python 数据类型
-
数据类型的作用
-
数据类型的分类
-
python数据类型特点
-
按数字分类
- 按可变不可变分类
- 容器型数据的循环遍历
- str 字符串类型
- 字符串常用方法
-
索引和切片
* 查找 -
-
find() 更常用 由数据查找索引
* 2. index() 由数据查找索引
* 3. count() 由数据查找出现次数
* 4. len() 查字符串长度- 修改
-
-
1.replace() 将旧字符串修改成新字符串
* 2.split() 根据分隔符多次分割成两部分,返回列表
* 3.partition() 根据分隔符分割一次成三部分,返回元祖
* 4. splitlines() 根据11`\n
11`多次分割成两部分,返回列表
* 5. join() 将全字符串的序列按拼接符拼接成新字符串
* 6. strip() 删除首尾指定字符
* 7 ljust() 使⽤指定字符填充⾄指定⻓度,左对齐返回1
21 * 判断
2- list 列表类型
- 列表的常⽤操作
-
查
-
-
索引和切片
* 2. index() 由数据查找索引
* 3. count() 由数据查找出现次数
* 4. len() 查字符串长度- 增
-
-
1.append():将数据以一个整体追加到列表结尾
* 2.expend():将序列遍历式逐一追加到列表结尾
* 2. += :将序列遍历式逐一追加到列表结尾
* 3.insert():将要追加的数据插入到指定位置1
21 * 删除
2 -
-
del 带下标删列表指定位置数据,不带下标删列表
* 2. pop():删除指定下标的数据(默认为最后⼀个),并返回删除的数据
* 3.remove():移除列表中某个数据的第⼀个匹配项- 修改
-
-
-
修改数据,不修改内存地址
* 2. 重新赋值,修改内存地址
* 3. reverse() 将整个列表进行逆置,数据顺序颠倒
* 4. sort() 将整个列表进行以升序或降序重新排列- 列表推导式
- tuple 元组类型
- 元组的常⽤操作
-
-
查询
-
- 索引和切片
* 2. index() 由数据查找索引
* 3. count() 由数据查找出现次数
* 4. len() 查字符串长度
- dict 字典类型
- 字典的常⽤操作
- 索引和切片
-
获取数据
* 添加和修改元素
* update() 字典合并(更新字典)
* 删除 -
- del 带下标删字典指定键数据,不带下标删字典
* 2. pop():删除指定下标的数据(默认为最后⼀个),并返回删除的数据
- set 集合数据
- 字典的常⽤操作
- del 带下标删字典指定键数据,不带下标删字典
-
数据类型转换
数据类型的作用
如果说:
程序是用来
处理数据的,那么
变量就是用来
存储并快速找到数据的,而
数据类型就是为了
更充分的利用内存空间及更有效率的分类管理数据。
数据类型的分类
python数据类型特点
- 不用特意指定,赋值时其会自动检测值得数据类型。
按数字分类
数据类型
数字型
非数字型
int 整型
float 浮点型
bool 布尔型
str 字符串
tuple 元祖
list 列表
dict 字典
set 集合
在 Python 中,大部分 非数字型变量 都支持以下特点:
- 都是一个 序列 sequence,也可以理解为 容器
- 根据索引取值 [] 和 切片 (字典靠key取值,不能切片)
- 遍历 for in
- 计算长度、最大/最小值、比较、删除
- 拼接 + 和 重复 * (字典和集合不能拼接和重复)
按可变不可变分类
数据类型
不可变类型
可变类型
int 整型
float 浮点型
bool 布尔型
str 字符串
tuple 元祖
list 列表
dict 字典
set 集合
容器型数据的循环遍历
请看python 循环语句 https://blog.csdn.net/weixin_45303361/article/details/97658718
str 字符串类型
凡是用一对或三对引号(双引号或单引号,但不可混用)引起来的内容皆称为字符串。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2 "今年8岁。" # 一个引号的字符串回车后的样子
3str2 = 'I\'m,kangkang.'
4str3 = """我叫'狗蛋',
5今年8岁。""" # 三个引号的字符串回车后的样子
6str4 = '''我叫'狗蛋',
7今年8岁。'''
8
9执行结果: |我叫'狗蛋',今年8岁。
10 |I'm,kangkang.
