释放双眼,带上耳机,听听看~!
k-近邻算法:
对于给定样本,基于某种“距离”度量测试数据与样本数据的相似度,取相似度较大(距离较短)的前K的样本的标签,对于分类任务取K个样本出现最多的标签作为test数据的标签(投票法),对于回归任务取K个样本标签的平均值作为test数据的标签(平均法):
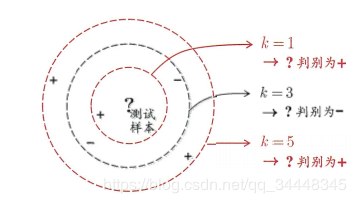
k作为一个重要的参数,以K=3为例测试样本取负例,K=5为例测试样本取正例。假设测试样本为x,最近邻样本为z,当分类器给x和z打上不同标签的概率时,给出最近邻分类器错误率:
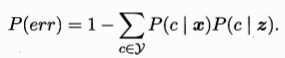
k-近邻算法泛化错误率不超过贝叶斯最优分类器错误率的两倍(假设样本独立同分布,且对任意x和任意小正数δ,在x附近δ距离范围内都能找到一个训练样本(采样密度足够大)):
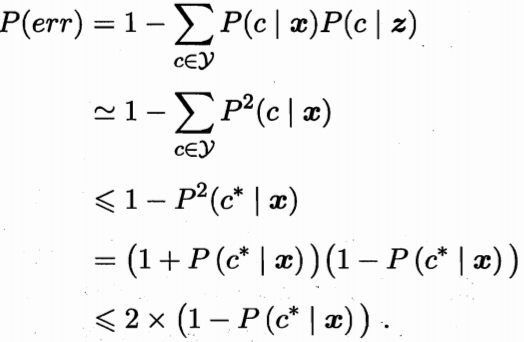
采样密度足够大:
如果取样本维度=1,距离δ=0.001,则需要1000个样本点平均分布在归一化后的样本取值范围内。
如果取样本维度=20,距离δ=0.001,则需要(10^3)^60个样本点平均分布在归一化后的样本取值范围内。
现实中的样本维度几乎成千上万,则满足采样密度的样本个数无法计算更不能计算距离,通常会使用“低维嵌入”,比如主成分分析或者核线性降为。
javacv实现特征脸算法:
将人脸图片降维,再用knn进行人脸分类。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
2 //图片转mat
3 public static Mat readImage(String filePath){
4 Mat image = imread(filePath, IMREAD_COLOR);
5 if (image==null||image.empty()) {
6 return null;
7 }
8 return image;
9 }
10 //mat数组转行向量
11 public static Mat GetAllsamples(MatVector images){
12 //存放所有mat
13 Mat allsamples = new Mat();
14 Mat mat;
15 //mat转行向量
16 Mat convertMat = new Mat();
17 for (int i = 0; i < images.size(); ++i) {
18 mat = images.get(i);
19 mat.reshape(1, 1).row(0).convertTo(convertMat, CV_32FC1);
20 allsamples.push_back(convertMat);
21 }
22 return allsamples;
23 }
24 //mat转xml
25 public static void SaveMat(Mat mat,String path){
26 FileStorage f = new FileStorage(path,WRITE);
27 f.write("tag",mat);
28 f.release();
29 }
30 //xml转mat
31 public static Mat LoadMat(String path){
32 FileStorage f = new FileStorage(path,READ);
33 Mat mat = f.get("tag").mat();
34 System.out.println("mat:"+mat.cols()+","+mat.rows());
35 return mat;
36 }
37 //名字数组转xml
38 public static void SaveName(String [] arr,String path){
39 FileStorage f = new FileStorage(path,WRITE);
40 for(int i= 0;i<arr.length;i++){
41 f.write("tag_"+i,arr[i]);
42 }
43 f.release();
44 }
45 //匹配名字
46 public static String GetName(int i,String path){
47 FileStorage f = new FileStorage(path,READ);
48 String name = f.get("tag_"+i).asBytePointer().getString();
49 return name;
50 }
51 //显示mat矩阵对应的图片
52 public static void showImage(Mat mat){
53 OpenCVFrameConverter.ToMat converter = new OpenCVFrameConverter.ToMat();
54 CanvasFrame canvas = new CanvasFrame("人脸", 1);
55 canvas.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
56 canvas.showImage(converter.convert(mat));
57 }
58 //训练
59 public static Mat Train(String trainData) {
60 //加载训练数据
61 Mat allsamples = LoadMat(trainData);
62 Mat placeholder = new Mat();
63 //pca
64 PCA pca = new PCA(allsamples, placeholder, CV_PCA_DATA_AS_ROW);
65 //特征脸向量矩阵
66 Mat result = pca.project(allsamples);
67 return result;
68 }
69 //计算欧氏距离
70 public static double EuclideanMetric(Mat mat1, Mat mat2) {
71 CvMat cv1 = new CvMat(mat1);
72 CvMat cv2 = new CvMat(mat2);
73 return cvNorm(cv1, cv2);
74 }
75 //测试
76 public static int Test(Mat testImage,String trainData,String resultData){
77 //加载训练集合数据
78 Mat allsamples = LoadMat(trainData);
79 Mat placeholder = new Mat();
80 //加载特征脸集合数据
81 Mat result = LoadMat(resultData);
82 //创建PCA
