数据
9 if ((p = tab[i = (n - 1) & hash]) == null)
10 // 如果当前位置为空,就放入新的 Node 数据,
11 tab[i] = newNode(hash, key, value, null);
12 else {
13 // hash 冲突了(对应下标的位置已经存在元素)
14
15 Node<K,V> e; K k;
16
17 // hash 值相同并且 key 的地址和值也相同,说明 key 重复了
18 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
19 // 将 p 赋值给 e 后面用来获取旧数据的操作
20 e = p;
21
22 // hash 值相同,如果以存在的值是个树类型的,则将给定的键值对和该值关联
23 else if (p instanceof TreeNode)
24 // 具体看下面第 6 步
25 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
26
27 // 如果key不相同,只是hash冲突,并且不是树,则是链表
28 else {
29 for (int binCount = 0; ; ++binCount) {
30 // 循环到链表的最后一个元素的时候,将新值追加到链表的末端
31 if ((e = p.next) == null) {
32 p.next = newNode(hash, key, value, null);
33 // 如果树的阀值大于等于7,也就是,链表长度达到了8(从0开始)
34 if (binCount >= TREEIFY_THRESHOLD - 1)
35 // 如果链表长度达到了8,且数组长度小于64,那么就重新散列,重新散列会拆分链表,使得链表变短提高性能,如果大于64,只能将链表变为红黑树
36 // 具体看下面第 5 步
37 treeifyBin(tab, hash);
38 break;
39 }
40
41 // 循环链表过程中有 key 和目标 key 相同的就直接结束
42 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
43 break;
44 // 如果给定的 hash 值不同或者key不同
45 // 将 next 值赋给 p,为下次循环做铺垫
46 p = e;
47 }
48 }
49 // 通过上面的逻辑,如果 e 不是 null,表示:该元素存在了(也就是他们呢 key 相等)
50 if (e != null) { // existing mapping for key
51 V oldValue = e.value;
52
53 // 如果 onlyIfAbsent 是 true,就不要改变已有的值,这里我们是false。
54 if (!onlyIfAbsent || oldValue == null)
55 // 新值替换旧值
56 e.value = value;
57 // 什么都不操作
58 afterNodeAccess(e);
59 return oldValue;
60 }
61 }
62 // 如果e== null,需要增加 modeCount 变量,为迭代器服务。
63 ++modCount;
64 // 数组长度大于扩容阀值
65 if (++size > threshold)
66 // 数组扩容
67 resize();
68 // HashMap 中什么都不做
69 afterNodeInsertion(evict);
70 return null;
71}
72
接下来的5、6步(不分先后,这里只是和上面 putVal() 方法里面标注的步骤对应),是红黑树的构造、平衡(左旋、右旋)过程,由于是对树的操作,代码实现逻辑比较复杂难懂,楼主还没弄明白,所以不想了解的也可以跳过
5、在上一步中向链表中添加数据之后,如果此链表长度大于转换成树的限定值,就会调用 treeifyBin() 方法将此链表转换成树,下面详细分析 treeifyBin() 方法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
2
3final void treeifyBin(Node<K,V>[] tab, int hash) {
4 // n 是当前数组的长度,index hash 和 数组长度计算之后的下标位置,e 是链表中的节点每次取出一个转换成 TreeNode 用
5 int n, index; Node<K,V> e;
6 // 当前数组为空 或者 数组的长度小于 64,就调用 resize() 方法扩容,扩容之后重新计算 hash
7 if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
8 resize();
9 // 数组长度大于 64 了就只能将链表转换成树
10 else if ((e = tab[index = (n - 1) & hash]) != null) {
11 // 经过下面代码分析,hd 是头节点, tl 是临时变量,每次都指向最后一个节点
12 TreeNode<K,V> hd = null, tl = null;
13 // 通过循环将链表中的 Node 类型 转换成 TreeNode 类型,并还保持链表的结构
14 do {
15 // 将链表中的节点转换成树节点,replacementTreeNode() 方法内通过构造方法产生一个新的树节点
16 TreeNode<K,V> p = replacementTreeNode(e, null);
17 if (tl == null)
18 hd = p;
19 else {
20 p.prev = tl;
