对于继承,我们先不说概念。下面我还是先用C模拟并借助汇编的方式来理解它,侧重于学习继承的内存模型。
我们先来看代码,设计三个类,People类,Teacher类,Student类
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2{
3 int age; //年龄
4 int sex; //性别
5};
6struct Teacher
7{
8 int age; //年龄
9 int sex; //性别
10 int level;//教师等级
11};
12struct Student
13{
14 int age; //年龄
15 int sex; //性别
16 int score;//分数
17};
18
OK,下面分别创建对应的对象进行赋值
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2{
3 Person person;
4 person.age = 20;
5 person.sex = 1;
6}
7
8void createTeacher()
9{
10 Teacher teacher;
11 teacher.age = 20;
12 teacher.sex = 1;
13 teacher.level = 3;
14}
15
16void createStudent()
17{
18 Student student;
19 student.age = 20;
20 student.sex = 1;
21 student.score = 60;
22}
23
写完代码,其实就可以发现,太多的重复了,那如何解决呢,别着急,我们来画一下这几个类的内存模型,我们如何知道其内存如何排放呢,其实只要调试起来,在内存窗口观察变化即可。
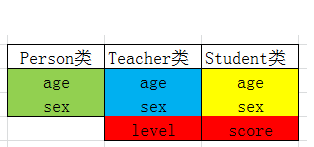
在这内存模型中我们也可以发现,其实这三个类的前面部分内存都是一样的,也就是绿,蓝,黄 三部分,下面我们再通过汇编来验证下
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
227: person.age = 20;
300401048 C7 45 F8 14 00 00 00 mov dword ptr [ebp-8],14h ;age 也是person首地址
428: person.sex = 1;
50040104F C7 45 FC 01 00 00 00 mov dword ptr [ebp-4],1 ;sex
6
7
833: Teacher teacher;
934: teacher.age = 20;
1000401078 C7 45 F4 14 00 00 00 mov dword ptr [ebp-0Ch],14h ;age 也是teacher首地址
1135: teacher.sex = 1;
120040107F C7 45 F8 01 00 00 00 mov dword ptr [ebp-8],1 ;sex
1336: teacher.level = 3;
1400401086 C7 45 FC 03 00 00 00 mov dword ptr [ebp-4],3 ;level
15
16
1741: Student student;
1842: student.age = 20;
19004010B8 C7 45 F4 14 00 00 00 mov dword ptr [ebp-0Ch],14h ;age 也是student首地址
2043: student.sex = 1;
21004010BF C7 45 F8 01 00 00 00 mov dword ptr [ebp-8],1 ;sex
2244: student.score = 60;
23004010C6 C7 45 FC 3C 00 00 00 mov dword ptr [ebp-4],3Ch ;score
24
这里因为对于的结构体的大小不一样,所以在分配空间时,其对应的对象首地址肯定也不一样。但是从汇编上分配的大小和顺序也能看出,其前面的部分内存其实是一样的。
那么既然一样,我们能不能去掉重复呢,想想之前的所学知识,我们是不是可以使用包含解决,动手试试
