Netty源码分析第六章: 解码器
第四节: 分隔符解码器
基于分隔符解码器DelimiterBasedFrameDecoder, 是按照指定分隔符进行解码的解码器, 通过分隔符, 可以将二进制流拆分成完整的数据包
同样继承了ByteToMessageDecoder并重写了decode方法
我们看其中的一个构造方法:
2
3
4
2 this(maxFrameLength, true, delimiters);
3}
4
这里参数maxFrameLength代表最大长度, delimiters是个可变参数, 可以说可以支持多个分隔符进行解码
我们进入decode方法:
2
3
4
5
6
7
2 Object decoded = decode(ctx, in);
3 if (decoded != null) {
4 out.add(decoded);
5 }
6}
7
这里同样调用了其重载的decode方法并将解析好的数据添加到集合list中, 其父类就可以遍历out, 并将内容传播
我们跟到重载decode方法中:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
2 //行处理器(1)
3 if (lineBasedDecoder != null) {
4 return lineBasedDecoder.decode(ctx, buffer);
5 }
6 int minFrameLength = Integer.MAX_VALUE;
7 ByteBuf minDelim = null;
8
9 //找到最小长度的分隔符(2)
10 for (ByteBuf delim: delimiters) {
11 //每个分隔符分隔的数据包长度
12 int frameLength = indexOf(buffer, delim);
13 if (frameLength >= 0 && frameLength < minFrameLength) {
14 minFrameLength = frameLength;
15 minDelim = delim;
16 }
17 }
18 //解码(3)
19 //已经找到分隔符
20 if (minDelim != null) {
21 int minDelimLength = minDelim.capacity();
22 ByteBuf frame;
23
24 //当前分隔符否处于丢弃模式
25 if (discardingTooLongFrame) {
26 //首先设置为非丢弃模式
27 discardingTooLongFrame = false;
28 //丢弃
29 buffer.skipBytes(minFrameLength + minDelimLength);
30
31 int tooLongFrameLength = this.tooLongFrameLength;
32 this.tooLongFrameLength = 0;
33 if (!failFast) {
34 fail(tooLongFrameLength);
35 }
36 return null;
37 }
38 //处于非丢弃模式
39 //当前找到的数据包, 大于允许的数据包
40 if (minFrameLength > maxFrameLength) {
41 //当前数据包+最小分隔符长度 全部丢弃
42 buffer.skipBytes(minFrameLength + minDelimLength);
43 //传递异常事件
44 fail(minFrameLength);
45 return null;
46 }
47 //如果是正常的长度
48 //解析出来的数据包是否忽略分隔符
49 if (stripDelimiter) {
50 //如果不包含分隔符
51 //截取
52 frame = buffer.readRetainedSlice(minFrameLength);
53 //跳过分隔符
54 buffer.skipBytes(minDelimLength);
55 } else {
56 //截取包含分隔符的长度
57 frame = buffer.readRetainedSlice(minFrameLength + minDelimLength);
58 }
59
60 return frame;
61 } else {
62 //如果没有找到分隔符
63 //非丢弃模式
64 if (!discardingTooLongFrame) {
65 //可读字节大于允许的解析出来的长度
66 if (buffer.readableBytes() > maxFrameLength) {
67 //将这个长度记录下
68 tooLongFrameLength = buffer.readableBytes();
69 //跳过这段长度
70 buffer.skipBytes(buffer.readableBytes());
71 //标记当前处于丢弃状态
72 discardingTooLongFrame = true;
