索引分析
单表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2CREATE TABLE IF NOT EXISTS `article` (
3`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
4`author_id` INT(10) UNSIGNED NOT NULL,
5`category_id` INT(10) UNSIGNED NOT NULL,
6`views` INT(10) UNSIGNED NOT NULL,
7`comments` INT(10) UNSIGNED NOT NULL,
8`title` VARBINARY(255) NOT NULL,
9`content` TEXT NOT NULL
10);
11
12INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES
13(1, 1, 1, 1, '1', '1'),
14(2, 2, 2, 2, '2', '2'),
15(1, 1, 3, 3, '3', '3');
16
1、查询
2
3
4
2EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
3#结论:很显然,type 是 ALL,即最坏的情况。Extra 里还出现了 Using filesort,也是最坏的情况。优化是必须的。
4

2、优化
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3#第2次EXPLAIN
4EXPLAIN SELECT id,author_id FROM `article` WHERE category_id = 1 AND comments >1 ORDER BY views DESC LIMIT 1;
5
6
7#结论:
8#type 变成了 range,这是可以忍受的。但是 extra 里使用 Using filesort 仍是无法接受的。
9#但是我们已经建立了索引,为啥没用呢?
10#这是因为按照 BTree 索引的工作原理,
11# 先排序 category_id,
12# 如果遇到相同的 category_id 则再排序 comments,如果遇到相同的 comments 则再排序 views。
13#当 comments 字段在联合索引里处于中间位置时,
14#因comments > 1 条件是一个范围值(所谓 range (> , < , between and)),
15#MySQL 无法利用索引再对后面的 views 部分进行检索,即 range 类型查询字段后面的索引无效。
16
17#如果:EXPLAIN SELECT id,author_id FROM `article` WHERE category_id = 1 AND comments =3 ORDER BY views DESC LIMIT 1 就没有问题
18

3、再优化
2
3
4
5
6
7
8
9
2create index idx_article_cv on article(category_id,views);
3
4#第3次EXPLAIN
5EXPLAIN SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
6
7#结论:可以看到,type 变为了 ref,Extra 中的 Using filesort 也消失了,结果非常理想。
8
9

两表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
2CREATE TABLE IF NOT EXISTS `class` (
3`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
4`card` INT(10) UNSIGNED NOT NULL,
5PRIMARY KEY (`id`)
6);
7CREATE TABLE IF NOT EXISTS `book` (
8`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
9`card` INT(10) UNSIGNED NOT NULL,
10PRIMARY KEY (`bookid`)
11);
12
13INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
14INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
15INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
16INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
17INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
18INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
19INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
20INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
21INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
22INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
23INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
24INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
25INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
26INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
27INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
28INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
29INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
30INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
31INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
32INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
33
34INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
35INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
36INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
37INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
38INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
39INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
40INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
41INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
42INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
43INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
44INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
45INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
46INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
47INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
48INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
49INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
50INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
51INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
52INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
53INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
54
1、查询
2
3
4
2EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
3#结论:type 有All
4

2、优化
2
3
4
5
6
7
8
9
10
2ALTER TABLE `book` ADD INDEX Y ( `card`);
3
4# 第2次explain
5EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;
6
7#可以看到第二行的 type 变为了 ref,rows 也变成了优化比较明显。
8#这是由左连接特性决定的。LEFT JOIN 条件用于确定如何从右表搜索行,左边一定都有,
9#所以右边是我们的关键点,一定需要建立索引。
10

左连接,若索引加在左表的 card上 ,是错误的:如下

** 左连接索引应该加在右表上,因为左边全都有,右表是关键,右表是被驱动表**
三表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2CREATE TABLE IF NOT EXISTS `phone` (
3`phoneid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
4`card` INT(10) UNSIGNED NOT NULL,
5PRIMARY KEY (`phoneid`)
6) ENGINE = INNODB;
7
8INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
9INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
10INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
11INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
12INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
13INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
14INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
15INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
16INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
17INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
18INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
19INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
20INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
21INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
22INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
23INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
24INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
25INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
26INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
27INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
28
建立索引查询
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2ALTER TABLE `phone` ADD INDEX z ( `card`);
3ALTER TABLE `book` ADD INDEX Y ( `card`);#上一个case建过一个同样的
4EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card=book.card LEFT JOIN phone ON book.card = phone.card;
5
6# 后 2 行的 type 都是 ref 且总 rows 优化很好,效果不错。因此索引最好设置在需要经常查询的字段中。
7==================================================================================
8【结论】
9Join语句的优化
10
11尽可能减少Join语句中的嵌套循环的循环总次数;“永远用小结果集驱动大的结果集”。
12优先优化嵌套循环的内层循环;
13保证Join语句中被驱动表上Join条件字段已经被索引;
14当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝惜JoinBuffer的设置;
15