83 PCA pca = new PCA(allsamples, placeholder, CV_PCA_DATA_AS_ROW);
84 if(pca!=null){
85 //mat转向量
86 Mat convertMat = new Mat();
87 testImage.reshape(1, 1).row(0).convertTo(convertMat, CV_32FC1);
88 //记录所有欧氏距离
89 double[] d = new double[result.rows()];
90 Mat testResult = pca.project(convertMat);
91 System.out.println("test data:"+testResult.rows()+","+testResult.cols());
92 double min_distance = 0;
93 //最小的欧氏距离对应的训练数据id
94 int min_i = -1;
95 //对每个向量进行求欧式距离
96 for (int i = 0; i < result.rows(); i++){
97 d[i] = EuclideanMetric(testResult, result.row(i));
98 System.out.println("d:" + d[i]);
99 if (i == 0) {
100 min_distance = d[0];
101 min_i = i;
102 } else if (min_distance > d[i]){
103 min_distance = d[i];
104 min_i = i;
105 }
106 }
107 System.out.println("min_i:"+min_i);
108 return min_i;//返回欧式距离最小的那个特征脸的ID
109 }
110 return -1;
111 }
112
113 //人脸检测-将截取的人脸调用test
114 public static Mat DetectFace(Mat src,String trainData,String resultData,String nameData)
115 {
116 //面部识别级联分类器
117 opencv_objdetect.CascadeClassifier cascade = new opencv_objdetect.CascadeClassifier("E:\\work\\opencv\\opencv-master\\data\\lbpcascades\\lbpcascade_frontalface.xml");
118 //矢量图初始化
119 Mat grayscr=new Mat();
120 //彩图灰度化
121 cvtColor(src,grayscr,COLOR_BGRA2GRAY);
122 //均衡化直方图
123 equalizeHist(grayscr,grayscr);
124 opencv_core.RectVector faces=new opencv_core.RectVector();
125 cascade.detectMultiScale(grayscr, faces);
126 System.out.println("开始检测:");
127 //size就是检测到的人脸个数
128 for(int i=0;i<faces.size();i++)
129 {
130 opencv_core.Rect face_i=faces.get(i);
131 //人脸画框
132 rectangle(src, face_i, new opencv_core.Scalar(0, 0, 255, 1));
133 //人脸截图取mat
134 Mat face = new Mat(src,face_i);
135 Size size= new Size(55,55);
136 Mat _face = new Mat(size,CV_32S);
137 resize(face,_face,size);
138 //调用识别-找到最匹配的特征脸的ID
139 int ID = Test(_face,trainData,resultData);
140 //原图上标出 特征脸name
141 int x = face_i.x()-(face_i.width()/2);
142 int y = face_i.y();
143 String name = GetName(ID,nameData);
144 putText(src, name, new Point(x,y), CV_FONT_ITALIC, 1, new Scalar(0, 0, 255, 1), 2, 0, false);
145 System.out.println("识别到:id="+ID+",name="+name);
146 }
147 //显示释放否则内存溢出
148 return src;
149 }
150 //批量读取图片
151 public static HashMap<Mat,String> loadImages(String path){
152 HashMap <Mat,String> mats = new HashMap<>();
153 File file = new File(path);
154 if(file.isDirectory()){
155 File[] pics = file.listFiles();
156 for(int i=0;i<pics.length;i++){
157 File f = pics[i];
158 if(f.getName().contains(".jpg")||f.getName().contains(".jpeg")||f.getName().contains(".png")||f.getName().contains(".pgm")){
159 //图片
160 Mat mat = readImage(f.getPath());
161 //图片名称
162 String name = f.getName();
163 mats.put(mat,name);
164 }
165 }
166 }
167 return mats;
168 }
169
170 public static void main(String args[]){
171 //批量读取图片
172 HashMap<Mat,String> map = loadImages("E:\\work\\atest\\face2");
173 Mat[] matArr = new Mat[map.size()];
174 String[] namtes = new String[map.size()];//顺序保存每个特征脸矩阵的文件名
175 int i =0;
176 for(Mat m:map.keySet()){
177 matArr[i]=m;
178 namtes[i]=map.get(m).split("\\.")[0];