21 tl.next = p;
22 }
23 tl = p;
24 } while ((e = e.next) != null);
25 // 将构造成 TreeNode 的链表 hd 赋值到数组中对应下标的位置并且数据不为空
26 if ((tab[index] = hd) != null)
27 // 将链表转换成树结构
28 hd.treeify(tab);
29 }
30}
31
32treeify 方法是 HashMap 内部静态常量类 TreeNode 中的方法
33
34final void treeify(Node<K,V>[] tab) {
35 TreeNode<K,V> root = null;
36
37 // 这层循环的 TreeNode 链表
38 // this 是转换后的 TreeNode 链表中的第一个元素
39 for (TreeNode<K,V> x = this, next; x != null; x = next) {
40 next = (TreeNode<K,V>)x.next;
41 x.left = x.right = null;
42 // 如果根节点为空,说明 x 是循环的第一个节点
43 if (root == null) {
44 x.parent = null;
45 // 将 x 节点标记为黑色并设置为根节点
46 x.red = false;
47 root = x;
48 }
49 else {
50 // 已有根节点,需要把循环的节点设置为根节点的子节点
51
52 K k = x.key;
53 int h = x.hash;
54 Class<?> kc = null;
55
56 // 这层循环的是构造成的树,当前节点的左右子节点都不为空的时候就往下循环。无限循环直到 break 退出
57 for (TreeNode<K,V> p = root;;) {
58 // dir 左节点、右节点 的标记, ph 循环到的节点的 hash 值
59 int dir, ph;
60 K pk = p.key;
61 if ((ph = p.hash) > h)
62 dir = -1;
63 else if (ph < h)
64 dir = 1;
65 // 通过循环到的节点的 key 构造一个比较器,然后和要插入的节点的 key 进行比较
66 else if ((kc == null &&
67 (kc = comparableClassFor(k)) == null) ||
68 (dir = compareComparables(kc, k, pk)) == 0)
69 dir = tieBreakOrder(k, pk);
70
71 // p 是当前循环的节点
72 TreeNode<K,V> xp = p;
73 // 判断 将插入节点设置成当前节点的左节点还是右节点
74 if ((p = (dir <= 0) ? p.left : p.right) == null) {
75 // 如果左节点或右节点不为空,就将要插入节点的父节点设置成当前循环到的节点
76 x.parent = xp;
77 // dir 小于等于 0 的时候,插入的节点设置成当前循环到的节点的左节点
78 if (dir <= 0)
79 xp.left = x;
80 else
81 // dir 大于 0 就设置成右节点
82 xp.right = x;
83 // 新插入一个节点之后,树之前的平衡被破坏,下面方法用来平衡树
84 root = balanceInsertion(root, x);
85 break;
86 }
87 }
88 }
89 }
90 // 确保树的根节点是第一个节点
91 moveRootToFront(tab, root);
92}
93
94// 从要插入的节点 x 开始遍历树进行平衡,这方法还没理解透彻,暂时不加注释了
95static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
96 TreeNode<K,V> x) {
97 x.red = true;
98 for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
99 if ((xp = x.parent) == null) {
100 x.red = false;
101 return x;
102 }
103 else if (!xp.red || (xpp = xp.parent) == null)
104 return root;
105 if (xp == (xppl = xpp.left)) {
106 if ((xppr = xpp.right) != null && xppr.red) {
107 xppr.red = false;
108 xp.red = false;
109 xpp.red = true;
110 x = xpp;
111 }
112 else {
113 if (x == xp.right) {
114 root = rotateLeft(root, x = xp);
115 xpp = (xp = x.parent) == null ? null : xp.parent;
116 }
117 if (xp != null) {
118 xp.red = false;
119 if (xpp != null) {
120 xpp.red = true;
121 root = rotateRight(root, xpp);
122 }
123 }
124 }
125 }
126 else {
127 if (xppl != null && xppl.red) {
128 xppl.red = false;
129 xp.red = false;
130 xpp.red = true;