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2{
3 int age; //年龄
4 int sex; //性别
5};
6struct Teacher
7{
8 Person person;
9 int level;//教师等级
10};
11struct Student
12{
13 Person person;
14 int score;//分数
15};
16
在Teacher类和Student类中分别包含Person类,好像重复问题解决了。而且内存模型也是和之前一样的,你可以想象下直接将Person的内存模型往右边的Teacher类和Student类复制。
但是,此时你会发现新问题又来了,那就是给对象赋值需要发生变化
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2{
3 Person person;
4 person.age = 20;
5 person.sex = 1;
6}
7
8void createTeacher()
9{
10 Teacher teacher;
11 teacher.person.age = 20;
12 teacher.person.sex = 1;
13 teacher.level = 3;
14}
15
16void createStudent()
17{
18 Student student;
19 student.person.age = 20;
20 student.person.sex = 1;
21 student.score = 60;
22}
23
前面说了其内存模型不变,既然内存模型不变,那么虽然赋值代码发生了变化,汇编代码应该还是一样的吧,我们来看一下汇编代码。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
225: person.age = 20;
300401048 C7 45 F8 14 00 00 00 mov dword ptr [ebp-8],14h
426: person.sex = 1;
50040104F C7 45 FC 01 00 00 00 mov dword ptr [ebp-4],1
6
7
831: Teacher teacher;
932: teacher.person.age = 20;
1000401078 C7 45 F4 14 00 00 00 mov dword ptr [ebp-0Ch],14h
1133: teacher.person.sex = 1;
120040107F C7 45 F8 01 00 00 00 mov dword ptr [ebp-8],1
1334: teacher.level = 3;
1400401086 C7 45 FC 03 00 00 00 mov dword ptr [ebp-4],3
15
16
1739: Student student;
1840: student.person.age = 20;
19004010B8 C7 45 F4 14 00 00 00 mov dword ptr [ebp-0Ch],14h
2041: student.person.sex = 1;
21004010BF C7 45 F8 01 00 00 00 mov dword ptr [ebp-8],1
2242: student.score = 60;
23004010C6 C7 45 FC 3C 00 00 00 mov dword ptr [ebp-4],3Ch
24
和前面的汇编代码是一模一样,但是我们又不是写汇编代码,我们是写C++代码,虽然其底层的实现是一样的,但是对于我们开发人员来说是不一样的,哪不一样呢,逻辑上不一样
就拿Student类来说,单独考虑这么一个类,里面有age,sex,score成员,学生有姓名年龄,很符合逻辑。但是现在呢,有个person成员,在这个person成员里面才包含了age和sex,给人的感觉就是学生有个人,人里面有姓名和年龄,从逻辑和描述上来说是很别扭。
所以,继承就出现了,来看一下继承的语法
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
2{
3 int age; //年龄
4 int sex; //性别
5};
6