73 if (failFast) {
74 fail(tooLongFrameLength);
75 }
76 }
77 } else {
78 tooLongFrameLength += buffer.readableBytes();
79 buffer.skipBytes(buffer.readableBytes());
80 }
81 return null;
82 }
83}
84
这里的方法也比较长, 这里也通过拆分进行剖析
(1). 行处理器
(2). 找到最小长度分隔符
(3). 解码
首先看第一步行处理器:
2
3
4
2 return lineBasedDecoder.decode(ctx, buffer);
3}
4
这里首先判断成员变量lineBasedDecoder是否为空, 如果不为空则直接调用lineBasedDecoder的decode的方法进行解码, lineBasedDecoder实际上就是上一小节剖析的LineBasedFrameDecoder解码器
这个成员变量, 会在分隔符是\n和\r\n的时候进行初始化
我们看初始化该属性的构造方法:
2
3
4
5
6
7
8
9
10
11
12
13
14
2 int maxFrameLength, boolean stripDelimiter, boolean failFast, ByteBuf... delimiters) {
3 //代码省略
4 //如果是基于行的分隔
5 if (isLineBased(delimiters) && !isSubclass()) {
6 //初始化行处理器
7 lineBasedDecoder = new LineBasedFrameDecoder(maxFrameLength, stripDelimiter, failFast);
8 this.delimiters = null;
9 } else {
10 //代码省略
11 }
12 //代码省略
13}
14
这里isLineBased(delimiters)会判断是否是基于行的分隔, 跟到isLineBased方法中:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2 //分隔符长度不为2
3 if (delimiters.length != 2) {
4 return false;
5 }
6 //拿到第一个分隔符
7 ByteBuf a = delimiters[0];
8 //拿到第二个分隔符
9 ByteBuf b = delimiters[1];
10 if (a.capacity() < b.capacity()) {
11 a = delimiters[1];
12 b = delimiters[0];
13 }
14 //确保a是/r/n分隔符, 确保b是/n分隔符
15 return a.capacity() == 2 && b.capacity() == 1
16 && a.getByte(0) == '\r' && a.getByte(1) == '\n'
17 && b.getByte(0) == '\n';
18}
19
首先判断长度等于2, 直接返回false
然后拿到第一个分隔符a和第二个分隔符b, 然后判断a的第一个分隔符是不是\r, a的第二个分隔符是不是\n, b的第一个分隔符是不是\n, 如果都为true, 则条件成立
我们回到decode方法中, 看步骤2, 找到最小长度的分隔符:
这里最小长度的分隔符, 意思就是从读指针开始, 找到最近的分隔符
2
3
4
5
6
7
8
9
2 //每个分隔符分隔的数据包长度
3 int frameLength = indexOf(buffer, delim);
4 if (frameLength >= 0 && frameLength < minFrameLength) {
5 minFrameLength = frameLength;
6 minDelim = delim;
7 }
8}
9
这里会遍历所有的分隔符, 然后找到每个分隔符到读指针到数据包长度
然后通过if判断, 找到长度最小的数据包的长度, 然后保存当前数据包的的分隔符, 如下图:
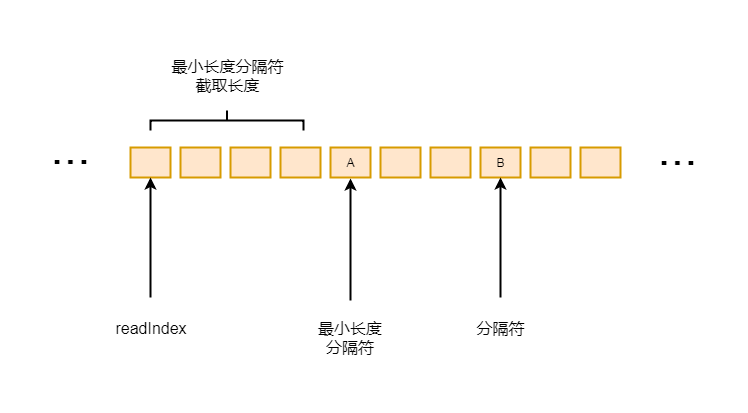
6-4-1
这里假设A和B同为分隔符, A分隔符到读指针的长度小于B分隔符到读指针的长度, 这里会找到最小的分隔符A, 分隔符的最小长度, 就readIndex到A的长度
我们继续看第3步, 解码:
if (minDelim !=
null) 表示已经找到最小长度分隔符, 我们继续看if块中的逻辑:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2ByteBuf frame;
3if (discardingTooLongFrame) {
4 discardingTooLongFrame = false;
5 buffer.skipBytes(minFrameLength + minDelimLength);
6 int tooLongFrameLength = this.tooLongFrameLength;