179 i++;
180 }
181 MatVector images = new MatVector();
182 images.put(matArr);
183 //mat数组转行向量
184 Mat mats = GetAllsamples(images);
185 //训练数据保存到xml
186 SaveMat(mats,"./target/Mats.xml");
187 SaveName(namtes,"./target/Names.xml");
188 //训练得到特征脸集合
189 Mat result = Train("./target/Mats.xml");
190 //特征脸集合保存到xml
191 SaveMat(result,"./target/Result.xml");
192 //Test
193 //人脸检测+识别
194 Mat mat = readImage("E:\\work\\atest\\face\\face.png");
195 Mat re = DetectFace(mat,"./target/Mats.xml","./target/Result.xml","./target/Names.xml");
196 showImage(re);
197 }
198}
199
python实现3分类:
样本已经包含3个特征,label包含3个类别。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
2#label:不喜欢、一般喜欢、特别喜欢
3
4#txt样本转特征矩阵、label向量
5def file_to_matrix(filename):
6 fr = open(filename)
7 array_lines = fr.readlines()
8 number_of_lines = len(array_lines) #一行一个样本一个n个
9 return_mat = np.zeros((number_of_lines, 3)) #每个样本是三维得到 (n,3)的样本矩阵
10 class_label_vector = [] #一维向量存储txt最后一列,即label
11 index = 0
12 for line in array_lines:
13 line = line.strip()
14 list_from_line = line.split('\t')
15 return_mat[index, :] = list_from_line[0:3]
16 class_label_vector.append(int(list_from_line[-1]))
17 index += 1
18 return return_mat, class_label_vector #返回特征矩阵、label向量
19
20#样本归一化
21#每个样本3个特征,分别减去全局最小值再除以取值范围(取值范围=全局最大值-全局最小值)
22def auto_norm(data_set):
23 min_vals = data_set.min(0)
24 max_vals = data_set.max(0)
25 ranges = max_vals - min_vals
26 norm_data_set = np.zeros(np.shape(data_set))
27 m = data_set.shape[0]
28 norm_data_set = data_set - np.tile(min_vals, (m, 1))
29 norm_data_set = norm_data_set / np.tile(ranges, (m, 1))
30 return norm_data_set, ranges, min_vals
31
32#分类函数
33#计算测试样本和所有训练样本的欧氏距离并排序然后投票选出最终分类结果
34def classify0(input_data, data_set, labels_set, k):
35 data_set_size = data_set.shape[0]
36 diff_mat = np.tile(input_data, (data_set_size, 1)) - data_set #计算欧氏距离
37 sq_diff_mat = diff_mat ** 2
38 sq_distances = sq_diff_mat.sum(axis=1)
39 distances = sq_distances ** 0.5
40 sorted_dist_indices = distances.argsort()
41 class_count = {}
42 for i in range(k):
43 vote_index_label = labels_set[sorted_dist_indices[i]]
44 class_count[vote_index_label] = class_count.get(vote_index_label, 0) + 1
45 sorted_class_count = sorted(class_count.items(), key=operator.itemgetter(1), reverse=True) #投票法
46 return sorted_class_count[0][0]
47
48#评分函数
49# 将数据集中90%用于训练,10%的数据留作测试用,挨个调用classify0统计错误率
50def dating_class_test():
51 ho_ratio = 0.10
52 dating_data_mat, dating_labels = file_to_matrix('datingTestSet2.txt')
53 norm_mat, ranges, min_vals = auto_norm(dating_data_mat)
54 m = norm_mat.shape[0]
55 num_test_vecs = int(m * ho_ratio)
56 error_count = 0.0
57 for i in range(num_test_vecs):
58 classifier_result = classify0(norm_mat[i, :], norm_mat[num_test_vecs:m, :], dating_labels[num_test_vecs:m], 3)
59 print("the classifier came back with: %d, the real answer is: %d" % (classifier_result, dating_labels[i]))
60 if (classifier_result != dating_labels[i]): error_count += 1.0
61 # 错误率
62 print("the total error rate is: %f" % (error_count / float(num_test_vecs)))
63
