概况
CA(Lowest Common Ancestors),即最近公共祖先,是指在有根树中,找出某两个结点u和v最近的公共祖先。
基本介绍
LCA(Least Common Ancestors),即最近公共祖先,是指在有根树中,找出某两个结点u和v最近的公共祖先。
对于有根树T的两个结点u、v,最近公共祖先LCA(T,u,v)表示一个结点x,满足x是u、v的祖先且x的深度尽可能大。
另一种理解方式是把T理解为一个无向无环图,而LCA(T,u,v)即u到v的最短路上深度最小的点。
这里给出一个LCA的例子:
对于T=<V,E>
V={1,2,3,4,5}
E={(1,2),(1,3),(3,4),(3,5)}
则有:
LCA(T,5,2)=1
LCA(T,3,4)=3
LCA(T,4,5)=3
实现
暴力/Tarjan/DFS+ST/倍增
暴力枚举(朴素算法)
对于有根树T的两个结点u、v,首先将u,v中深度较深的那一个点向上蹦到和深度较浅的点,然后两个点一起向上蹦,直到蹦到同一个点,这个点就是u,v的最近公共祖先,记作LCA(u,v)。
但是这种方法的时间复杂度在极端情况下会达到O(n)。特别是有多组数据求解时,时间复杂度将会达到O(n*m)。
例:
[1]
在当这棵树是二叉查找树的情况下,如下图:
那么从树根开始:
- 如果当前结点t 大于结点u、v,说明u、v都在t 的左侧,所以它们的共同祖先必定在t 的左子树中,故从t 的左子树中继续查找;
- 如果当前结点t 小于结点u、v,说明u、v都在t 的右侧,所以它们的共同祖先必定在t 的右子树中,故从t 的右子树中继续查找;
- 如果当前结点t 满足 u <t < v,说明u和v分居在t 的两侧,故当前结点t 即为最近公共祖先;
- 而如果u是v的祖先,那么返回u的父结点,同理,如果v是u的祖先,那么返回v的父结点。
[2]
C++代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3 int left = u.value;
4 int right = v.value;
5 //二叉查找树内,如果左结点大于右结点,不对,交换
6 if (left > right) {
7 int temp = left;
8 left = right;
9 right = temp;
10 }
11
12 while (true) {
13 //如果t小于u、v,往t的右子树中查找
14 if (t.value < left)
15 t = t.right; //如果t大于u、v,往t的左子树中查找
16 else if (t.value > right)
17 t = t.left;
18 else
19 return t.value;
20 }
21}
22
运用DFS序
DFS序就是用DFS方法遍历整棵树得到的序列。
两个点的LCA一定是两个点在DFS序中出现的位置之间深度最小的那个点,
寻找最小值可以使用RMQ。
复杂度参考值:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
2
3// dfs过程,预处理深度dep、dfs序数组seq
4
5void dfs(int now, int fa, int d) {
6 pos[now] = ++tot, seq[tot] = now, dep[tot] = d;
7 for (int i = head[now]; i; i = e[i].next) {
8 int v = e[i].to;
9 if (v == fa) continue;
10 dfs(v, now, d + 1);
11 seq[++tot] = now, dep[tot] = d;
12 }
13}
14
15int anc[N << 1][20]; // anc[i][j]表示i节点向上跳2^j层对应的节点
16void init(int len) {
17 for (int i = 1; i <= len; i++)
18 anc[i][0] = i;
19 for (int k = 1; (1 << k) <= len; k++)
20 for (int i = 1; i + (1 << k) - 1 <= len; i++)
21 if (dep[anc[i][k - 1]] < dep[anc[i + (1 << (k - 1))][k - 1]])
22 anc[i][k] = anc[i][k - 1];
23 else
24 anc[i][k] = anc[i + (1 << (k - 1))][k - 1];
25}
26
27int rmq(int l, int r) {
28
29 int k = log(r - l + 1) / log(2);
30 return dep[anc[l][k]] < dep[anc[r + 1 - (1 << k)][k]] ? anc[l][k] : anc[r + 1 - (1 << k)][k];
31}
32
33
34
35int calc(int x, int y) {
36
37 x = pos[x], y = pos[y];
38 if (x > y) swap(x, y);
39 return seq[rmq(x, y)];
40}
41
42
43
44int lca(int a, int b) {
45 dfs(root, 0, 1); // root为树根节点的编号