7//使用 : 表示继承,后面跟需继承的类名
8struct Teacher: Person
9{
10 int level;//教师等级
11};
12
13//使用 : 表示继承,后面跟需继承的类名
14struct Student: Person
15{
16 int score;//分数
17};
18
19void createPerson()
20{
21 Person person;
22 person.age = 20;
23 person.sex = 1;
24}
25
26void createTeacher()
27{
28 Teacher teacher;
29 teacher.age = 20;
30 teacher.sex = 1;
31 teacher.level = 3;
32}
33
34void createStudent()
35{
36 Student student;
37 student.age = 20;
38 student.sex = 1;
39 student.score = 60;
40}
41
好了,现在既解决了重复的问题,也解决了使用包含时的逻辑上问题。那么这个继承的内存模型还是一样么?是的,内存模型还是没有发生任何变化,我们还是从汇编的角度再来对比下代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
227: person.age = 20;
300401048 C7 45 F8 14 00 00 00 mov dword ptr [ebp-8],14h
428: person.sex = 1;
50040104F C7 45 FC 01 00 00 00 mov dword ptr [ebp-4],1
6
7
833: Teacher teacher;
934: teacher.age = 20;
1000401078 C7 45 F4 14 00 00 00 mov dword ptr [ebp-0Ch],14h
1135: teacher.sex = 1;
120040107F C7 45 F8 01 00 00 00 mov dword ptr [ebp-8],1
1336: teacher.level = 3;
1400401086 C7 45 FC 03 00 00 00 mov dword ptr [ebp-4],3
15
16
1741: Student student;
1842: student.age = 20;
19004010B8 C7 45 F4 14 00 00 00 mov dword ptr [ebp-0Ch],14h
2043: student.sex = 1;
21004010BF C7 45 F8 01 00 00 00 mov dword ptr [ebp-8],1
2244: student.score = 60;
23004010C6 C7 45 FC 3C 00 00 00 mov dword ptr [ebp-4],3Ch
24
会发现其汇编代码和之前的是一摸一样,所以呢,其实对于继承,还阔以这么简单的理解,继承属于一种特殊的包含(包含父类对象在其首部)。
既然引出了继承,那么想必大家应该也明白了,
所谓的继承,就是一种代码重用机制,其本质就是数据的复制。使用继承,可以减少我们重复代码的编写(编译器帮我们干)
OK,在上一篇中,有提过struct和class唯一的区别就是权限不一样,编译器默认class中的成员为private 而struct中的成员为public。那么现在在继承中,还有个区别哦,那就是编译器默认class继承方式为private,而struct中继承方式为public。
对于C++而言,在编译器这块下了更多的功夫,尽可能的藏起来。
下面,我们来看一下这个private继承,首先,我们先来观察下父类成员私有后能不能被继承到子类
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2{
3private:
4 int m_age; //年龄
5 int m_sex; //性别
6};
7class Teacher : public Person //公有继承
8{
9private:
10 int m_level;//教师等级
11public:
12 Teacher()