索引失效的问题
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2CREATE TABLE staffs (
3 id INT PRIMARY KEY AUTO_INCREMENT,
4 NAME VARCHAR (24) NOT NULL DEFAULT '' COMMENT '姓名',
5 age INT NOT NULL DEFAULT 0 COMMENT '年龄',
6 pos VARCHAR (20) NOT NULL DEFAULT '' COMMENT '职位',
7 add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间'
8) CHARSET utf8 COMMENT '员工记录表' ;
9
10
11INSERT INTO staffs(NAME,age,pos,add_time) VALUES('z3',22,'manager',NOW());
12INSERT INTO staffs(NAME,age,pos,add_time) VALUES('July',23,'dev',NOW());
13
14SELECT * FROM staffs;
15
16ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos(name, age, pos);
17
如何避免索引失效
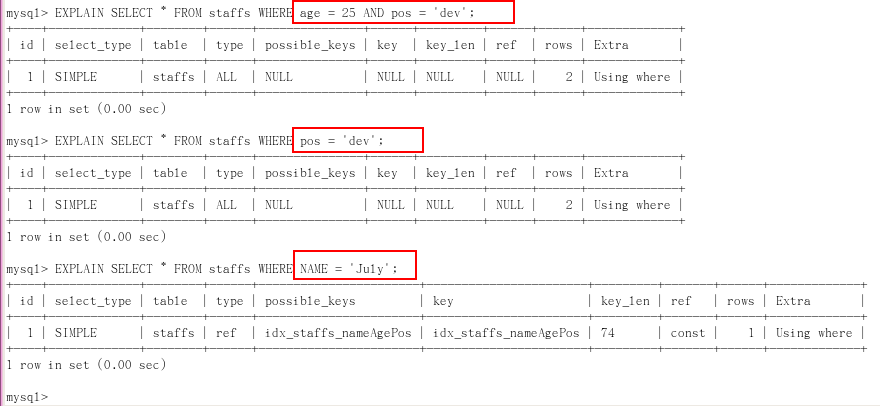
**1.全值匹配我最爱(where 后的条件要按顺序来) **
2
3
4
2 EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25;
3 EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25 AND pos = 'dev';
4

2.最佳左前缀法则(带头大哥不能死):如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始并且不跳过索引中的列。
2
3
2 EXPLAIN SELECT * FROM staffs WHERE pos = 'dev';
3
** 3.不在索引列上做任何操作(计算、函数、(自动或者手动)类型转换),会导致索引失效而转向全表扫描**
2
3
4
5
2
3 索引列上使用了表达式,如where substr(a, 1, 3) = 'hhh',where a = a + 1,表达式是一大忌讳,再简单mysql也不认。
4 有时数据量不是大到严重影响速度时,一般可以先查出来,比如先查所有有订单记录的数据,再在程序中去筛选
5