46 init(0);
47 return calc(a, b);
48}
49
倍增寻找(ST算法)
此算法基于动态规划。
用f[i][j]表示区间起点为j长度为2^i的区间内的最小值所在下标,通俗的说,就是区间[j, j + 2^i)的区间内的最小值的下标。
从定义可知,这种表示法的区间长度一定是2的幂,所以除了单位区间(长度为1的区间)以外,任意一个区间都能够分成两份,并且同样可以用这种表示法进行表示,
[j, j + 2^i)的区间可以分成
[j, j+2^(i-1))和[j+2^(i-1),j + 2^i),于是
可以列出状态转移方程为: f[i][j]=RMQ( f[i-1][j], f[i-1][j+2^(i-1)] )。
f[m][n]的状态数目为n*m = nlogn,每次状态转移耗时O(1),所以预处理总时间为O(nlogn)。
原数组长度为n,当[j, j + 2^i)区间右端点j + 2^i – 1 >n时如何处理?在状态转移方程中只有一个地方会下标越界,所以当越界的时候状态转移只有一个方向,即当j + 2^(i-1) > n 时,f[i][j] =f[i-1][j]。
求解f[i][j]的代码就不给出了,只需要两层循环的状态转移就搞定了。
f[i][j]的计算只是做了一步预处理,但是我们在询问的时候,不能保证每个询问区间长度都是2的幂,如何利用预处理出来的值计算任何长度区间的值就是我们接下来要解决的问题。
首先只考虑区间长度大于1的情况(区间长度为1的情况最小值就等于它本身),给定任意区间[a, b] (1 <= a < b <= n),必定可以找到两个区间X和Y,它们的并是[a, b],并且区间X的左端点是a,区间Y的右端点是b,而且两个区间长度相当,且都是2的幂,如图所示:
设区间长度为2^k,则X表示的区间为[a, a + 2^k),Y表示的区间为(b – 2^k, b],则需要满足一个条件就是X的右端点必须大于等于Y的左端点减一,即 a+2^k-1 >= b-2^k,则2^(k+1) >= (b-a+1), 两边取对数(以2为底),得 k+1 >= lg(b-a+1),则k >= lg(b-a+1) – 1,k只要需要取最小的满足条件的整数即可( lg(x)代表以2为底x的对数 )。
仔细观察发现b-a+1正好为区间[a, b]的长度len,所以只要区间长度一定,k就能在常数时间内求出来。而区间长度只有n种情况,所以k可以通过预处理进行预存。
当lg(len)为整数时,k 取lg(len)-1,否则k为lg(len)-1 的上整(并且只有当len为2的幂时,lg(len)才为整数)。
我们注意到,在整个倍增查找LCA的过程中,从u到v的整条路径都被扫描了一遍。如果我们在倍增数组F[i][j]中再记录一些别的信息,就可以实现树路径信息的维护和查询
实现过程:
预处理:通过dfs遍历,记录每个节点到根节点的距离dist[u],深度d[u]
init()求出树上每个节点u的2^i祖先p[u][i]
求最近公共祖先,根据两个节点的的深度,如不同,向上调整深度大的节点,使得两个节点在同一层上,如果正好是祖先结束,否则,将两个节点同时上移,查询最近公共祖先。
核心代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
2 for(int i=head[u]; i!=-1; i=edge[i].next) {
3 int to=edge[i].to;
4 if(to==p[u][0])continue;
5 d[to]=d[u]+1;
6 dist[to]=dist[u]+edge[i].w;
7
8 p[to][0]=u; //p[i][0]存i的父节点
9 dfs(to);
10 }
11}
12
13
14
15void init()//i的2^j祖先就是i的(2^(j-1))祖先的2^(j-1)祖先
16{
17 for(int j=1; (1<<j)<=n; j++)
18 for(int i=1; i<=n; i++)
19 p[i][j]=p[p[i][j-1]][j-1];
20}
21
22
23
24int lca(int a,int b) {
25 if(d[a]>d[b])swap(a,b); //b在下面
26 int f=d[b]-d[a]; //f是高度差
27 for(int i=0; (1<<i)<=f; i++)
28 //(1<<i)&f找到f化为2进制后1的位置,移动到相应的位置
29 if((1<<i)&f)b=p[b][i]; //比如f=5,二进制就是101,所以首先移动2^0祖先,然后再移动2^2祖先
30 if(a!=b) {
31 for(int i=(int)log2(N); i>=0; i--)
32 if(p[a][i]!=p[b][i]) //从最大祖先开始,判断a,b祖先,是否相同
33 a=p[a][i], b=p[b][i]; //如不相同,a b同时向上移动2^j
34 a=p[a][0]; //这时a的father就是LCA
35
36 }
37 return a;
38}
39
ST算法可以扩展到二维,用四维的数组来保存状态,每个状态表示的是一个矩形区域中的最值,可以用来求解矩形区域内的最值问题。
Tarjan算法(离线算法)
