使用Dubbo进行远程调用实现服务交互,它支持多种协议,如Hessian、HTTP、RMI、Memcached、Redis、Thrift等等。由于Dubbo将这些协议的实现进行了封装了,无论是服务端(开发服务)还是客户端(调用服务),都不需要关心协议的细节,只需要在配置中指定使用的协议即可,从而保证了服务提供方与服务消费方之间的透明。
另外,如果我们使用Dubbo的服务注册中心组件,这样服务提供方将服务发布到注册的中心,只是将服务的名称暴露给外部,而服务消费方只需要知道注册中心和服务提供方提供的服务名称,就能够透明地调用服务,后面我们会看到具体提供服务和消费服务的配置内容,使得双方之间交互的透明化。
示例场景
我们给出一个示例的应用场景:
服务方提供一个搜索服务,对服务方来说,它基于SolrCloud构建了搜索服务,包含两个集群,ZooKeeper集群和Solr集群,然后在前端通过Nginx来进行反向代理,达到负载均衡的目的。
服务消费方就是调用服务进行查询,给出查询条件(满足Solr的REST-like接口)。
应用设计
基于上面的示例场景,我们打算使用ZooKeeper集群作为服务注册中心。注册中心会暴露给服务提供方和服务消费方,所以注册服务的时候,服务先提供方只需要提供Nginx的地址给注册中心,但是注册中心并不会把这个地址暴露给服务消费方,如图所示:
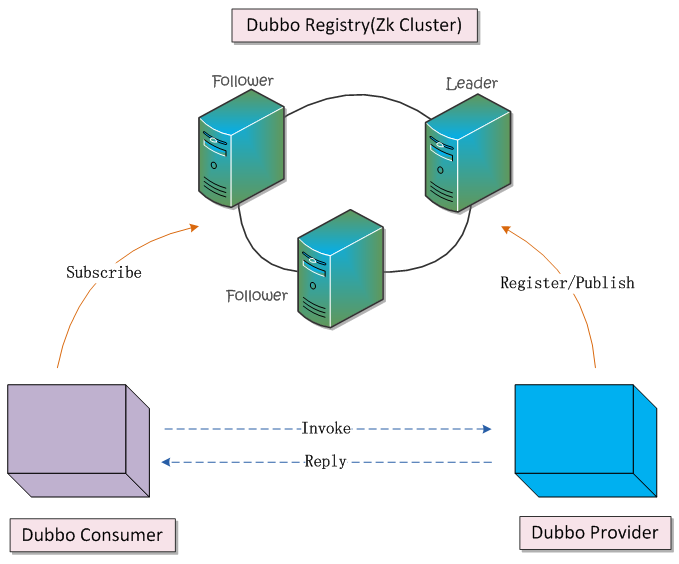
我们先定义一下,通信双方需要使用的接口,如下所示:
2
3
4
5
6
7
8
9
10
2public interface SolrSearchService {
3 String search(String collection, String q, ResponseType type, int start, int rows);
4
5 public enum ResponseType {
6 JSON,
7 XML
8 }
9}
10
基于上图中的设计,下面我们分别详细说明Provider和Consumer的设计及实现。
- Provider服务设计
Provider所发布的服务组件,包含了一个SolrCloud集群,在SolrCloud集群前端又加了一个反向代理层,使用Nginx来均衡负载。Provider的搜索服务系统,设计如下图所示:
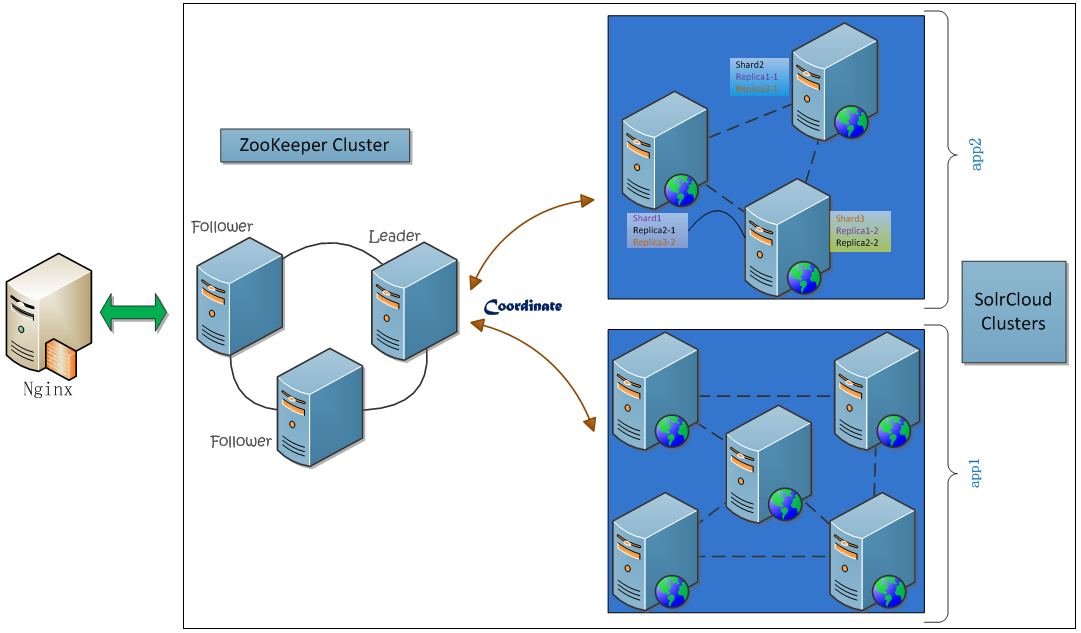
上图中,实际Nginx中将请求直接转发内部的Web Servers上,在这个过程中,使用ZooKeeper来进行协调:从多个分片(Shard)服务器上并行搜索,最后合并结果。我们看一下Nginx配置的内容片段:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
2worker_processes 4;
3error_log /var/log/nginx/error.log warn;
4pid /var/run/nginx.pid;
5events {
6 worker_connections 1024;
7}
8
9http {
10 include /etc/nginx/mime.types;
11 default_type application/octet-stream;
12 log_format main '$remote_addr - $remote_user [$time_local] "$request" '
13 '$status $body_bytes_sent "$http_referer" '
14 '"$http_user_agent" "$http_x_forwarded_for"';
15
16 access_log /var/log/nginx/access.log main;
17
18 sendfile on;
19 #tcp_nopush on;
20 keepalive_timeout 65;
21
22 #gzip on;
23
24 upstream master {
25 server slave1:8888 weight=1;
26 server slave4:8888 weight=1;
27 server slave6:8888 weight=1;
28 }
29
30 server {
31 listen 80;
32 server_name master;
33 location / {
34 root /usr/share/nginx/html/solr-cloud;
35 index index.html index.htm;
36 proxy_pass http://master;
37 include /home/hadoop/servers/nginx/conf/proxy.conf;
38 }
39 }
40
41}
42
一共配置了3台Solr服务器,因为SolrCloud集群中每一个节点都可以接收搜索请求,然后由整个集群去并行搜索。最后,我们要通过Dubbo服务框架来基于已有的系统来开发搜索服务,并通过Dubbo的注册中心来发布服务。
首先需要实现服务接口,实现代码如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
2
3import java.io.IOException;
4import java.util.HashMap;
5import java.util.Map;
6import org.apache.commons.logging.Log;
7import org.apache.commons.logging.LogFactory;
8import org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService;
9import org.shirdrn.platform.dubbo.service.rpc.utils.QueryPostClient;
10import org.springframework.context.support.ClassPathXmlApplicationContext;
11public class SolrSearchServer implements SolrSearchService {
12 private static final Log LOG = LogFactory.getLog(SolrSearchServer.class);
13 private String baseUrl;
14 private final QueryPostClient postClient;
15 private static final Map<ResponseType, FormatHandler> handlers = new HashMap<ResponseType, FormatHandler>(0);
16
17 static {