131 x = xpp;
132 }
133 else {
134 if (x == xp.left) {
135 root = rotateRight(root, x = xp);
136 xpp = (xp = x.parent) == null ? null : xp.parent;
137 }
138 if (xp != null) {
139 xp.red = false;
140 if (xpp != null) {
141 xpp.red = true;
142 root = rotateLeft(root, xpp);
143 }
144 }
145 }
146 }
147 }
148}
149
6、如果 hash 冲突的位置存在的已经是树,就执行下面方法向树中添加一个节点,大体执行流程和第 5 步中构造树的过程类似
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
2 Class<?> kc = null;
3 boolean searched = false;
4 TreeNode<K,V> root = (parent != null) ? root() : this;
5 for (TreeNode<K,V> p = root;;) {
6 int dir, ph; K pk;
7 if ((ph = p.hash) > h)
8 dir = -1;
9 else if (ph < h)
10 dir = 1;
11 else if ((pk = p.key) == k || (k != null && k.equals(pk)))
12 return p;
13 else if ((kc == null &&
14 (kc = comparableClassFor(k)) == null) ||
15 (dir = compareComparables(kc, k, pk)) == 0) {
16 if (!searched) {
17 TreeNode<K,V> q, ch;
18 searched = true;
19 if (((ch = p.left) != null &&
20 (q = ch.find(h, k, kc)) != null) ||
21 ((ch = p.right) != null &&
22 (q = ch.find(h, k, kc)) != null))
23 return q;
24 }
25 dir = tieBreakOrder(k, pk);
26 }
27
28 TreeNode<K,V> xp = p;
29 if ((p = (dir <= 0) ? p.left : p.right) == null) {
30 Node<K,V> xpn = xp.next;
31 TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
32 if (dir <= 0)
33 xp.left = x;
34 else
35 xp.right = x;
36 xp.next = x;
37 x.parent = x.prev = xp;
38 if (xpn != null)
39 ((TreeNode<K,V>)xpn).prev = x;
40 moveRootToFront(tab, balanceInsertion(root, x));
41 return null;
42 }
43 }
44}
45
HashMap get(Object key) 方法的内部存储结构(jdk 1.8)
1、首先调用 hash() 方法计算 key 的 hash 值,计算方法同 put() 方法的计算过程
2
3
4
5
2 Node<K,V> e;
3 return (e = getNode(hash(key), key)) == null ? null : e.value;
4}
5
2、get 的过程比较简单,在代码里说明
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2 Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
3 // 数组不为空 并且 计算出的下标位置数据也不为空,就取出对应下标位置的数据元素
4 if ((tab = table) != null && (n = tab.length) > 0 &&
5 (first = tab[(n - 1) & hash]) != null) {
6 // 第一个元素的 hash 和查找的 hash 相同,并且 key 值和地址也都相等,说明找到了元素直接返回即可
7 if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k))))
8 return first;
9 // 上面的条件都不成立,取出 first 的下一个元素进行遍历
10 if ((e = first.next) != null) {
11 // 下一个元素是树,就使用树的查找方法进行查找
12 if (first instanceof TreeNode)
13 return ((TreeNode<K,V>)first).getTreeNode(hash, key);
14 // 是链表,就循环挨个往下查找,直到查找到目标元素为止
15 do {
16 if (e.hash == hash &&
17 ((k = e.key) == key || (key != null && key.equals(k))))
18 return e;
19 } while ((e = e.next) != null);
20 }
21 }
22 return null;
23}
24
putVal 方法执行流程