1.腾讯网首页发表评论未做限制
使用burp的intruder模块生成payload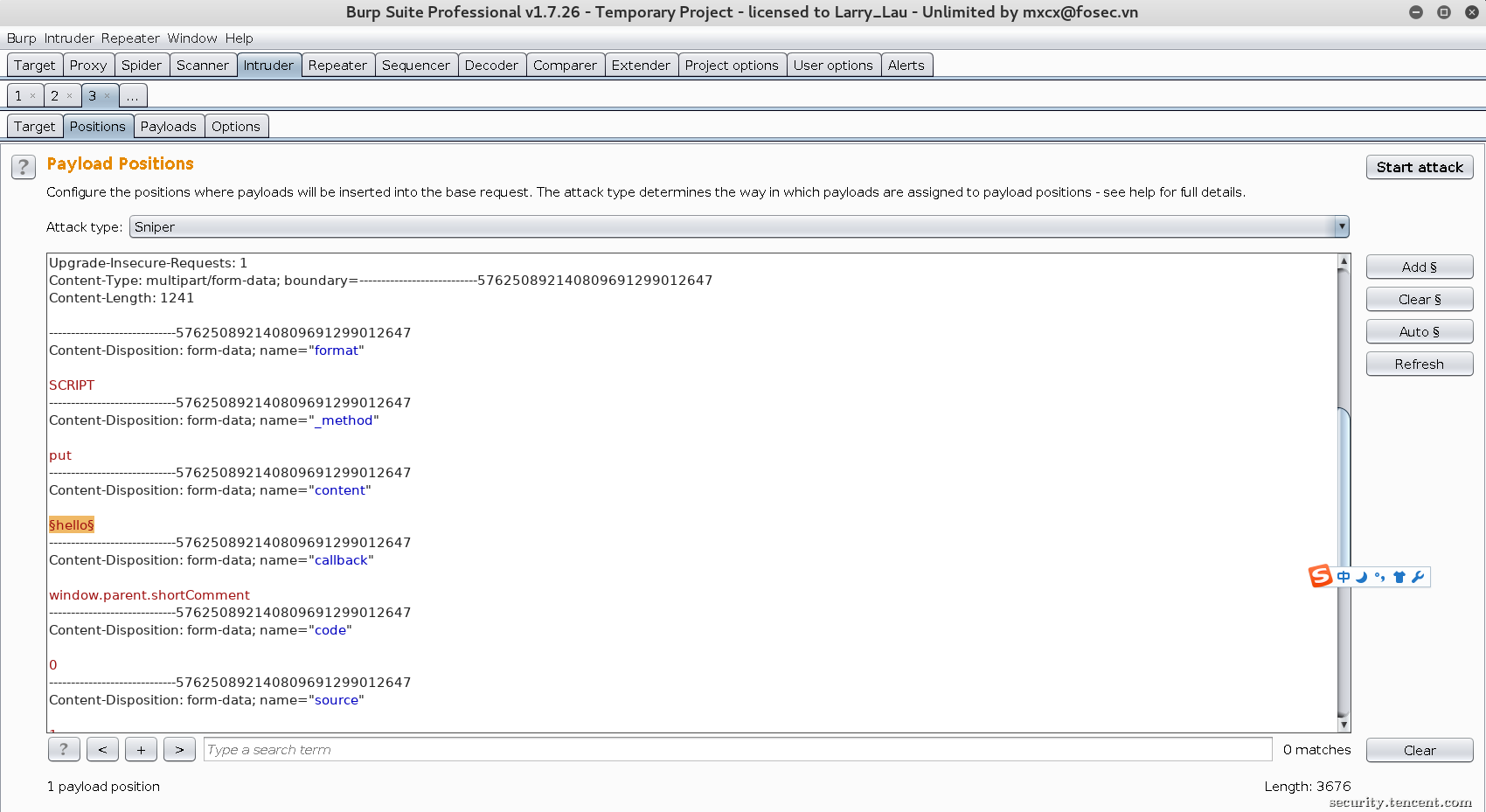
未做任何限制导致可批量提交大量的评论……
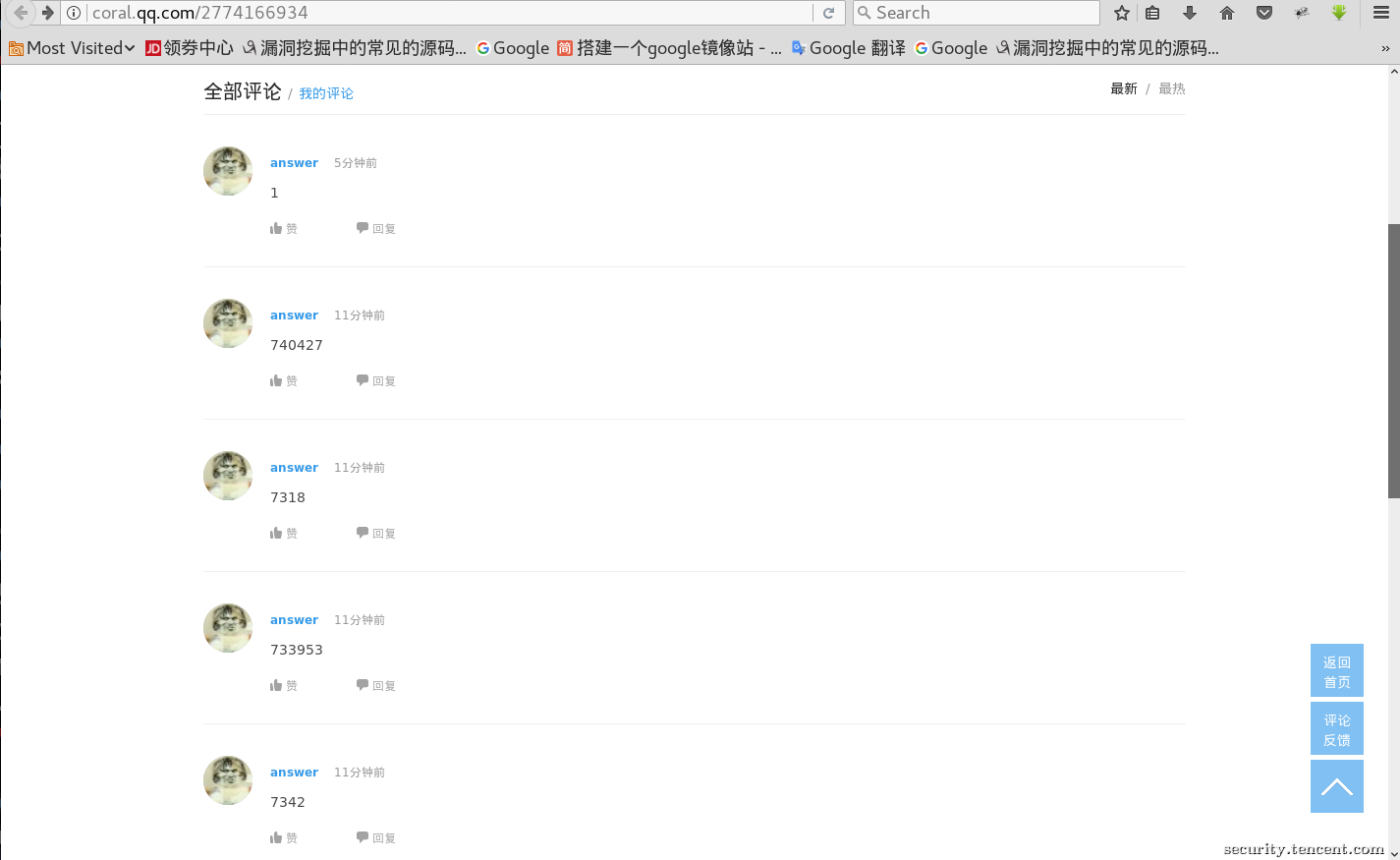
腾讯网是个专注最新资讯的网站,并且拥有非常高的日活跃用户,如果在发帖/发表评论处不做任何限制可导致攻击者通过大量注册小号,利用腾讯网来发表恶意言论,包括反政府言论,各种广告推广,诈骗信息等等。
其实当我提交src平台的时候感觉这里其实存在一些风险的……虽然说算不上什么高大上的漏洞……
但不知道为什么腾讯src方面选择忽略,非又让我想起来了某厂商因为忽略这种细节的威胁点让搞黑产的人利用了,发布大量的诈骗信息,色情小广告,等等最后被迫在这个功能点上加验证码……
一开始提交的时候都是忽略……
可能腾讯方面有自己的漏洞审核标准,既然忽略了,那就直接公开啦~
2.腾讯课堂某处业务安全风险可批量获取以公开用户手机号的手机号信息(未做反爬虫限制)
风险url:https://ke.qq.com/course/220822
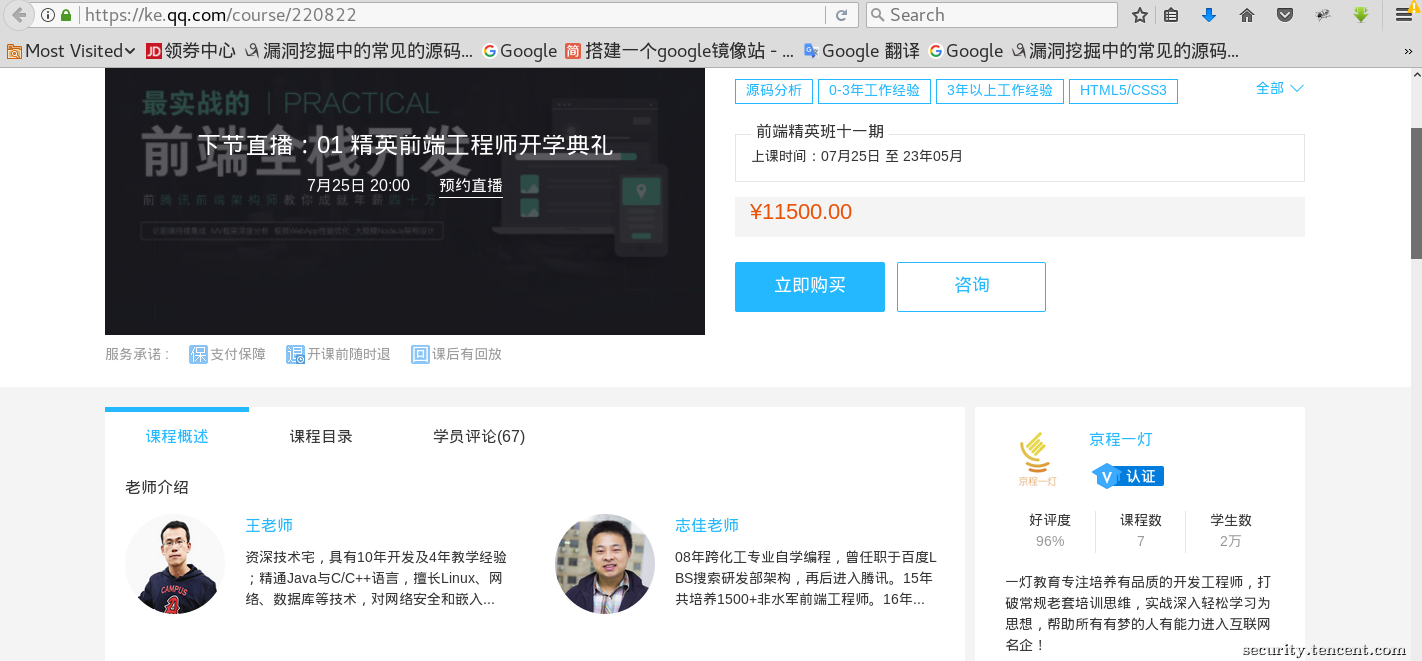
点击咨询的时候选择电话:
通过分析网页代码得知我们只需要抓取span标签和class为js-btn-advice-tel btn-advice-tel btn-outline btn-advice hide参数的标签获取用户手机号字段
