字符串
1、字符串是Python中最常用的数据类型。我们可以使用引号( ' 、 " 、""")来创建字符串
2、python三引号允许一个字符串跨多行,字符串中可以包含换行符、制表符以及其他特殊字符
3、在Python2中,普通字符串是以8位ASCII码进行存储的,而Unicode字符串则存储为16位unicode字符串,这样能够表示更多的字符集。使用的语法是在字符串前面加上前缀u。在Python3中,所有的字符串都是Unicode字符串。
例1:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2string_1 = "1" #定义一个数字类型的字符串
3string_2 = """
4面朝大海
5春暖花开
6"""
7#定义一个长字符串
8print(string)
9print(string_1)
10print(string_2)
11
12"""
13心有猛虎,细嗅蔷薇
141
15
16面朝大海
17春暖花开
18"""
19
字符串运算符
下表中变量a值为字符串 "Hello",b变量值为 "Python"
| 操作符 | 描述 | 实例 |
| + | 字符串连接 | print("2" + "1"):计算结果为"21"而不是"3" |
| * | 重复输出字符串 | a*2:输出结果:HelloHello |
| [ ] | 通过索引获取字符串中字符(第一位为0) | a[1]:输出结果 e |
| [ : ] | 截取字符串中的一部分,遵循左闭右开原则 | a[1:4]:输出结果 ell |
| in | 成员运算符 – 如果字符串中包含给定的字符返回 True | 'H' in a:输出结果 True,反之False |
| not in | 成员运算符 – 如果字符串中不包含给定的字符返回 True | 'M' not in a:输出结果False,反之True |
| % | 格式字符串 | print("%s"% a):输出结果Hello |
1 | 1 |
例2:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2list = [1,2,3,4,5]
3
4string_1 = string[0:4]#字符串分片后返回的是字符串
5print(string_1)
6list_1 = list[0:4] #列表分片后返回的是列表
7print(list_1)
8
9string_2 = string.split(",",1)#字符换切割后返回的是列表
10print(string_2)
11
12new_string = 'Hello World!'#字符串更新
13print(new_string[:6] + "jack")
14
15"""
16心有猛虎
17[1, 2, 3, 4]
18['心有猛虎', '细嗅蔷薇']
19Hello jack
20"""
21
Python转义字符
在需要在字符中使用特殊字符时,python用反斜杠( \ )转义字符,输出原始字符串
| 方法 | 描述 |
| \ | 转义符 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
1 | 1 |
例3:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2print("let's go") #使用单双引号来区分原始字符串
3print("C:\now")
4print("C:\\now")
5hello = "This is a rather long string containing\n\
6several lines of text just as you would do in C.\n\
7Note that whitespace at the beginning of the line is\
8 significant."#使用换行符和续行符
9
10print(hello)
11
12"""
13let's go
14let's go
15C:
16ow
17C:\now
18This is a rather long string containing
19several lines of text just as you would do in C.
20Note that whitespace at the beginning of the line is significant.
21"""
22
**注:**python输出原始字符串
如果在字符串中必须用到引号(如:'let's go'),如果直接这样写的话,python就会误会,报错:invalid syntax。要避免上面的错误,我们通常有两种方法:
1、使用转义字符():'let's go'
2、可以利用单引号和双引号来区分:"let's go"
字符串格式化
使用操作符百分号"%"实现(%也可用于求余数)
| 方法 | 描述 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %f | 格式化浮点数 |
1 | 1 |
注:
1、如下面例子中的"s"表示:百分号右边的值会被格式化为字符串,s指的是字符串
2、整数既可以用%d格式化也可以使用%s来格式化,只是类型不一样(一个为字符串一个为数字")
3、" %f "是可以指定精度的:(不指定时则默认输出6位小数):在%后面加上希望保留的小数位数。如:%.2f
4、**输出百分号:**使用百分号来转义百分号%f%%
5、在写格式化表达式时,前面的表达式必须为字符串
6、在有多个占位符的字符串中,可以使用元组传入多个格式化值,只有元组和字典可以格式化一个以上的值
例4:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2print("My name is %s and I am %d years old"%("jack",21)) #字符串+整形形式的格式化
3print("My name is %s and I am %s years old"%("jack",21))#%s既可以格式化整形又可以格式化字符串
4print("圆周率等于:%f" % 3.14)#格式化浮点型
5print("圆周率等于:%.2f" % 3.14)#格式化浮点型并指定精度
6print("利率比去年提高了:%.2f%%" % 1.2)#转义
7
8"""
9My name is jack and I am 21 years old
10My name is jack and I am 21 years old
11My name is jack and I am 21 years old
12圆周率等于:3.140000
13圆周率等于:3.14
14利率比去年提高了:1.20%
15"""
16
字符串方法
1、find()
描述:检测字符串中是否包含指定的子字符串,有则返回其所在索引值,无则返回-1
注:find()函数的返回值不是布尔类型,如果返回0,表示在索引0处找到了子字符串
2
3
4
5
6
7
8
9
2str.find(str, beg=0, end=len(string))
3参数
4str -- 指定检索的字符串
5beg -- 开始索引,默认为0。
6end -- 结束索引,默认为字符串的长度。
7返回值
8如果包含子字符串返回开始的索引值,否则返回-1
9
例5:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2
