文章目录
-
ConcurrentLinkedQueue原理探究
-
(1). 结构
* (2). ConcurrentLinkedQueue原理介绍 -
1). offer操作
* 2). poll操作
* 3). peek操作
* 4). size操作
* 5). remove操作
* 6). contains操作1
21 * (3). 小结
2
ConcurrentLinkedQueue原理探究
ConcurrentLinkedQueue是线程安全的无界非阻塞队列,其底层数据结构使用单项链表实现,对于入队和出队操作使用CAS来实现线程安全.
(1). 结构
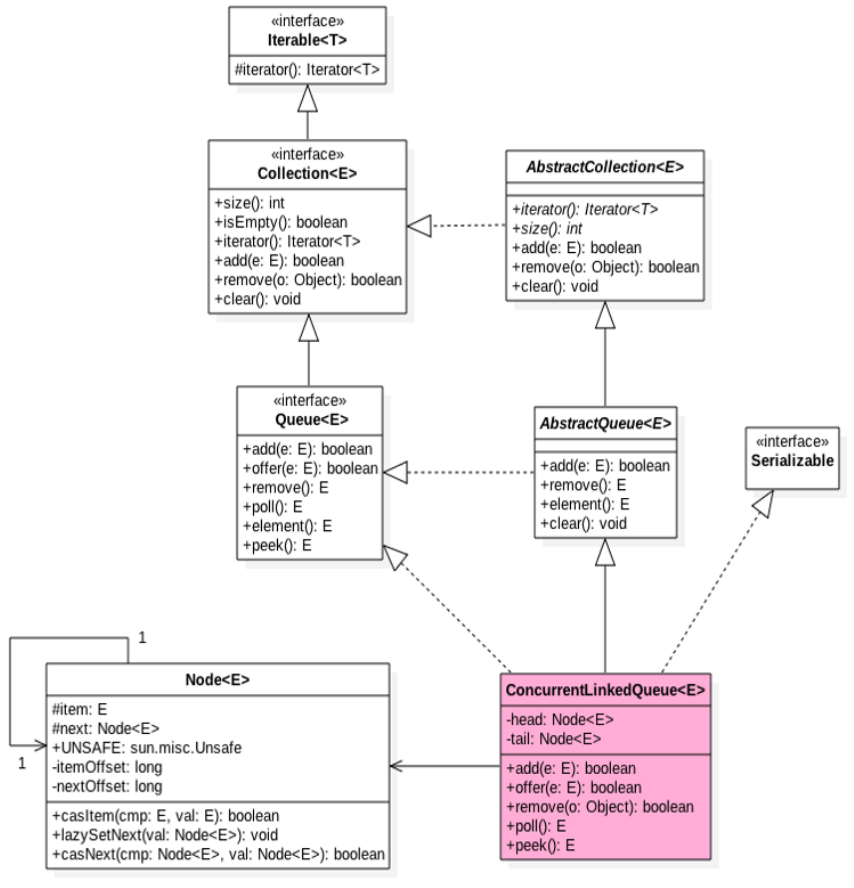
内部使用了两个Volatile类型的Node节点分别用来存放队列的首尾节点.Node节点内部则维护一个使用volatile修饰的变量item来存放节点的值
(2). ConcurrentLinkedQueue原理介绍
1). offer操作
在队列末尾添加一个元素,不能传入null(抛出NPE异常).内部使用CAS无阻塞算法,不会阻塞挂起线程.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2 // 检查如果传入空数据,抛出异常
3 checkNotNull(e);
4 final Node<E> newNode = new Node<E>(e);
5
6 // 自旋式的从尾节点插入
7 // 1、根据tail节点定位出尾节点(last node);2、将新节点置为尾节点的下一个节点;3、casTail更新尾节点
8 for (Node<E> t = tail, p = t;;) {
9 // p用来表示队列的尾节点,初始情况下等于tail节点
10 // q是p的next节点
11 Node<E> q = p.next;
12 if (q == null) {
13 // p是尾节点
14 // 设置p节点的下一个节点为新节点,设置成功则casNext返回true
15 // 否则返回false,说明有其他线程更新过尾节点
16 if (p.casNext(null, newNode)) {
17 // 如果p != t,则将入队节点设置成tail节点,更新失败了也没关系
18 // 因为失败了表示有其他线程成功更新了tail节点
19 // 这里使队列每添加两次,尾节点更新一次
20 if (p != t)
21 casTail(t, newNode);
22 return true;
23 }
24 }
25 // 执行了poll后可能会出现头节点自引用的情况
26 // 所以这里需要重新找新的head,因为新的head后面的节点才是激活的节点
27 else if (p == q)
28 // 先取得t的值,在执行t = tail,并取得新的t的值,然后比较这两个值是否相等。
29 // 这种情况表示在比较的过程中,tail被其他线程修改了,这时,我们就用新的tail为链表的尾
30 // 但如果tail没有被修改,则返回head,要求从头部开始,重新查找链表末尾。
31 p = (t != (t = tail)) ? t : head;
32 else
33 // 判断尾节点是否被改变,如果没有将p向后移动
