在本节内容之前,我们已经对如何引入Sleuth跟踪信息和搭建Zipkin服务端分析跟踪延迟的过程做了详细的介绍,相信大家对于Sleuth和Zipkin已经有了一定的感性认识。接下来,我们介绍一下关于Zipkin收集跟踪信息的过程细节,以帮助我们更好地理解Sleuth生产跟踪信息以及输出跟踪信息的整体过程和工作原理。
数据模型
我们先来看看Zipkin中关于跟踪信息的一些基础概念。由于Zipkin的实现借鉴了Google的Dapper,所以它们有着类似的核心术语,主要有下面几个内容:
-
Span:它代表了一个基础的工作单元。我们以HTTP请求为例,一次完整的请求过程在客户端和服务端都会产生多个不同的事件状态(比如下面所说的四个核心Annotation所标识的不同阶段),对于同一个请求来说,它们属于一个工作单元,所以同一HTTP请求过程中的四个Annotation同属于一个Span。每一个不同的工作单元都通过一个64位的ID来唯一标识,称为Span ID。(提示:一次完整的请求链里面可以包含多次请求,比如客户端发送了一个HTTP请求到trace-1,trace-1依赖于trace-2的服务,所以trace-1再发送一个HTTP请求到trace-2,待trace-2返回响应之后,trace-1再组织响应结果返回给客户端。)另外,在工作单元中还存储了一个用来串联其他工作单元的ID,它也通过一个64位的ID来唯一标识,称为Trace ID。在同一条请求链路中的不同工作单元都会有不同的Span ID,但是它们的Trace ID是相同的,所以通过Trace ID可以将一次请求中依赖的所有依赖请求串联起来形成请求链路。除了这两个核心的ID之外,Span中还存储了一些其他信息,比如:描述信息、事件时间戳、Annotation的键值对属性、上一级工作单元的Span ID等。
-
Trace:它是由一系列具有相同Trace ID的Span串联形成的一个树状结构。在复杂的分布式系统中,每一个外部请求通常都会产生一个复杂的树状结构的Trace。
-
Annotation:它用来及时地记录一个事件的存在。我们可以把Annotation理解为一个包含有时间戳的事件标签,对于一个HTTP请求来说,在Sleuth中定义了下面四个核心Annotation来标识一个请求的开始和结束:
-
cs(Client Send):该Annotation用来记录客户端发起了一个请求,同时它也标识了这个HTTP请求的开始。
- sr(Server Received):该Annotation用来记录服务端接收到了请求,并准备开始处理它。通过计算sr与cs两个Annotation的时间戳之差,我们可以得到当前HTTP请求的网络延迟。
- ss(Server Send):该Annotation用来记录服务端处理完请求后准备发送请求响应信息。通过计算ss与sr两个Annotation的时间戳之差,我们可以得到当前服务端处理请求的时间消耗。
- cr(Client Received):该Annotation用来记录客户端接收到服务端的回复,同时它也标识了这个HTTP请求的结束。通过计算cr与cs两个Annotation的时间戳之差,我们可以得到该HTTP请求从客户端发起开始到接收服务端响应的总时间消耗。
-
BinaryAnnotation:它用来对跟踪信息添加一些额外的补充说明,一般以键值对方式出现。比如:在记录HTTP请求接收后执行具体业务逻辑时,此时并没有默认的Annotation来标识该事件状态,但是有BinaryAnnotation信息对其进行补充。
收集机制
在理解了Zipkin的各个基本概念之后,下面我们结合前面章节中实现的例子来详细介绍和理解Spring Cloud Sleuth是如何对请求调用链路完成跟踪信息的生产、输出和后续处理的。
首先,我们来看看Sleuth在请求调用时是怎么样来记录和生成跟踪信息的。下图展示了我们在本章节中实现示例的运行全过程:客户端发送了一个HTTP请求到trace-1,trace-1依赖于trace-2的服务,所以trace-1再发送一个HTTP请求到trace-2,待trace-2返回响应之后,trace-1再组织响应结果返回给客户端。
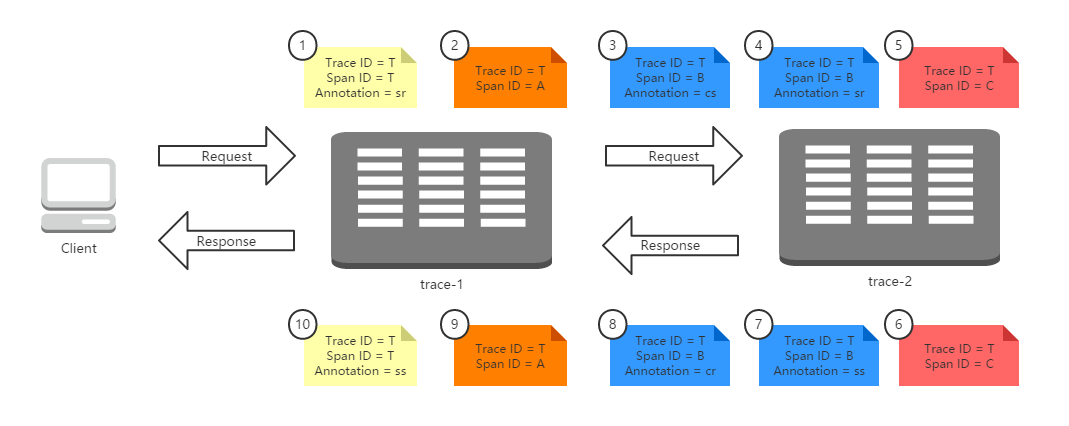
在上图的请求过程中,我们为整个调用过程标记了10个标签,它们分别代表了该请求链路运行过程中记录的几个重要事件状态,我们根据事件发生的时间顺序我们为这些标签做了从小到大的编号,1代表请求的开始、10代表请求的结束。每个标签中记录了一些我们上面提到过的核心元素:Trace ID、Span ID以及Annotation。由于这些标签都源自一个请求,所以他们的Trace ID相同,而标签1和标签10是起始和结束节点,它们的Trace ID与Span ID是相同的。
根据Span ID,我们可以发现在这些标签中一共产生了4个不同ID的Span,这4个Span分别代表了这样4个工作单元:
- Span T:记录了客户端请求到达trace-1和trace-1发送请求响应的两个事件,它可以计算出了客户端请求响应过程的总延迟时间。
- Span A:记录了trace-1应用在接收到客户端请求之后调用处理方法的开始和结束两个事件,它可以计算出trace-1应用用于处理客户端请求时,内部逻辑花费的时间延迟。
- Span B:记录了trace-1应用发送请求给trace-2应用、trace-2应用接收请求,trace-2应用发送响应、trace-1应用接收响应四个事件,它可以计算出trace-1调用trace-2的总体依赖时间(cr – cs),也可以计算出trace-1到trace-2的网络延迟(sr – cs),也可以计算出trace-2应用用于处理客户端请求的内部逻辑花费的时间延迟(ss – sr)。
- Span C:记录了trace-2应用在接收到trace-1的请求之后调用处理方法的开始和结束两个事件,它可以计算出trace-2应用用于处理来自trace-1的请求时,内部逻辑花费的时间延迟。
未完。。。
原文地址:http://blog.didispace.com/spring-cloud-starter-dalston-8-5/
本文代码(springcloud+zikpin+rabbitmq整合)地址:https://github.com/JavaAlliance/csdn-/tree/master/springcloud%2Bzipkin%2Brabbitmq整合