3string_1 = string.find("l")#未指定长度,默认全部:第一个符合的元素
4print(string_1)
5
6string_2 = string.find("l",7)#从索引为7处开始
7print(string_2)
8
9string_3 = string.find("l",3,4)#搜索区间为3-4
10print(string_3)
11
12string_4 = string.find("y")
13print(string_4)
14
15"""
162
179
183
19-1
20"""
21
2、join()
描述:将序列中的元素以指定字符连接(连接每个元素之间)成一个新的字符串。返回值为新的字符串
备注:使用join()函数时,被调用的两个对象都必须为字符串
2
3
4
5
6
7
2str.join(sequence)
3参数
4sequence -- 要连接的元素序列(把str加到sequence序列中)
5返回值
6返回通过指定字符连接序列中元素后生成的新字符串。
7
例6:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2string_2 = "-"
3string = string_2.join(string_1)
4print(string)
5
6s1 = "-"
7seq = ("In","me","the","tiger","sniffs","the","rose") # 元组序列
8print (s1.join(seq))
9
10list = ["In","me","the","tiger","sniffs","the","rose"]
11connection = "\n"
12new_string = connection.join(list)
13print(new_string)
14
15"""
16h-e-l-l-o-,-w-o-r-l-d
17In-me-the-tiger-sniffs-the-rose
18In
19me
20the
21tiger
22sniffs
23the
24rose
25"""
26
3、split()
描述:以str为分隔符,num:分割次数,返回值为分割后的字符串列表
备注:若不指定分隔符,则默认空格作为分割符。若不指定分割次数,则所有匹配的字符都会被分割
2
3
4
5
6
7
8
2str.split(str="", num=string.count(str))
3参数
4str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等
5num -- 分割次数。默认为 -1, 即分隔所有
6返回值
7返回分割后的字符串列表
8
例7:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2str_1 = str.split(",") #未指定切割次数
3print(str_1)
4
5str_2 = str.split(",",1)#指定切割次数
6print(str_2)
7
8str_3 = str.split(",",1)[1]#切割后进行索引
9print(str_3)
10
11"""
12['hello', 'world', 'A']
13['hello', 'world,A']
14world,A
15"""
16
4、count()
描述:返回str在string里面出现的次数,如果beg或者end指定则返回指定范围内str出现的次数
2
3
4
5
6
7
8
9
2str.count(sub, start= 0,end=len(string))
3参数
4sub -- 搜索的子字符串
5start -- 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
6end -- 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。
7返回值
8该方法返回子字符串在字符串中出现的次数。
9
例8:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3count_l = str.count("l")
4print("字母l字符串中出现的次数为:",count_l)
5
6count_l_1 = str.count("l",0,5)
7print("字母l字符串中出现的次数为:",count_l_1)
8
9print(str.count("2"))#没有找到,则返回0
10
11"""
12字母l字符串中出现的次数为: 3
13字母l字符串中出现的次数为: 2
140
15"""
16
5、replace()
描述:将字符串中的old(旧字符串)换成new(新的字符串)。max表示最大替换次数
2
3
4
5
6
7
8
9
2str.replace(old, new[, max])
3参数
4old -- 将被替换的子字符串。
5new -- 新字符串,用于替换old子字符串。
6max -- 可选字符串, 替换不超过 max 次
7返回值
8返回字符串中的old(旧字符串)替换成new(新字符串)后生成的新字符串,如果指定第三个参数max,则替换不超过max次
9
例9:
2
3
4
5
6
7
8
9
10
11
12
13
2
3new_str = str.replace("world","Jack")
4print(new_str)
5
6new_str_1 = str.replace("l","2",2)
7print(new_str_1)
8
9"""
10hello,Jack
11he22o,world
12"""
13
6、lower()
描述:用于将字符串中所有的大写字符转换为小写(该函数无参数)
例10:
2
3
4
5
6
7
8
9
10
11
2
3new_str = str.lower() #返回一个新字符串
4print(str)
5print(new_str)
6
7"""
8HELLO,WORLD
9hello,world
10"""
11
7、upper()
描述:用于将字符串中所有的小写字符转换为大写(该函数无参数)
例11:
2
3
4
5
6
7
8
9
10
11
2
3new_str = str.upper() #返回一个新字符串
4print(str)
5print(new_str)
6
7"""
8hello,world
9HELLO,WORLD
10"""
11
8、swapcase()
描述:用于将字符串中所有的大写字符转换为小写,小写字符转换为大写(该函数无参数)
例12:
2
3
4
5
6
7
8
9
10
11
2
3new_str = str.swapcase() #返回一个新字符串
4print(str)
5print(new_str)
6
7"""
8HELLO,world
9hello,WORLD
10"""
11
9、capitalize()
描述:把字符串的第一个字符大写,其余全部字符小写(该函数无参数)
例13:
2
3
4
5
6
7
8
9
10
11
2
3new_str = str.capitalize() #返回一个新字符串
4print(str)
5print(new_str)
6
7"""
8hello,WORLD
9Hello,world
10"""
11
10、endswith(obj, beg=0, end=len(string))
描述:检查字符串是否以obj结束,如果beg或者end指定则检查指定的范围内是否以obj结束,如果是,返回True,否则返回False.