18 handlers.put(ResponseType.XML, new FormatHandler() {
19 public String format() {
20 return "&wt=xml";
21 }
22 });
23
24 handlers.put(ResponseType.JSON, new FormatHandler() {
25 public String format() {
26 return "&wt=json";
27 }
28 });
29 }
30
31
32
33 public SolrSearchServer() {
34 super();
35 postClient = QueryPostClient.newIndexingClient(null);
36 }
37
38 public void setBaseUrl(String baseUrl) {
39 this.baseUrl = baseUrl;
40 }
41
42 public String search(String collection, String q, ResponseType type,
43 int start, int rows) {
44 StringBuffer url = new StringBuffer();
45 url.append(baseUrl).append(collection).append("/select?").append(q);
46 url.append("&start=").append(start).append("&rows=").append(rows);
47 url.append(handlers.get(type).format());
48 LOG.info("[REQ] " + url.toString());
49 return postClient.request(url.toString());
50 }
51
52
53
54 interface FormatHandler {
55 String format();
56 }
57
58
59 public static void main(String[] args) throws IOException {
60 String config = SolrSearchServer.class.getPackage().getName().replace('.', '/') + "/search-provider.xml";
61 ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext(config);
62 context.start();
63 System.in.read();
64
65 }
66
67}
68
对应的Dubbo配置文件为search-provider.xml,内容如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2<beans xmlns="http://www.springframework.org/schema/beans"
3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
4
5 xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
6
7 http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd">
8
9 <dubbo:application name="search-provider" />
10 <dubbo:registry address="zookeeper://slave1:2188?backup=slave3:2188,slave4:2188" />
11 <dubbo:protocol name="dubbo" port="20880" />
12 <bean id="searchService" class="org.shirdrn.platform.dubbo.service.rpc.server.SolrSearchServer">
13 <property name="baseUrl" value="http://nginx-lbserver/solr-cloud/" />
14 </bean>
15 <dubbo:service interface="org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService" ref="searchService" />
16
17</beans>
18
上面,Dubbo服务注册中心指定ZooKeeper的地址:zookeeper://slave1:2188?backup=slave3:2188,slave4:2188,使用Dubbo协议。配置服务接口的时候,可以按照Spring的Bean的配置方式来配置,注入需要的内容,我们这里指定了搜索集群的Nginx反向代理地址http://nginx-lbserver/solr-cloud/。
- Consumer调用服务设计
这个就比较简单了,拷贝服务接口,同时要配置一下Dubbo的配置文件,写个简单的客户端调用就可以实现。客户端实现的Java代码如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
2
3import java.util.concurrent.Callable;
4import java.util.concurrent.Future;
5import org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService;
6import org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService.ResponseType;
7import org.springframework.beans.BeansException;
8import org.springframework.context.support.AbstractXmlApplicationContext;
9import org.springframework.context.support.ClassPathXmlApplicationContext;
10import com.alibaba.dubbo.rpc.RpcContext;
11
12public class SearchConsumer {
13
14
15
16 private final String collection;
17
18 private AbstractXmlApplicationContext context;
19
20 private SolrSearchService searchService;