13 {
14 //m_age = 10; err 成员 "Person::m_age" (已声明 所在行数 : 7) 不可访问
15 }
16};
17
报错了,说明当父类成员私有后,是不能继承到子类的,类似于老爸的私房钱,对于任何人来说都一直是私有的。
那么现在问题来了,在上一篇权限中说过,一般来说需要吧成员变量设置为私有,那么如果继承后访问不到,这个继承还有用么?其实还是一样的解决方案,给个公开的成员方法。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2{
3private:
4 int m_age; //年龄
5 int m_sex; //性别
6public:
7 void setData(int age,int sex)
8 {
9 m_age = age;
10 m_sex = sex;
11 }
12};
13class Teacher : public Person //公有继承
14{
15private:
16 int m_level;//教师等级
17public:
18 Teacher()
19 {
20 setData(4,5);
21 m_level = 7;
22 }
23};
24
OK,下面我们来探讨下 private成员是真的没有被继承吗?
首先,先打印下占用空间的大小
2
2
打印出了12,从这个结果可以猜测,Teacher类里面应该是有Person中的两个私有数据的,下面我们观察下内存分布来验证下
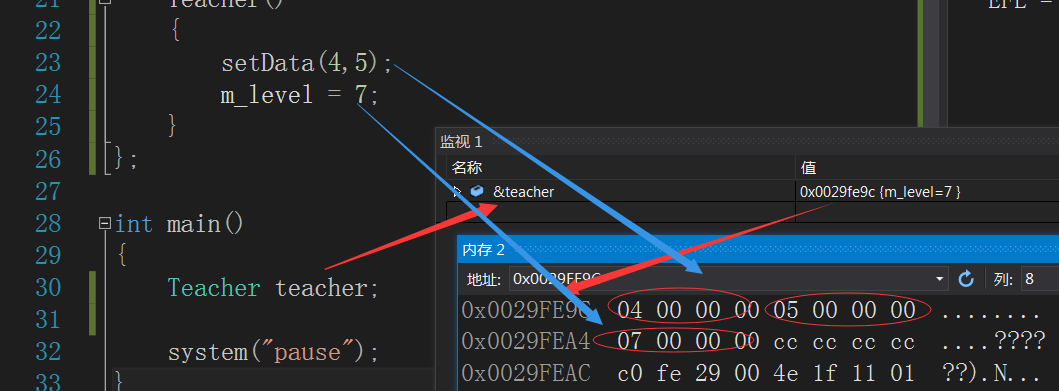
从内存分布来看,其实也可以看出来,父类中的私有成员是会被继承的,那么说明之前的报错都只是编译器不允许我们直接这样访问,那么,这时候强大的指针就该上场了,我们使用指针来访问私有父类数据
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2{
3private:
4 int m_level;//教师等级
5public:
6 Teacher()
7 {
8 //setData(4,5);
9 int *tmpThis = (int*)this;
10 *tmpThis = 4; //修改m_age
11 *(tmpThis+1) = 5; //修改m_sex
12 m_level = 7;
13 }
14};
15
其实为了子类访问父类的成员变量,C++还提供了一个protected的权限,我们来看一下作用
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2{
3protected:
4 int m_age; //年龄
5 int m_sex; //性别
6public:
7 void setData(int age,int sex)
8 {
9 m_age = age;
10 m_sex = sex;
11 }
12};
13class Teacher : public Person //公有继承
14{
15private:
16 int m_level;//教师等级
17public:
18 Teacher()
19 {
20 m_age = 4; //ok 子类可访问
21 m_sex = 5;// ok 子类可访问
22 m_level = 7;
23 }
24};
25
26int main()
27{
28 Person person;
29 //protected 外部不可直接访问
30 //person.m_age = 0; //err 成员 "Person::m_age" (已声明 所在行数 : 7) 不可访问
31 system("pause");
32}
33
从实验得出的结果看来,其实protected关键字相当于是给了子类一个直接访问的权限,对于外部来说还是一样的。
OK,讲完私有成员的继承后,我们该来看看这个私有的继承方式了,看如下代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
2{
3public:
4 int m_age; //年龄
5protected:
6 int m_sex; //性别
7public:
8 void setData(int age,int sex)
9 {
10 m_age = age;