离线算法,是指首先读入所有的询问(求一次LCA叫做一次询问),然后重新组织查询处理顺序以便得到更高效的处理方法。Tarjan算法是一个常见的用于解决LCA问题的离线算法,它结合了深度优先遍历和并查集,整个算法为线性处理时间。
Tarjan算法是基于并查集的,利用并查集优越的时空复杂度,可以实现LCA问题的O(n+Q)算法,这里Q表示询问 的次数。
同上一个算法一样,Tarjan算法也要用到深度优先搜索,算法大体流程如下:对于新搜索到的一个结点,首先创建由这个结点构成的集合,再对当前结点的每一个子树进行搜索,每搜索完一棵子树,则可确定子树内的LCA询问都已解决。其他的LCA询问的结果必然在这个子树之外,这时把子树所形成的集合与当前结点的集合合并,并将当前结点设为这个集合的祖先。之后继续搜索下一棵子树,直到当前结点的所有子树搜索完。这时把当前结点也设为已被检查过的,同时可以处理有关当前结点的LCA询问,如果有一个从当前结点到结点v的询问,且v已被检查过,则由于进行的是深度优先搜索,当前结点与v的最近公共祖先一定还没有被检查,而这个最近公共祖先的包涵v的子树一定已经搜索过了,那么这个最近公共祖先一定是v所在集合的祖先。
如图:
根据实现算法可以看出,只有当某一棵子树全部遍历处理完成后,才将该子树的根节点标记为黑色(初始化是白色),假设程序按上面的树形结构进行遍历,首先从节点1开始,然后递归处理根为2的子树,当子树2处理完毕后,节点2, 5, 6均为黑色;接着要回溯处理3子树,首先被染黑的是节点7(因为节点7作为叶子不用深搜,直接处理),接着节点7就会查看所有询问(7, x)的节点对,假如存在(7, 5),因为节点5已经被染黑,所以就可以断定(7, 5)的最近公共祖先就是find(5).ancestor,即节点1(因为2子树处理完毕后,子树2和节点1进行了union,find(5)返回了合并后的树的根1,此时树根的ancestor的值就是1)。有人会问如果没有(7, 5),而是有(5, 7)询问对怎么处理呢? 我们可以在程序初始化的时候做个技巧,将询问对(a, b)和(b, a)全部存储,这样就能保证完整性。
参考代码如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
2int n, root; //实际顶点个数,树根节点
3int indeg[mx]; //顶点入度,用来判断树根
4vector<int> tree[mx]; //树的邻接表(不一定是二叉树)
5void inputTree() //输入树
6{
7 scanf("%d", &n); //树的顶点数
8 for (int i = 0; i < n; i++) //初始化树,顶点编号从0开始
9 tree[i].clear(), indeg[i] = 0;
10 for (int i = 1; i < n; i++) //输入n-1条树边
11 {
12 int x, y;
13 scanf("%d%d", &x, &y); //x->y有一条边
14 tree[x].push_back(y);
15 indeg[y]++;//加入邻接表,y入度加一
16 }
17
18 for (int i = 0; i < n; i++) //寻找树根,入度为0的顶点
19 if (indeg[i] == 0)
20 {
21 root = i;
22 break;
23 }
24}
25
26vector<int> query[mx]; //所有查询的内容
27
28void inputQuires() //输入查询
29{
30 for (int i = 0; i < n; i++) //清空上次查询
31 query[i].clear();
32 int m;
33 scanf("%d", &m); //查询个数
34 while (m--)
35 {
36 int u, v;
37 scanf("%d%d", &u, &v); //查询u和v的LCA
38 query[u].push_back(v);
39 query[v].push_back(u);
40 }
41}
42
43int father[mx], rnk[mx]; //节点的父亲、秩
44
45void makeSet() //初始化并查集
46{
47 for (int i = 0; i < n; i++) father[i] = i, rnk[i] = 0;
48}
49
50int findSet(int x) //查找
51{
52 if (x != father[x]) father[x] = findSet(father[x]);
53 return father[x];
54}
55
56
57void unionSet(int x, int y) //合并
58{
59 x = findSet(x), y = findSet(y);
60 if (x == y) return;
61 if (rnk[x] > rnk[y]) father[y] = x;
62 else father[x] = y, rnk[y] += rnk[x] == rnk[y];
63}
64
65int ancestor[mx]; //已访问节点集合的祖先
66bool vs[mx]; //访问标志
67void Tarjan(int x) //Tarjan算法求解LCA
68{
69 for (int i = 0; i < tree[x].size(); i++)
70 {
71 Tarjan(tree[x][i]); //访问子树