** 4.存储引擎不能使用索引中范围条件右边的列**
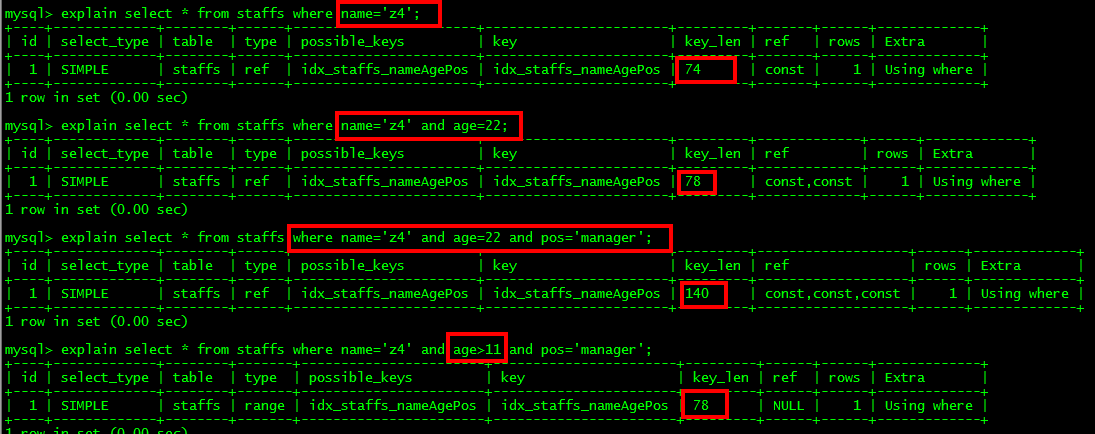
** 5.尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select ***
** ** 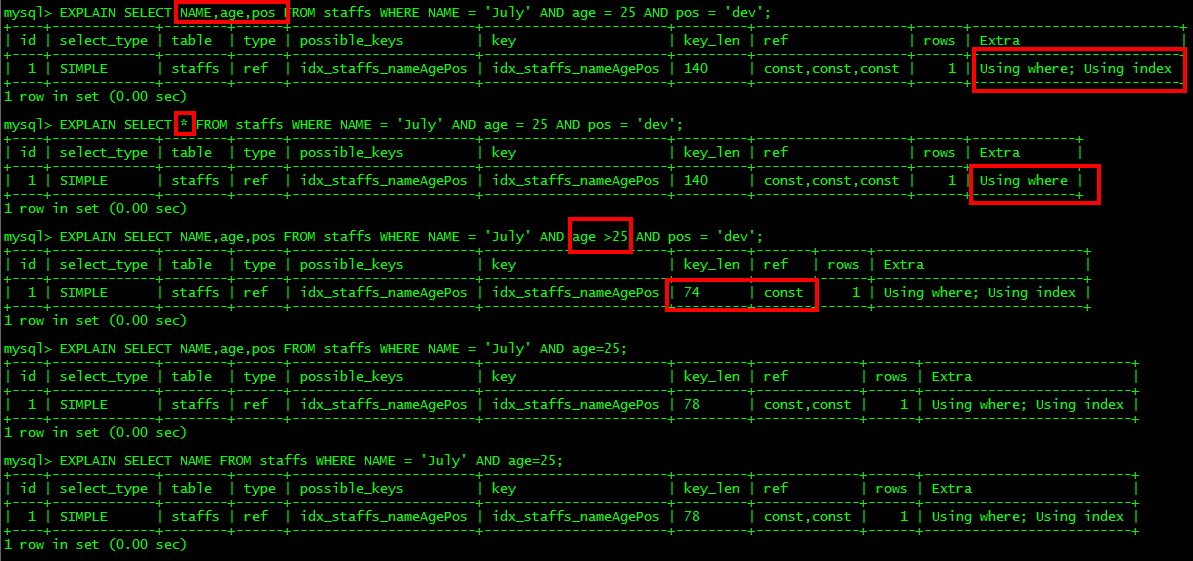
** **6.mysql 在使用不等于(!= 或者<>)的时候无法使用索引会导致全表扫描
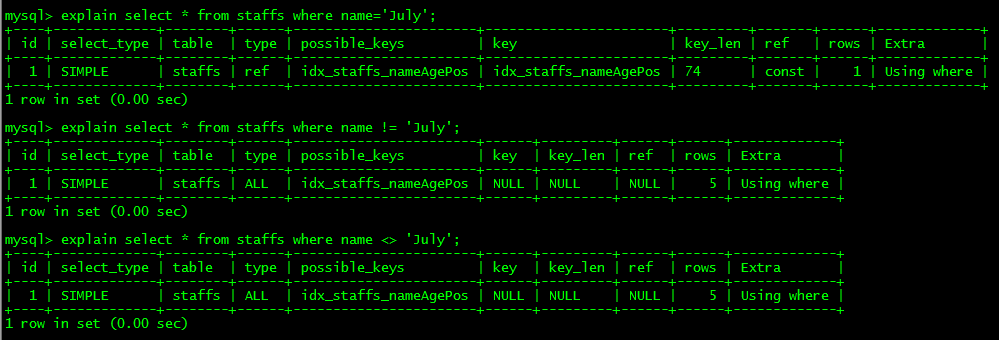
** 7.is null ,is not null 也无法使用索引**
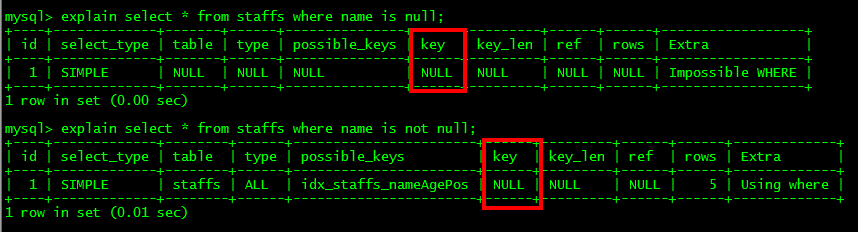
** 8.like以通配符
开头
('%abc…')mysql索引失效会变成全表扫描的操作**
** **如果必须用到%开头匹配的需求,用覆盖索引来解决
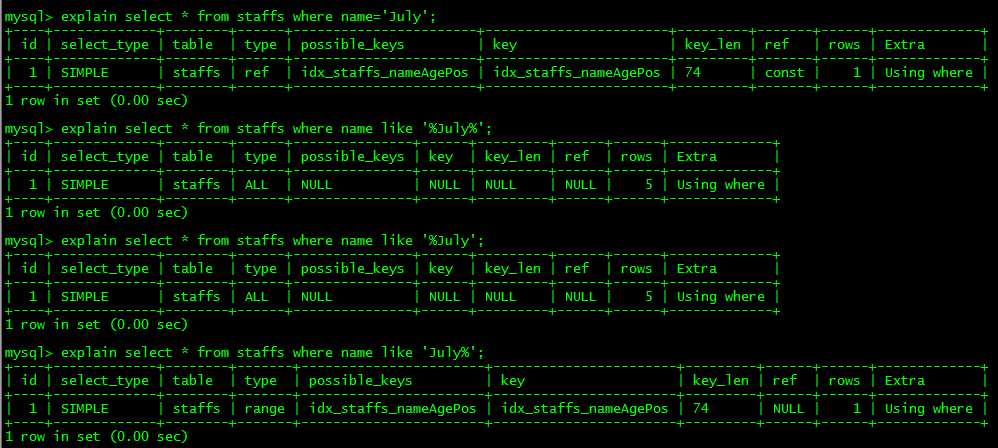
** 9.字符串不加单引号索引失效**