11 m_sex = sex;
12 }
13};
14class Teacher : Person //默认会私有继承
15{
16private:
17 int m_level;//教师等级
18public:
19 Teacher()
20 {
21 m_age = 4; //ok 可访问
22 m_sex = 5;// ok 可访问
23 m_level = 7;
24 }
25};
26
27int main()
28{
29 Teacher teacher;
30 // “Person::m_age”不可访问,因为“Teacher”使用“private”从“Person”继承
31 //teacher.m_age = 10; 报错 不可访问
32 Person person;
33 person.m_age = 10; // ok
34 system("pause");
35}
36
从实验结果来看,所谓的继承方式其实是对于外部而言的,因为在Teacher内部,使用其父类的成员变量完全无区别,使用私有继承后,原本public的权限在外部却不能使用了。
下面总结下权限和继承的关系
2
3
4
5
6
2继承方式\成员权限 private protected public
3 private xx/xx ok/xx ok/xx
4 protected xx/xx ok/xx ok/xx
5 public xx/xx ok/xx ok/ok
6
其结果意思的:内部是否可访问/外部是否可访问,ok表示可访问,xx表示不可访问。
通过上面的实验,其实所谓的权限啥的,都是编译器层面做的限制,所以下面的例子方便起见我就都使用公有数据进行讲解了。
下面,我们看一下这个问题:为什么父类指针可以执行指向子类对象?先看代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2{
3public:
4 int m_age; //年龄
5 int m_sex; //性别
6};
7class Teacher : public Person
8{
9public:
10 int m_level;//教师等级
11};
12
13int main()
14{
15 Teacher teacher;
16 teacher.m_age = 1;
17 teacher.m_sex = 2;
18 teacher.m_level = 3;
19
20 //父类指针指向子类对象
21 Person *person = &teacher;
22 person->m_age = 5;
23 person->m_sex = 6;
24 //person->m_level = 7; err “m_level” : 不是“Person”的成员
25 system("pause");
26}
27
首先,来调试看一下内存数据
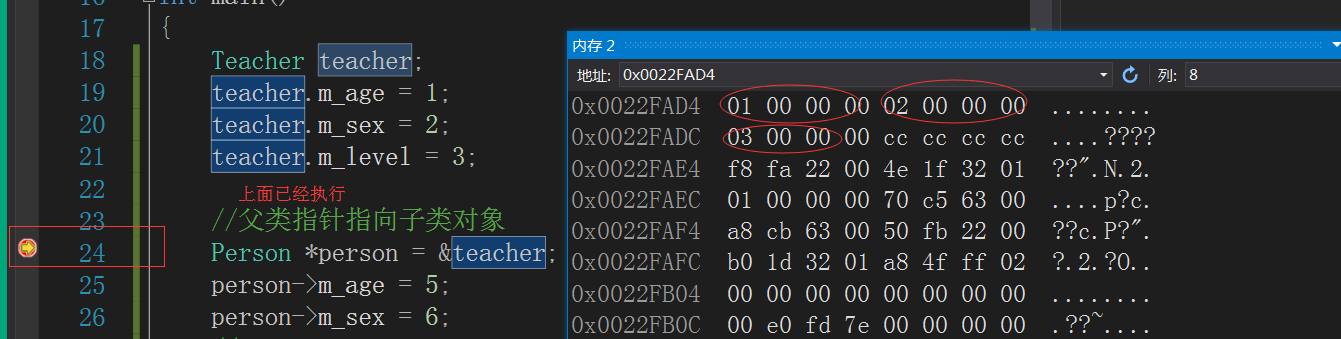
来看一下person修改的数据
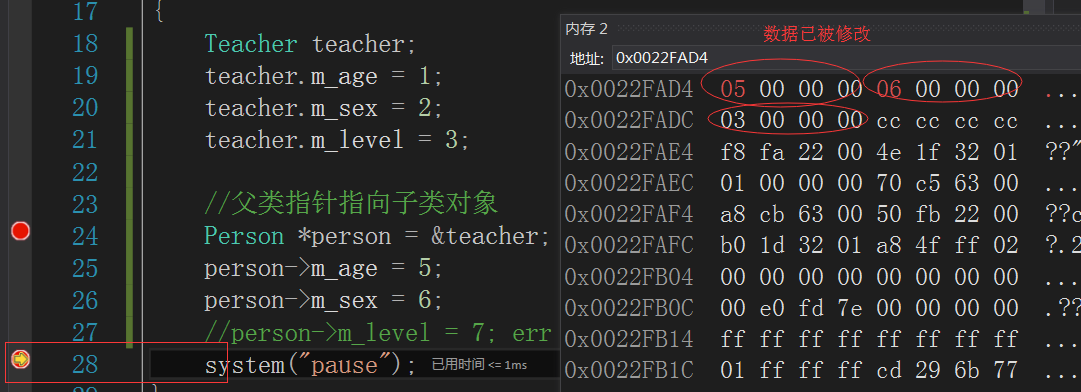
从这个内存数据的结果来看,虽然使用了父类指针,但是其修改和直接使用teacher修改的效果是一样的,我们来可以回顾下之前的内存模型。其实继承后,子类对象里面相当于包含了父类成员,父类对象复制过来的时候放在子类的最上面,看下图
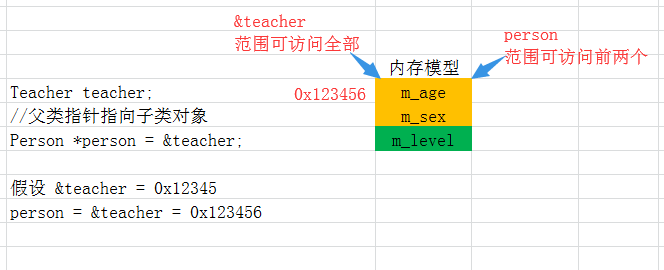
注意,图中的范围访问限制都是编译器做的哦,所以person对m_sex数据才不能修改。所以,父类指针指向子类对象,不管咋样,都只是会操作头部数据,所以是安全的。如果反过来呢?那可就不行了,因为父类的真实数据只有前两个,而当转成子类的指针时,访问的范围会扩大到3个,这样子就不安全了。
下面,再来看一个问题,基类的构造/析构顺序?
其实,这个问题已经可以直接回答了,因为上面有说过,继承,其实可以看成子类包含父类,而且该父类会位于全部成员的第一项。那么这个顺序其实可以转化为对象成员的初始化和析构顺序了,这个顺序在前面的析构/构造篇中可以找到,所以下面就直接给结论了
2
3
4
5
6
7
8
9
2 基类
3 成员对象
4 自己
5析构顺序:
6 自己
7 成员对象
8 基类
9
下面再来看一个问题,对于资源的分配和释放,我们是在子类构造/析构中写呢,还是父类构造/析构中写呢?
