1)信息熵:
假如一个随机变量的取值为,每一种取到的概率分别是,那么的熵定义为意思是一个变量的变化情况可能越多,那么它携带的信息量就越大,信息熵值越大,该系统越不稳定,存在的不定因素就越多。
对于分类系统来说,类别是变量,它的取值是,而每一个类别出现的概率分别是而这里的就是类别的总数,此时分类系统的熵就可以表示为
以上就是信息熵的定义,接下来介绍
信息增益。
信息熵的增益是指:所有属性值的信息熵和某一个属性值的信息熵的差值,增益值越大,说明其具有更高的决策性,可做为优先节点,如一些例子
例:通过当天的天气、温度、湿度和季节预测明天的天气
表1 原始数据
| 当天天气 | 温度 | 湿度 | 季节 | 明天天气 |
| 晴 | 25 | 50 | 春天 | 晴 |
| 阴 | 21 | 48 | 春天 | 阴 |
| 阴 | 18 | 70 | 春天 | 雨 |
| 晴 | 28 | 41 | 夏天 | 晴 |
| 雨 | 8 | 65 | 冬天 | 阴 |
| 晴 | 18 | 43 | 夏天 | 晴 |
| 阴 | 24 | 56 | 秋天 | 晴 |
| 雨 | 18 | 76 | 秋天 | 阴 |
| 雨 | 31 | 61 | 夏天 | 晴 |
| 阴 | 6 | 43 | 冬天 | 雨 |
| 晴 | 15 | 55 | 秋天 | 阴 |
| 雨 | 4 | 58 | 冬天 | 雨 |
1 | 1 |
** 1.数据分割**
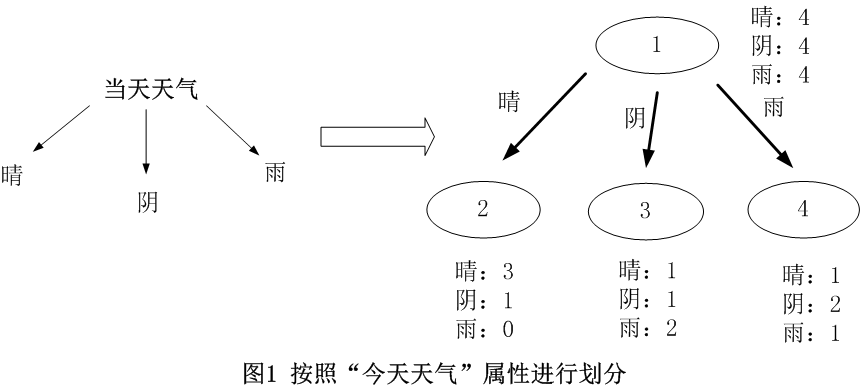
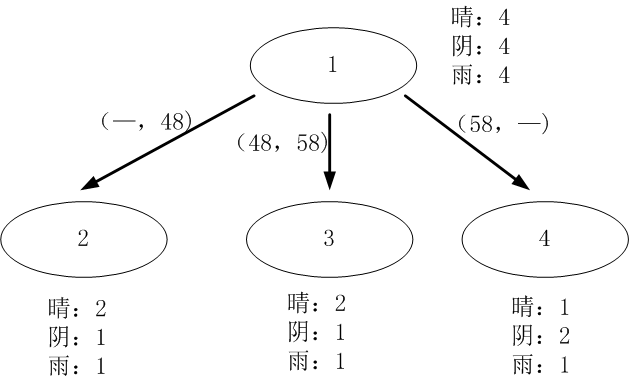
对于离散型数据,直接按照离散数据的取值进行分裂,每一个取值对应一个子节点,以“当前天气”为例对数据进行分割,如图1所示。
对于连续型数据,ID3原本是没有处理能力的,只有通过离散化将连续性数据转化成离散型数据再进行处理。
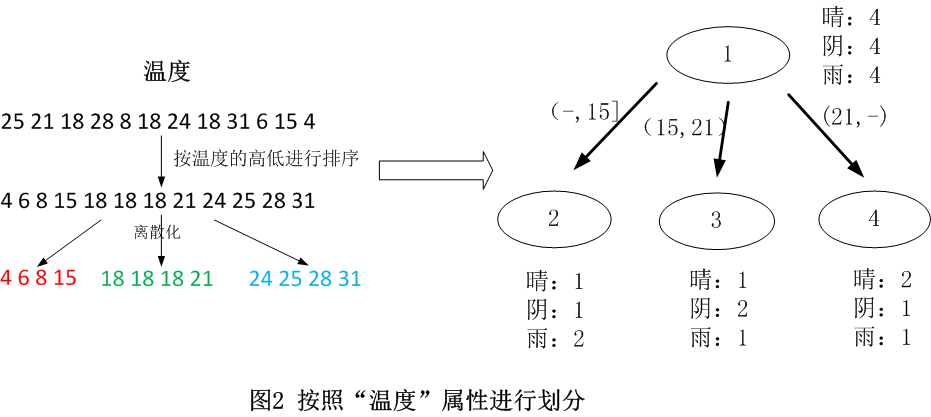
连续数据离散化是另外一个课题,本文不深入阐述,这里直接采用等距离数据划分的李算话方法。该方法先对数据进行排序,然后将连续型数据划分为多个区间,并使每一个区间的数据量基本相同,以温度为例对数据进行分割,如图2所示。
** 2. 选择最优分裂属性**
ID3采用信息增益作为选择最优的分裂属性的方法,选择熵作为衡量节点纯度的标准,信息增益的计算公式如下:
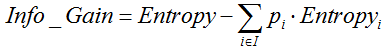