例14:
2
3
4
5
6
7
8
9
10
11
12
2
3if str.endswith("world") == True: #全序列内搜索
4 print("字符串是以world结尾的")
5
6print(str.endswith("o",0,5))#指定搜索范围
7
8"""
9字符串是以world结尾的
10True
11"""
12
11、format()
格式化字符串。与使用%格式化差不多
例15:
2
3
4
2
3#网站名:baidu, 地址 www.baidu.com
4
12、len()
描述:len()方法返回对象(字符、列表、元组等)长度或项目个数
注:
len():函数计算是从1开始的,而索引是从0开始的
2
3
4
5
6
7
2len( s )
3参数
4s -- 对象。
5返回值
6返回对象长度
7
例16:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2list = [1,2,3,4,5,6,7]
3tuple = (1,2,3,4,5,6)
4dict = {1:2,3:4,"a":"b"}
5set = {1,2,3,4,5}
6
7print(len(string))
8print(len(list))
9print(len(tuple))
10print(len(dict))
11print(len(set))
12
13"""
149
157
166
173
185
19"""
20
13、index(str, beg=0, end=len(string))
描述:
1、index()方法检测字符串中是否包含子字符串str,如果包含子字符串返回开始的索引值,否则抛出异常
2、如果指定beg(开始)和end(结束)范围,则检查是否包含在指定范围内,该方法与find()方法一样,只不过如果str不在string中会报一个异常。
例17:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3index_world = str.index("l")
4print(index_world)
5
6index_world_1 = str.index("l",6)
7print(index_world_1)
8
9#index_world_2 = str.index("l",6,8)
10#print(index_world_2)
11#在范围内未找到报错:ValueError: substring not found
12
13"""
142
159
16"""
17
14、strip()
描述:strip()方法用于移除字符串头尾指定的字符(默认为空格)或字符序列
注:
1、该方法只能删除开头或是结尾的字符,不能删除中间部分的字符
2、除该方法外还有两个类似的函数:rstrip()和lstrip()
2
3
4
5
6
7
2str.strip([chars])
3参数
4chars --指定截取的字符。
5返回值
6返回截掉字符串左右两边的空格或指定字符(默认空白字符)后生成的新字符串
7
例18:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2
3new_str = str.strip()
4print(str)
5print(new_str)
6
7string = "...hello,world..."
8new_string = str.strip(".")#这样子删除后,字符串前后还会有空格
9print(string)
10print(new_string)
11
12string_1 = "...hello,world..."
13print(str.strip())#这样子删除后,字符串前后无空格
14
15"""
16 hello,world
17hello,world
18...hello,world...