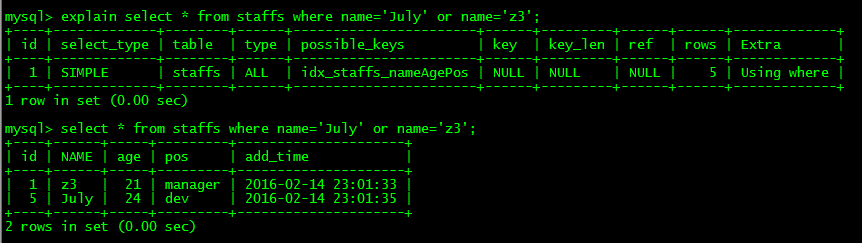
** 10.少用or,用它来连接时会索引失效**
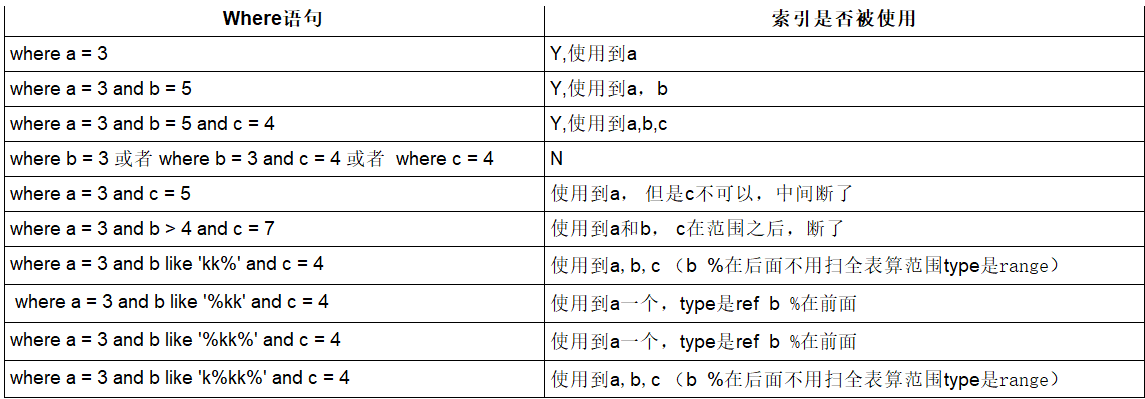
总结:
索引为复合索引:
index(a,b,c)
练习
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2 id int primary key not null auto_increment,
3 c1 char(10),
4 c2 char(10),
5 c3 char(10),
6 c4 char(10),
7 c5 char(10)
8);
9
10insert into test03(c1,c2,c3,c4,c5) values('a1','a2','a3','a4','a5');
11insert into test03(c1,c2,c3,c4,c5) values('b1','b2','b3','b4','b5');
12insert into test03(c1,c2,c3,c4,c5) values('c1','c2','c3','c4','c5');
13insert into test03(c1,c2,c3,c4,c5) values('d1','d2','d3','d4','d5');
14insert into test03(c1,c2,c3,c4,c5) values('e1','e2','e3','e4','e5');
15
16create index idx_test03_c1234 on test03(c1,c2,c3,c4);
17show index from test03;
18
1.正常语句