首先,对于良好的设计而言,根本不会出现这个问题,为什么呢?因为一般的成员数据都是定义成私有的,所以子类是没有办法进行访问(开发角度)。从类的封装角度上考虑,就算是没有继承,其单独的类(父类和子类)也是可以使用的,所以对于资源问题,我们只需保证在自己的类中对自己的成员数据资源进行分配和释放即可(自己的事情自己做)。
假设这样的情况,父类里的资源是公有的,所以子类是可以访问的,所以我在子类的构造和析构中对该资源进行了操作,那么会发现上面的构造和析构顺序就没什么用处了,因为此时你根本就不需要父类的构造和析构,虽然实现上是可行的,但是很容易造成资源的重复分配/释放问题。观察如下代码进行对比即可,正好对上面的顺序做一个回顾
先来看错误的代码示例
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2class A
3{
4public:
5 char *str;
6 A()
7 {
8 //此处若分配会造成内存泄露
9 }
10 ~A()
11 {
12 //此处若释放会找出重复释放
13 }
14};
15
16class B : public A
17{
18public:
19 B()
20 { //A::A() 此处编译器会帮我们调用A构造
21 str = new char[10];
22 }
23 ~B()
24 {
25 delete[] str;
26 }
27 //A::~A() 此处编译器会帮我们调用A析构
28};
29
正确的代码示例
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2class A
3{
4public:
5 char *str;
6 A()
7 {
8 str = new char[10];
9 }
10 ~A()
11 {
12 delete[] str;
13 }
14};
15
16class B : public A
17{
18public:
19 B()
20 { //A::A() 此处编译器会帮我们调用A构造
21 //此处不做任何处理,因为B中无资源
22 }
23 ~B()
24 {
25 //此处不做任何处理,因为B中无资源
26 }
27 //A::~A() 此处编译器会帮我们调用A析构
28};
29
记住一点即可,每一个类都是独立可使用的,也就是封装。
下面再来看一下最后这个例子
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
2{
3public:
4 A()
5 {
6 m_a = 1;
7 m_b = 2;
8 }
9 void test(){ cout << "A::test()" <<endl; }
10 void test(int){ cout << "A::test(int)" << endl; }
11
12public:
13 int m_a;
14 int m_b;
15};
16
17class B : public A
18{
19public:
20 B()
21 {
22 m_a = 3;
23 }
24 void test() { cout << "B::test()" << endl; }
25public:
26 int m_a;
27};
28
29int main()
30{
31 B bObj;
32 cout << bObj.m_a << endl;
33 bObj.test();
34 //bObj.test(1); err 编译错误
35 system("pause");
36}
37
此时,你会发现上面的成员有重名的情况,那么当调用的时候会调用谁的呢?
根据结果可以判断出来,调用的都是B类的,下面我们来看一下内存结构

你会发现,分配的空间和普通的是一样的。虽然有名字重复,但是父类的数据也都一样被继承下来了。所以对于底层来说,没有任何区别,编译完都是二进制,这边所谓的名字,都是给编译器看的而已,所以此时如果想调用基类的,那么需要明确作用域,如下代码:
2
3
4
5
2 cout << bObj.A::m_a << endl;
3 bObj.A::test();
4 bObj.A::test(1); //ok
5
此时,你会发现原先调用test(int)是编译报错的,现在加上父类的作用域后是OK了,这个是为什么呢?
之前学了重载,现在需要知道一个新的东西,叫做隐藏(编译器限制)
2
3
2隐藏: 作用域不同,只要同名就构成隐藏
3
所以,之前的编译报错,其实是因为A::test和A::test(int)都被隐藏了。
当存在继承关系时,派生类的作用域嵌套在其基类的作用域之内,如果一个名字在派生类的作用域内无法正确解析,则编译器将继续在外层的基类作用域中寻找该名字的定义。
那么C++为什么要有名称隐藏这种东西呢,按上述的案例,如果可以调用test(int)就比较舒服了?
名称解析规则表示,名称查找将在找到匹配名称的第一个范围内停止。此时,重载解析规则开始寻找可用函数的最佳匹配。重载解析通过从一组候选函数中选择最佳函数来工作,通过将参数的类型与参数的类型匹配来实现的。
如果没有名称隐藏,那么继承的重载函数集与当前设置给定类的重载函数集会混合,此时调用函数很容易产生二义性问题。有了名称隐藏,此时重载解析就将会按照你的预期进行。
所以名称隐藏机制虽然有时会感觉不太舒服(像上述案例,因为违反了类之间的is-a关系),但是也能规避掉大部分的错误情况。