我们发送大量的请求通过遍历https://ke.qq.com/course/220822url参数后面数字然后提取出来用户的手机号信息,这里的手机号的确是用户公开的信息,但是没有做反爬虫或限制同一时间请求页面的次数导致攻击者可以批量获取到全站公开信息的手机号。
脚本如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2from bs4 import BeautifulSoup
3
4def run():
5 for i in range(111111,222222):
6 url = 'https://ke.qq.com/course/%s' % i
7 headers = {
8 'Host':'ke.qq.com',
9 'User-Agent':'Mozilla/5.0 (X11; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0',
10 'Cookie':'填写自己的cookie信息',
11 'Upgrade-Insecure-Requests':'1',
12 }
13 response = requests.get(url=url,headers=headers)
14 soup = BeautifulSoup(response.text,"lxml")
15 try:
16 a = soup.find_all('span','js-btn-advice-tel btn-advice-tel btn-outline btn-advice hide')
17 phone_number = a[0]['data-tel']
18 if len(phone_number) == 11:
19 print '[*] ' + phone_number
20 else:
21 print '[!] ' + phone_number
22 except:
23 pass
24
25if __name__ == '__main__':
26 run()
27
脚本运行的结果:
python get_phone_number.py
的确像src审核所说的一样,这些只是公开电话,非安全漏洞。
= =不过总觉得这里还是有点小风险……
如果竞争对手通过爬虫采集到了对方大量的客源信息,撬走客户怎么办……
所以说在设计这些功能点就应该要做一些反爬虫的策略……
既然审核大大都说了上面两个问题非安全问题,我们就把这些问题当做我们以后在企业里做安全的时候,要注意的一些风险……
企业安全不仅仅只是防御安全漏洞。

](http://coral.qq.com/2774166934!%5B%5D(http://img.5iqiqu.com/images3/3f/3f02f1779b281f471fab3422d8eeabeb.png)){kind=link}