21
22 public SearchConsumer(String collection, Callable<AbstractXmlApplicationContext> call) {
23 super();
24 this.collection = collection;
25 try {
26 context = call.call();
27 context.start();
28 searchService = (SolrSearchService) context.getBean("searchService");
29 } catch (BeansException e) {
30 e.printStackTrace();
31 } catch (Exception e) {
32 e.printStackTrace();
33 }
34 }
35
36 public Future<String> asyncCall(final String q, final ResponseType type, final int start, final int rows) {
37 Future<String> future = RpcContext.getContext().asyncCall(new Callable<String>() {
38 public String call() throws Exception {
39 return search(q, type, start, rows);
40 }
41 });
42
43 return future;
44 }
45
46
47 public String syncCall(final String q, final ResponseType type, final int start, final int rows) {
48 return search(q, type, start, rows);
49 }
50
51 private String search(final String q, final ResponseType type, final int start, final int rows) {
52 return searchService.search(collection, q, type, start, rows);
53 }
54
55
56
57 public static void main(String[] args) throws Exception {
58 final String collection = "tinycollection";
59 final String beanXML = "search-consumer.xml";
60 final String config = SearchConsumer.class.getPackage().getName().replace('.', '/') + "/" + beanXML;
61 SearchConsumer consumer = new SearchConsumer(collection, new Callable<AbstractXmlApplicationContext>() {
62 public AbstractXmlApplicationContext call() throws Exception {
63 final AbstractXmlApplicationContext context = new ClassPathXmlApplicationContext(config);
64 return context;
65 }
66 });
67
68 String q = "q=上海&fl=*&fq=building_type:1";
69 int start = 0;
70 int rows = 10;
71 ResponseType type = ResponseType.XML;
72 for (int k = 0; k < 10; k++) {
73 for (int i = 0; i < 10; i++) {
74 start = 1 * 10 * i;
75 if(i % 2 == 0) {
76 type = ResponseType.XML;
77 } else {
78 type = ResponseType.JSON;
79 }
80 String result = consumer.syncCall(q, type, start, rows);
81 System.out.println(result);
82 Future<String> future = consumer.asyncCall(q, type, start, rows);
83 System.out.println(future.get());
84 }
85 }
86 }
87
88}
89
查询的时候,需要提供查询字符串,符合Solr语法,例如“q=上海&fl=*&fq=building_type:1”。配置文件,我们使用search-consumer.xml,内容如下所示:
2
3
4
5
6
7
8
9
10
11
2<beans xmlns="http://www.springframework.org/schema/beans"
3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
4 xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
5 http://code.alibabatech.com/schema/dubbo http://code.alibabatech.com/schema/dubbo/dubbo.xsd">
6
7 <dubbo:application name="search-consumer" />
8 <dubbo:registry address="zookeeper://slave1:2188?backup=slave3:2188,slave4:2188" />
9 <dubbo:reference id="searchService" interface="org.shirdrn.platform.dubbo.service.rpc.api.SolrSearchService" />
10</beans>
11
运行说明
首先保证服务注册中心的ZooKeeper集群正常运行,然后启动SolrSearchServer,启动的时候直接将服务注册到ZooKeeper集群存储中,可以通过ZooKeeper的客户端脚本来查看注册的服务数据。一切正常以后,可以启动运行客户端SearchConsumer,调用SolrSearchServer所实现的远程搜索服务。
http://shiyanjun.cn/archives/341.html