34 p = (p != t && t != (t = tail)) ? t : q;
35 }
36}
37
38
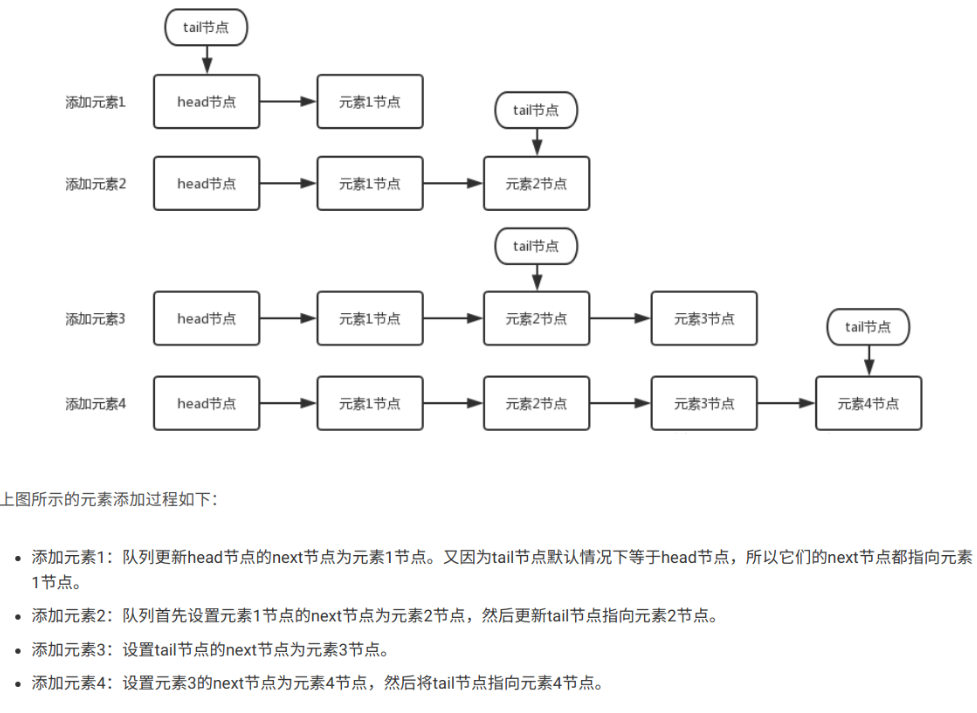
总而言之,当添加一个节点时会出现两种状态,p节点是尾节点,这种情况下可以插入.p节点不是尾节点(被其他线程修改),这种情况下需要走最后一个else分支将p指针向后移动.
另外,poll操作可能将头节点自引用,那么需要将p指向新的head然后重新寻找尾节点.
2). poll操作
在队列头部获取并移除一个元素,如果队列为空返回null.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
2 // 这个是goto标记
3 restartFromHead:// (1)
4 for (;;) {// (2)
5 for (Node<E> h = head, p = h, q;;) {
6 // p节点表示首节点,即需要出队的节点
7 E item = p.item;// (3)
8 // 不是空队列,且CAS操作成功,将头结点后一个节点的元素置空
9 if (item != null && p.casItem(item, null)) {// (4)
10 // 之前q被移动过,将p设置为头节点
11 if (p != h)// (5)
12 // 这一步将头结点自引用了,目的是为了下一步走向(7)
13 updateHead(h, ((q = p.next) != null) ? q : p);
14 return item;
15 }
16 // 如果头节点的元素为空或头节点发生了变化,这说明头节点已经被另外一个线程修改了。
17 // 那么获取p节点的下一个节点,如果p节点的下一节点为null,则表明队列已经空了
18 else if ((q = p.next) == null) {// (6)
19 // 这种情况下多是其他线程将队列中的元素取光了,那么重新设置头结点,返回null
20 updateHead(h, p);
21 return null;
22 }
23 // 运行到这里说明有其他线程添加了尾节点,使该队列不为空队列
24 else if (p == q)// (7)
25 // 重新执行该方法
26 continue restartFromHead;
27 // 将p向后移动,
28 else// (8)
29 p = q;
30 }
31 }
32}
33
34// 设置头结点,并将原来的头结点自引用,提醒其他线程更新头结点
35final void updateHead(Node<E> h, Node<E> p) {
36 if (h != p && casHead(h, p))
37 // 将旧的头结点h的next域指向为h
38 h.lazySetNext(h);
39}
40
41
总结一下,当没有其他线程打扰,方法将一步走到(5),然后重新设置头节点,并退出方法.如果其他线程这时将队列中的元素取光了,那么运行到(6).如果碰巧有其他线程添加了尾节点,那么运行到(7)或者(8),一般先运行(8),将p向后移动一个节点,下一次循环中走到(5)之后会将重新设置头结点,并将原h节点(尾节点)自引用,这样的情况下其他线程的代码会走向(7),重新执行该方法.之前提到的offer方法中也有这种情况的相对策略.