11 |我叫'狗蛋',
12 |今年8岁。
13 |我叫'狗蛋',
14 |今年8岁。
15 |我叫'狗蛋',
16 |今年8岁。
17
18
由执行结果可以看出:
- 使用一个引号标识字符串时,若其中还需要使用引号,则必须
使用另一种引号或使用转义字符(\’ 或")。在字符串中使用回车时,打印时仅会
一行显示(不会换行显示,即与不打回车一致)。
- 使用三个引号标识字符串时,若其中还需要使用引号,则什么引号皆可使用。在字符串中使用回车时,打印时会
两行显示(会换行显示,即与使用 “\n” 一致)。
字符串常用方法
索引和切片
所谓“下标”,就是编号,通过这个编号就能找到相应的存储空间,取出其中的数据。
字符串实际上就是字符的数组,如字符串name = ‘hello word’,在内存中的实际存储如下:
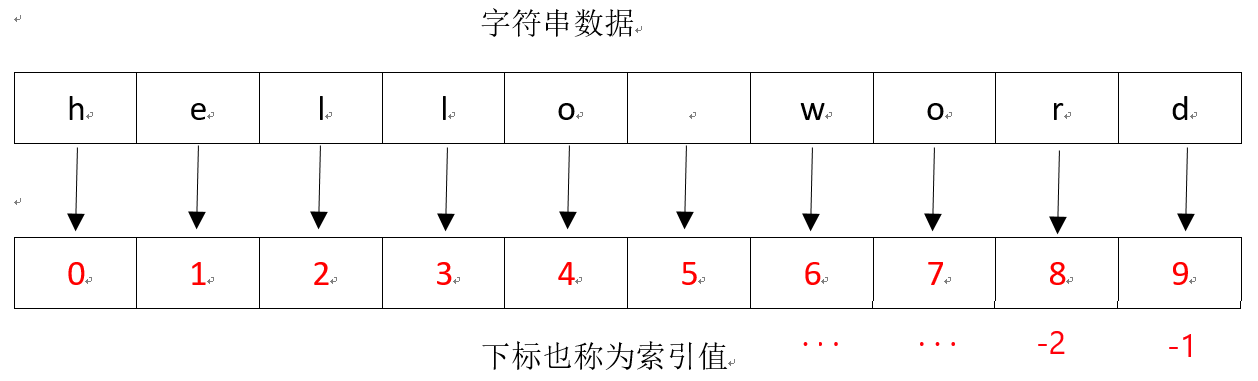
红色数字便是下标也称为索引值,索引计数
从0开始。其可以用于索引和切片。
索引为根据一个下标,取出一个数据,并将其生成一个字符串输出。
- 格式为:字符串[下标]
- 下标可为负,表示从右往左数第几个
切片为根据一个下标范围,取出多个数据,并将其生成一个字符串输出。
- 格式为:字符串[开始下标:结束下标:步长] ,步长表示选取间隔
- 其中下标和步长可正可负。 下标为负,表示从右往左数第几个;步长为负表示从右往左取值**。
- 切片规则:
包括开始下标数据,不包括结束下标数据并且
开始到结束的方向需要与步长的方向一致,否则取值为空
-
切片顺序:先取开始下标的数据作为第一个数据,然后再根据步长取其他值,而非根据开始下标加上步长后再取第一个数据。
-
省略开始下标表示从0开始取值,省略结束下标表示取到最后,省略步长时最后一个冒号也可省,表示从左到右依次取值。
2
3
4
5
6
7
8
9
10
11
12
2print(name[3])
3print(name[-3])
4print(name[2:8:2])
5print(name[-2:-8:-2])
6
7执行结果为:|l
8 |o
9 |low
10 |rwo
11
12
查找
1
.find()
由数据从左到右查 找索引, 无则返回-1
1
.rfind()
由数据从右到左查找索引, 无则返回-1
2
.index()
由数据从左到右查找索引 ,无则报错
2
.rindex()
由数据从右到左查找索引,无则报错
3
.count()
由数据查出现次数
4
len()
由字符串数据查字符串长度
5
max()
在同类型数据中查找到最大值 (“啊”>“A”>“a”>“1”)
5
min()
在同类型数据中查找到最小值
1. find() 更常用 由数据查找索引
- 格式为:字符串A.find(要查询的字符串B, start=开始下标, end=结束下表)
- 检测要查询的字符串B是否包含在 字符串A的指定范围(开始下标和结束下标之间,不包含结束下标)
- 若在指定范围内,则
返回第一次查询到的字符串A第一位索引值,不在则返回 -1
-
开始下标和结束下标可以省略,表示搜索全文,不可仅省略开始下标
-
find()表示从左往右查找,rfind()表示从右往左查找
-
无论find()还是rfind(),其开始到结束的方向必须是从左到右
2
3
4
5
6
7
8
2print(name.find("ll", 1, 8))
3print(name.rfind("ll", -1, 1))
4
5执行结果为:|2
6 |-1
7
8
2. index() 由数据查找索引