其中, 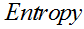 表示父节点的熵;
表示父节点的熵; 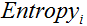 表示节点i的熵,熵越大,节点的信息量越多,越不纯;
表示节点i的熵,熵越大,节点的信息量越多,越不纯; 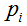 表示子节点i的数据量与父节点数据量之比。
表示子节点i的数据量与父节点数据量之比。 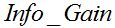 越大,表示分裂后的熵越小,子节点变得越纯,分类的效果越好,因此选择 最大的属性作为分裂属性。
越大,表示分裂后的熵越小,子节点变得越纯,分类的效果越好,因此选择 最大的属性作为分裂属性。
对上述的例子的跟节点进行分裂,分别计算每一个属性的信息增益,选择信息增益最大的属性进行分裂。
天气属性:(数据分割如上图1所示)
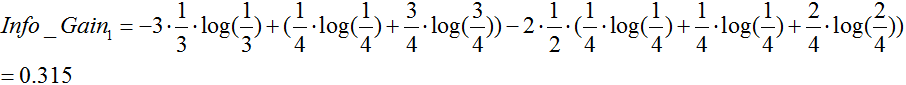
温度:(数据分割如上图2所示)
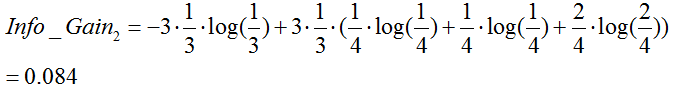
湿度:
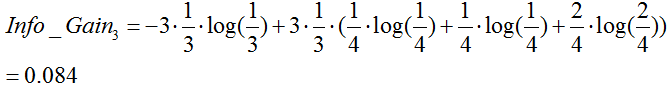
季节:
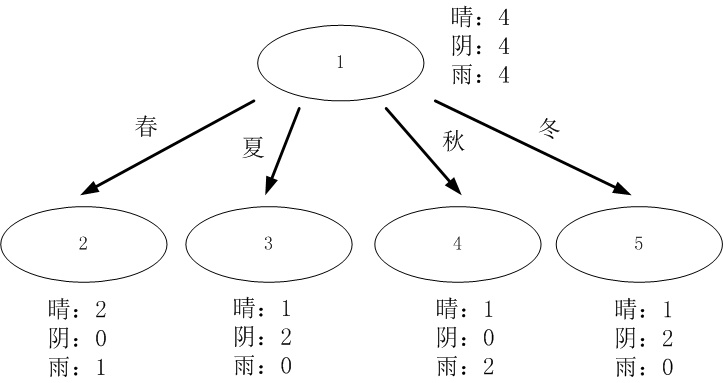
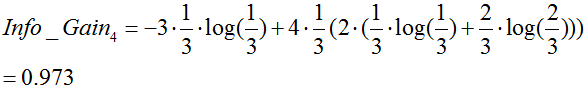
由于 最大,所以选择属性“季节”作为根节点的分裂属性。
最大,所以选择属性“季节”作为根节点的分裂属性。
3.停止分裂的条件
停止分裂的条件已经在决策树中阐述,这里不再进行阐述。
(1)最小节点数
当节点的数据量小于一个指定的数量时,不继续分裂。两个原因:一是数据量较少时,再做分裂容易强化噪声数据的作用;二是降低树生长的复杂性。提前结束分裂一定程度上有利于降低过拟合的影响。
(2)熵或者基尼值小于阀值。
由上述可知,熵和基尼值的大小表示数据的复杂程度,当熵或者基尼值过小时,表示数据的纯度比较大,如果熵或者基尼值小于一定程度时,节点停止分裂。
(3)决策树的深度达到指定的条件
节点的深度可以理解为节点与决策树跟节点的距离,如根节点的子节点的深度为1,因为这些节点与跟节点的距离为1,子节点的深度要比父节点的深度大1。决策树的深度是所有叶子节点的最大深度,当深度到达指定的上限大小时,停止分裂。
(4)所有特征已经使用完毕,不能继续进行分裂。
被动式停止分裂的条件,当已经没有可分的属性时,直接将当前节点设置为叶子节点。