7 this.tooLongFrameLength = 0;
8 if (!failFast) {
9 fail(tooLongFrameLength);
10 }
11 return null;
12}
13if (minFrameLength > maxFrameLength) {
14 buffer.skipBytes(minFrameLength + minDelimLength);
15 fail(minFrameLength);
16 return null;
17}
18if (stripDelimiter) {
19 frame = buffer.readRetainedSlice(minFrameLength);
20 buffer.skipBytes(minDelimLength);
21} else {
22 frame = buffer.readRetainedSlice(minFrameLength + minDelimLength);
23}
24return frame;
25
if (discardingTooLongFrame) 表示当前是否处于非丢弃模式
, 如果是丢弃模式
, 则进入
if块
因为第一个不是丢弃模式
, 所以这里先分析
if块后面的逻辑
if (minFrameLength > maxFrameLength) 这里是判断当前找到的数据包长度大于最大长度
, 这里的最大长度使我们创建解码器的时候设置的
, 如果超过了最大长度
, 就通过
buffer.skipBytes(minFrameLength + minDelimLength) 方式
, 跳过数据包
+分隔符的长度
, 也就是将这部分数据进行完全丢弃
继续往下看
, 如果长度不大最大允许长度
, 则通过
if (stripDelimiter) 判断解析的出来的数据包是否包含分隔符
, 如果不包含分隔符
, 则截取数据包的长度之后
, 跳过分隔符
我们再回头看
if (discardingTooLongFrame) 中的
if块中的逻辑
, 也就是丢弃模式
:
首先将
discardingTooLongFrame设置为
false, 标记非丢弃模式
然后通过
buffer.skipBytes(minFrameLength + minDelimLength) 将数据包
+分隔符长度的字节数跳过
, 也就是进行丢弃
, 之后再进行抛出异常
分析完成了找到分隔符之后的丢弃模式非丢弃模式的逻辑处理
, 我们在分析没找到分隔符的逻辑处理
, 也就是
if (minDelim !=
null) 中的
else块
:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2 if (buffer.readableBytes() > maxFrameLength) {
3 tooLongFrameLength = buffer.readableBytes();
4 buffer.skipBytes(buffer.readableBytes());
5 discardingTooLongFrame = true;
6 if (failFast) {
7 fail(tooLongFrameLength);
8 }
9 }
10} else {
11 tooLongFrameLength += buffer.readableBytes();
12 buffer.skipBytes(buffer.readableBytes());
13}
14return null;
15
首先通过
if (!discardingTooLongFrame) 判断是否为非丢弃模式
, 如果是
, 则进入
if块
:
在
if块中
, 首先通过
if (buffer.readableBytes() > maxFrameLength) 判断当前可读字节数是否大于最大允许的长度
, 如果大于最大允许的长度
, 则将可读字节数设置到
tooLongFrameLength的属性中
, 代表丢弃的字节数
然后通过
buffer.skipBytes(buffer.readableBytes()) 将累计器中所有的可读字节进行丢弃
最后将
discardingTooLongFrame设置为
true, 也就是丢弃模式
, 之后抛出异常
如果
if (!discardingTooLongFrame) 为
false, 也就是当前处于丢弃模式
, 则追加
tooLongFrameLength也就是丢弃的字节数的长度
, 并通过
buffer.skipBytes(buffer.readableBytes()) 将所有的字节继续进行丢弃
以上就是分隔符解码器的相关逻辑
第六章总结
本章介绍了抽象解码器
ByteToMessageDecoder, 和其他几个实现了
ByteToMessageDecoder类的解码器
, 这个几个解码器逻辑都比较简单
, 同学们可以根据其中的思想剖析其他的比较复杂的解码器
, 或者根据其规则实现自己的自定义解码器
上一节: 行解码器
下一节: writeAndlush事件传播