72 unionSet(x, tree[x][i]); //将子树节点与根节点x的集合合并
73 ancestor[findSet(x)] = x;//合并后的集合的祖先为x
74 }
75 vs[x] = 1; //标记为已访问
76
77 for (int i = 0; i < query[x].size(); i++) //与根节点x有关的查询
78 if (vs[query[x][i]]) //如果查询的另一个节点已访问,则输出结果
79 printf("%d和%d的最近公共祖先为:%d\n", x,
80 query[x][i], ancestor[findSet(query[x][i])]);
81}
82
83int main()
84{
85 inputTree(); //输入树
86 inputQuires();//输入查询
87 makeSet();
88 for (int i = 0; i < n; i++)
89 ancestor[i] = i;
90 memset(vs, 0, sizeof(vs));
91
92 //初始化为未访问
93 Tarjan(root);
94}
95
树链剖分
对于输入的这棵树,先对其进行树链剖分处理。显然,树中任意点对(u,v)只存在两种情况:
1. 两点在同一条重链上。
2. 两点不在同一条重链上。
对于1,LCA(u,v) 明显为u,v两点中深度较小的点,即min(deep[u],deep[v])。
对于2,我们只要想办法将u,v两点转移到同一条重链上即可。
所以,我们可以将u,v一直上调,每次将u,v调至重链顶端,直到u,v两点在同一条重链上即可。
核心代码如下
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
2
3int head[N*2],next[N*2],to[N*2];// 树的邻接表
4int deep[N],fa[N];// deep表示节点深度,fa表示节点的父亲
5int size[N],son[N],top[N];// size表示节点所在的子树的节点总数
6 // son表示节点的重孩子
7 // top表示节点所在的重链的顶部节点
8
9
10
11inline void add(int u,int v,int tnt)// 邻接表加边
12{
13 nt[tnt]=ft[u];
14 ft[u]=tnt;
15 ed[tnt]=v;
16}
17
18
19void DFS(int u,int Fa)// 第一遍dfs,处理出deep,size,fa,son
20{
21 size[u]=1;
22 for(int i=head[u];i;i=next[i])
23 {
24 if(to[i]==Fa)
25 continue;
26 deep[to[i]]=d[u]+1;
27 fa[to[i]]=u;
28 DFS(to[i],u);
29 size[u]+=size[to[i]];
30 if(size[to[i]]>size[son[u]])
31 son[u]=to[i];
32 }
33}
34
35
36void Dfs(int u)// 第二遍dfs,将所有相邻的重边连成重链
37{
38 if(u==son[fa[u]])
39 top[u]=top[fa[u]];
40 else
41 top[u]=u;
42
43 for(int i=head[u];i;i=next[i])
44 if(to[i]!=fa[u])
45 Dfs(to[i]);
46}
47
48
49int LCA(int u,int v)// 处理LCA
50{
51 while(top[u]!=top[v])// 如果u,v不在同一条重链上
52 {
53 if(deep[top[u]]>deep[top[v]])// 将深度大的节点上调
54 u=fa[top[u]];
55 else
56 v=fa[top[v]];
57 }
58
59 return deep[u]>deep[v]?v:u;// 返回深度小的节点(即为LCA(u,v))
60
61}
62
下面详细介绍一下Tarjan算法的基本思路:
1.任选一个点为根节点,从根节点开始。
2.遍历该点u所有子节点v,并标记这些子节点v已被访问过。
3.若是v还有子节点,返回2,否则下一步。
4.合并v到u上。
5.寻找与当前点u有询问关系的点v。
6.若是v已经被访问过了,则可以确认u和v的最近公共祖先为v被合并到的父亲节点a。
遍历的话需要用到dfs来遍历(我相信来看的人都懂吧…),至于合并,最优化的方式就是利用并查集来合并两个节点。
下面上伪代码:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2 2 {
3 3 for each(u,v) //访问所有u子节点v
4 4 {
5 5 Tarjan(v); //继续往下遍历
6 6 marge(u,v); //合并v到u上
7 7 标记v被访问过;
8 8 }
9 9 for each(u,e) //访问所有和u有询问关系的e
10 10 {
11 11 如果e被访问过;
12 12 u,e的最近公共祖先为find(e);
13 13 }
14 14 }
15
个人感觉这样还是有很多人不太理解,所以我打算模拟一遍给大家看。
建议拿着纸和笔跟着我的描述一起模拟!!