19 hello,world
20hello,world
21"""
22
15、title()
描述:title()方法返回"标题化"的字符串,就是说所有单词的首个字母转化为大写,其余字母均为小写
注:
**istitle()方法:**如果字符串中所有的单词拼写首字母是否为大写,且其他字母为小写则返回True,否则返回False
例19:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3new_str = str.title()
4print(str)
5print(new_str)
6
7print(str.istitle())
8print(new_str.istitle())
9
10"""
11hello,world
12Hello,World
13False
14True
15"""
16
其他方法
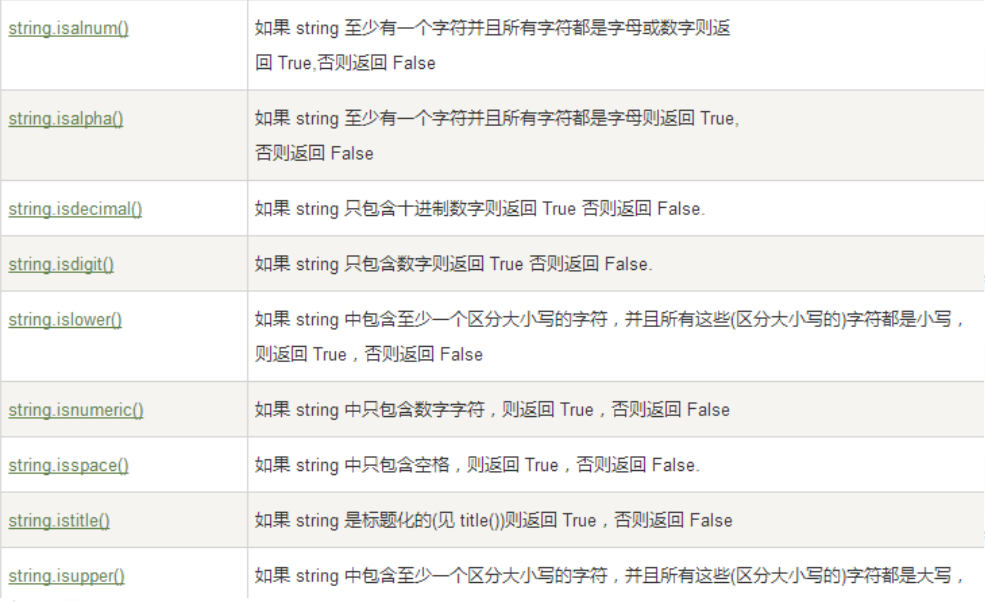
拓展
format是python2.6新增的一个格式化字符串的方法,相对于老版的%格式方法,它有很多优点。
1.不需要理会数据类型的问题,在%方法中%s只能替代字符串类型
2.单个参数可以多次输出,参数顺序可以不相同
3.填充方式十分灵活,对齐方式十分强大
1、通过位置来填充字符串
例1:
2
3
4
5
6
7
8
9
10
2print("hello {} i am {}".format('Kevin','Tom') )#未指定参数位置
3print("hello {0} i am {1} . my name is {0}".format('Kevin','Tom'))
4
5"""
6hello Kevin i am Tom
7hello Kevin i am Tom
8hello Kevin i am Tom . my name is Kevin
9"""
10
2、通过关键字来填充
例2:
2
3
4
2
3#hello Tom i am Kevin
4
3、通过列表索引来填充
例3:
2
3
4
5
6
7
8
9
2print("hello {name[1]} i am {name[0]}".format(name = name) )
3print("hello {0[0]} i am {0[1]}".format(name))
4
5"""
6hello san i am zhang
7hello zhang i am san
8"""
9
4、通过字典的key
例4:
2
3
4
5
6
7
8
2print("my name is {name}, age is {age},from {province}".format(**b_dict))
3print("my name is {b_dict[name]}, age is {b_dict[age]},from {b_dict[province]}".format(b_dict = b_dict))
4
5#上面代码的输出结果:
6#my name is chuhao, age is 20,from shanxi
7#my name is chuhao, age is 20,from shanxi
8
5、通过对象的属性
例5:
2
3
4
5
6
7
8
2 name_1 = "zhou"
3 name_2 = "hao"
4print("hello {my_name.name_1} i am {my_name.name_2}".format(my_name = my_name) )
5
6#上面代码的输出结果为:
7#hello zhou i am hao
8
转义
与%中%%转义%一样,formate中用两个大括号来转义
例6:
2
3
4
2
3#{ hello Kevin }
4
拓展
字符串是不可变对象,因此不能对字符串本身进行更新、修改等操作,所有方法都是在生成的新字符串上进行的修改
例7:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2string[0] = "a"
3print(string)
4#TypeError: 'str' object does not support item assignment
5
6string = "hello"
7string[0:2] = "12"
8print(string)
9#['hello', 2, 3, 4]
10
11
12#不能通过索引、切片等方法达到更新字符串本身的目的
13
14
15
例8:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
2list_1[0] = "hello"
3print(list_1)
4list_2 = list_1[0:2] + [7,8,9]
5print(list_2)
6#['hello', 2, 3, 4]
7#['hello', 2, 7, 8, 9]
8
9string = "hello"
10str = string[0:2] + "12"
11print(str)
12print(string)
13#he12
14#hello
15
16
17"""
181、列表时可变对象,因此可以通过分片、索引赋值的方法达到更新列表的目的
192、字符串例子:这种方法虽然可以达到更新字符串的目的,但是这种方法也是在生成了一个新的字符串上进行的更新修改,原本的字符串是没有变的
20"""
21