2.mysql的优化器会按照索引顺序优化

3.mysql的优化器会按照索引顺序优化

4.用到了 '>' 所以type是range,范围后的c4索引用不到

5.mysql优化器会按索引顺序优化成 where c1='a1' and c2='a2' and c3='a3' and c4>'a4';用到四个索引,有'>' 所以type是range

6. 用到了c1、c2索引c3作用在排序而不是查找,用不到c4索引

7.和6效果一样

8.跨过了c3 直接order by c4产生了内排序

9. 只用c1一个字段索引,但是c2、c3用于排序,是按照索引顺序的,所以无filesort

10. 用到了c1索引,order by c3 c2 颠倒了,它没有按照顺序来,出现了filesort

11.正常

12.正常

13.虽然order by c3,c2 没有按照索引顺序,但是前面where c2='a2' 已经确定c2是常量固定值,所以c2 order by没有任何影响

14.出现内排序: filesort

15.查找用到索引c1 group by c2,c3也是按照索引顺序来的 用来分组排序 正常

16.用到索引c1 但是group by c3,c2没有按照索引顺序,所以出现Using temporary用到了临时表,但是group by前必排序(order by)所以出现了Using filesort

17.用到了索引c1, c4中间段了没有用到c4 ,c2、c3用来分组排序

order by索引练习
2
3
4
5
6
7
8
9
10
11
12
2 #id int primary key not null auto_increment,
3 age INT,
4 birth TIMESTAMP NOT NULL
5);
6
7INSERT INTO tblA(age,birth) VALUES(22,NOW());
8INSERT INTO tblA(age,birth) VALUES(23,NOW());
9INSERT INTO tblA(age,birth) VALUES(24,NOW());
10
11CREATE INDEX idx_A_ageBirth ON tblA(age,birth);
12



** group by索引**
1.group by实质是先排序后进行分组,遵照索引建的最佳左前缀
2.当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置
3.where高于having,能写在where限定的条件就不要去having限定了。
小表驱动大表
类似嵌套循环Nested Loop(for循环 外层循环少,建立数据库连接少(外层循环),每次数据库连接查询的数据多(内层循环))
例子:表emp代表员工表,表dep代表部门表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2select * from emp e where e.depId in (select d.id from dep d);
3#等价于
4for select d.id from dep d; #外层循环(d为小表驱动表)
5for select * from emp e where e.depId = d.id; #内层循环(e为大表被驱动表)
6
7#当A表的数据集必须小于B表时,用exists优于in
8select * from emp e where exists (select 1 from dep d where d.id = e.depId);
9#等价于
10for select * from emp e; #外层循环(e为小表驱动表)
11for select */1 from dep d where d.id = e.depId #内层循环(d为大表被驱动表)
12
13
14#exists语句
15select ... from table where exists(subquery);
16#可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(true或false)来决定主查询的数据是否得以保留
17
18#提示
19#1.exists(subquery)只返回true或false,因此子查询中的select *也可以是select 1或其他,实际执行时会忽略select清单,因此没有区别
20#2.exists子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比,如果担忧效率问题,可以进行实际检验以确定是否有效率问题
21#3.exists子查询往往也可以用条件表达式、其他子查询或者join来替代,何种最优需要具体问题具体分析
22