假设我们有一组数据 9个节点 8条边 联通情况如下:
1–2,1–3,2–4,2–5,3–6,5–7,5–8,7–9 即下图所示的树
设我们要查找最近公共祖先的点为9–8,4–6,7–5,5–3;
设f[]数组为并查集的父亲节点数组,初始化f[i]=i,vis[]数组为是否访问过的数组,初始为0; 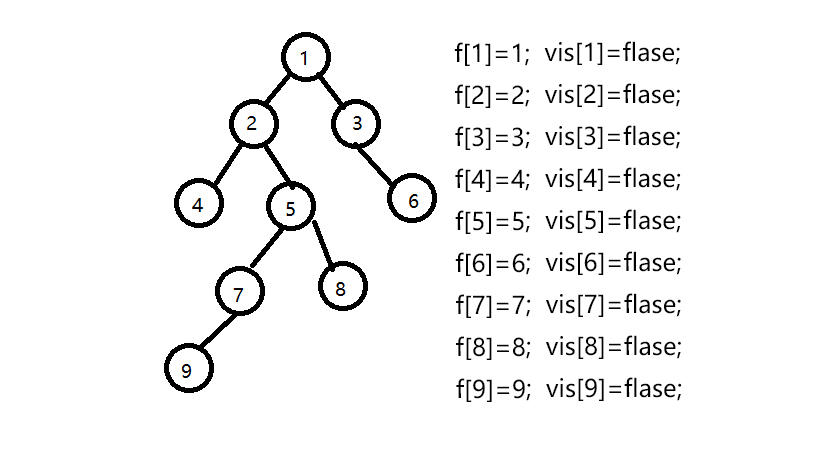
下面开始模拟过程:
取1为根节点,往下搜索发现有两个儿子2和3;
先搜2,发现2有两个儿子4和5,先搜索4,发现4没有子节点,则寻找与其有关系的点;
发现6与4有关系,但是vis[6]=0,即6还没被搜过,所以不操作;
发现没有和4有询问关系的点了,返回此前一次搜索,更新vis[4]=1;
表示4已经被搜完,更新f[4]=2,继续搜5,发现5有两个儿子7和8;
先搜7,发现7有一个子节点9,搜索9,发现没有子节点,寻找与其有关系的点;
发现8和9有关系,但是vis[8]=0,即8没被搜到过,所以不操作;
发现没有和9有询问关系的点了,返回此前一次搜索,更新vis[9]=1;
表示9已经被搜完,更新f[9]=7,发现7没有没被搜过的子节点了,寻找与其有关系的点;
发现5和7有关系,但是vis[5]=0,所以不操作;
发现没有和7有关系的点了,返回此前一次搜索,更新vis[7]=1;
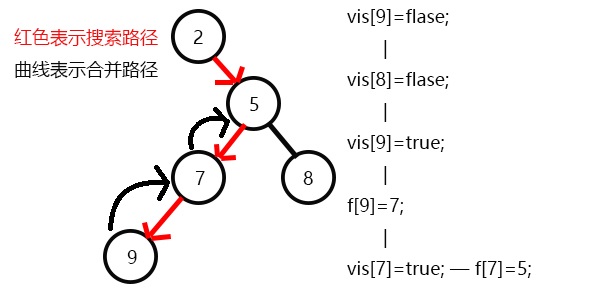
表示7已经被搜完,更新f[7]=5,继续搜8,发现8没有子节点,则寻找与其有关系的点;
发现9与8有关系,此时vis[9]=1,则他们的最近公共祖先为find(9)=5;
(find(9)的顺序为f[9]=7–>f[7]=5–>f[5]=5 return 5;)
发现没有与8有关系的点了,返回此前一次搜索,更新vis[8]=1;