并不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点。只有当head节点里没有元素时,出队操作才会更新head节点。
3). peek操作
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2public E peek() {
3 restartFromHead:
4 for (;;) {
5 for (Node<E> h = head, p = h, q;;) {
6 E item = p.item;
7 if (item != null || (q = p.next) == null) {
8 // 执行peek()方法后head会指向第一个具有非空元素的节点。
9 updateHead(h, p);
10 return item;
11 }
12 else if (p == q)
13 continue restartFromHead;
14 else
15 p = q;
16 }
17 }
18}
19
20
4). size操作
计算当前队列元素个数,统计元素是不准确的
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2 int count = 0;
3 // first()获取第一个具有非空元素的节点,若不存在,返回null
4 // succ(p)方法获取p的后继节点,若p == p的后继节点,则返回head
5 for (Node<E> p = first(); p != null; p = succ(p))
6 if (p.item != null)
7 // Collection.size() spec says to max out
8 // 最大返回Integer.MAX_VALUE
9 if (++count == Integer.MAX_VALUE)
10 break;
11 return count;
12}
13
14// 获取队列中的第一个有效节点
15Node<E> first() {
16 restartFromHead:
17 for (;;) {
18 for (Node<E> h = head, p = h, q;;) {
19 boolean hasItem = (p.item != null);
20 if (hasItem || (q = p.next) == null) {
21 updateHead(h, p);
22 return hasItem ? p : null;
23 }
24 else if (p == q)
25 continue restartFromHead;
26 else
27 p = q;
28 }
29 }
30}
31
32// 获取传入节点的后继节点,如果该节点自引用,返回真正的头结点
33final Node<E> succ(Node<E> p) {
34 Node<E> next = p.next;
35 return (p == next) ? head : next;
36}
37
38
5). remove操作
如果队列中存在该元素则删除该元素,存在多个则删除第一个.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
2 if (o != null) {
3 // 删除为空直接返回false
4 Node<E> next, pred = null;
5 for (Node<E> p = first(); p != null; pred = p, p = next) {
6 boolean removed = false;
7 E item = p.item;
8 // 节点元素不为null
9 if (item != null) {
10 // 匹配不上让p和pred向后移动
11 if (!o.equals(item)) {
12 next = succ(p);
13 continue;
14 }
15 // 匹配上将该元素置空
16 removed = p.casItem(item, null);
17 }
18
19 // 获取删除节点的后继节点
20 next = succ(p);
21 // 将被删除的节点移除队列
22 if (pred != null && next != null) // unlink
23 pred.casNext(p, next);
24 if (removed)
25 return true;
26 }
27 }
28 return false;
29}
30
31
6). contains操作
判断队列中是否有制定对象,结果并不精确,但不牵扯方法内的多线程影响.
2
3
4
5
6
7
8
9
10
11
12
13
2 if (o == null) return false;
3 // 遍历队列
4 for (Node<E> p = first(); p != null; p = succ(p)) {
5 E item = p.item;
6 // 若找到匹配节点,则返回true
7 if (item != null && o.equals(item))
8 return true;
9 }
10 return false;
11}
12
13
(3). 小结
ConcurrentLinkedQueue底层使用单向链表数据结构来保存队列元素,使用非阻塞CAS算法,没有加锁.因为head和tail两个节点都是由volatile修饰的,本身可以保证可见性,所以只要保证对这两个变量操作的原子性即可.
offer操作是在tail后添加元素,实际上是调用CASNext方法,只有一个线程能成功,其他线程需要重新寻找尾节点.(队列新增两次,尾节点更新一次)
poll操作一样