表示8已经被搜完,更新f[8]=5,发现5没有没搜过的子节点了,寻找与其有关系的点;
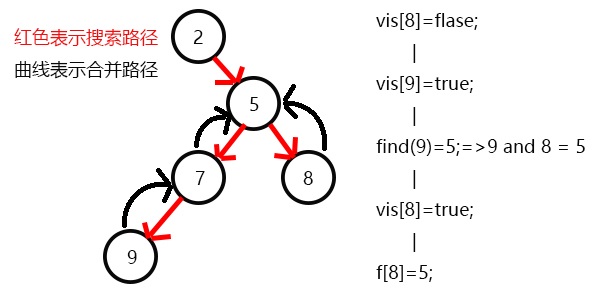
发现7和5有关系,此时vis[7]=1,所以他们的最近公共祖先为find(7)=5;
(find(7)的顺序为f[7]=5–>f[5]=5 return 5;)
又发现5和3有关系,但是vis[3]=0,所以不操作,此时5的子节点全部搜完了;
返回此前一次搜索,更新vis[5]=1,表示5已经被搜完,更新f[5]=2;
发现2没有未被搜完的子节点,寻找与其有关系的点;
又发现没有和2有关系的点,则此前一次搜索,更新vis[2]=1;
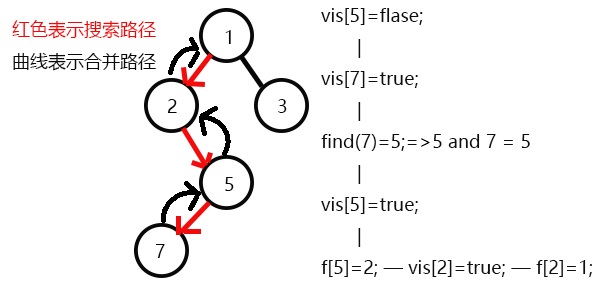
表示2已经被搜完,更新f[2]=1,继续搜3,发现3有一个子节点6;
搜索6,发现6没有子节点,则寻找与6有关系的点,发现4和6有关系;
此时vis[4]=1,所以它们的最近公共祖先为find(4)=1;
(find(4)的顺序为f[4]=2–>f[2]=2–>f[1]=1 return 1;)
发现没有与6有关系的点了,返回此前一次搜索,更新vis[6]=1,表示6已经被搜完了;
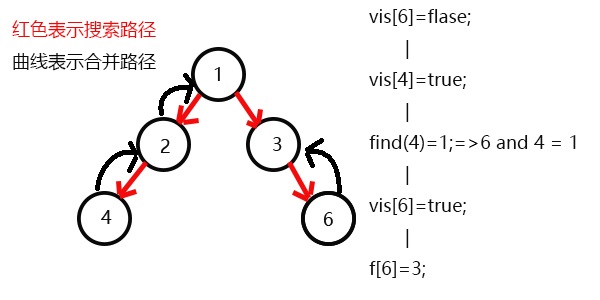
更新f[6]=3,发现3没有没被搜过的子节点了,则寻找与3有关系的点;
发现5和3有关系,此时vis[5]=1,则它们的最近公共祖先为find(5)=1;
(find(5)的顺序为f[5]=2–>f[2]=1–>f[1]=1 return 1;)
发现没有和3有关系的点了,返回此前一次搜索,更新vis[3]=1;
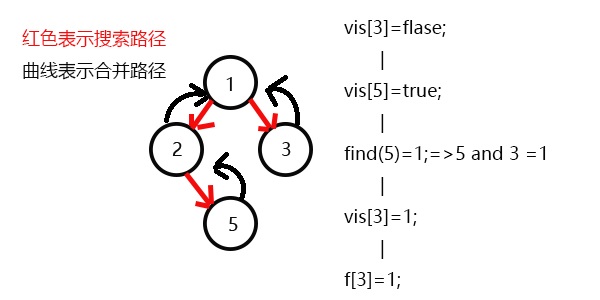
更新f[3]=1,发现1没有被搜过的子节点也没有有关系的点,此时可以退出整个dfs了。