- 格式为:字符串A.index(要查询的字符串B, start=开始下标, end=结束下表)
- 检测要查询的字符串B是否包含在 字符串A的指定范围(开始下标和结束下标之间,不包含结束下标)
- 若在指定范围内,则
返回第一次查询到字符串A的第一位索引值,不在则报错
-
开始下标和结束下标可以省略,表示搜索全文,不可仅省略开始下标
-
index()表示从左往右查找,rindex()表示从右往左查找
-
无论index()还是rindex(),其开始到结束的方向必须是从左到右
2
3
4
5
6
7
8
2print(name.index("ll", 1, 8))
3print(name.rindex("ll", -1, 1))
4
5执行结果为:|2
6 |ValueError: substring not found
7
8
3. count() 由数据查找出现次数
格式为:字符串A.count(要查找的字符串B, start=开始下标, end=结束下标)
- 检测要查询的字符串B是否包含在 字符串A的指定范围(开始下标和结束下标之间,不包含结束下标)
- 开始下标和结束下标可以省略,表示搜索全文,不可仅省略开始下标
- 若在指定范围内,则
返回出现的次数,不在则返回0
2
3
4
5
6
7
8
9
10
2print(name.count("l", 1, 8))
3print(name.count("q"))
4print(name.count("o", 5))
5
6执行结果为:|2
7 |0
8 |1
9
10
4. len() 查字符串长度
格式为:len(要查找的字符串B)
-
检测要查询的字符串B的长度,返回int型
2
3
4
5
6
2print(len(name))
3
4执行结果为:|10
5
6
修改
因为字符串是不可变类型,所以使用其修方法时必须用变量接收,若不接受,执行后不会报错,但不会修改任何数据、起到任何效果。
1
.replace()
将旧字符串修改成新字符串
2
.split()
从左侧开始根据分隔符多次分割成两部分,返回列表
2
.rsplit()
从右侧开始根据分隔符多次分割成两部分,返回列表
3
.partition()
从左侧开始根据分隔符分割一次成三部分,返回元祖
3
.rpartition()
从右侧开始根据分隔符分割一次成三部分,返回元祖
4
splitlines()
根据\n多次分割成两部分,返回列表
5
.join()
将全字符串的序列按拼接符拼接成新字符串
6
.strip()
删除首尾空白字符,也可删指定字符
6
.lstrip()
仅删除首部空白字符,也可删指定字符
6
.rstrip()
仅删除尾部空白字符,也可删指定字符
7
.ljust()
使⽤指定字符==(默认空格)填充⾄指定⻓度==,左对齐返回
7
.rjust()
使⽤指定字符(默认空格)填充⾄指定⻓度,右对齐返回
7
.center()
使⽤指定字符(默认空格)填充⾄指定⻓度,居中对齐返回
8
. capitalize()
将字符串第⼀个字符转换成⼤写
9
. title()
将字符串每个单词首字母转换成⼤写
10
. lower()
将字符串所有字母转换成小写
11
. upper()
将字符串所有字母转换成大写
1.replace() 将旧字符串修改成新字符串
- 格式为:字符串A.replace(旧字符串, 新字符串, 修改次数)
- 含义:
将字符串A中的N个旧字符串修改成新字符串,N为修改次数。
-
若字符串A中不包含旧字符串,不会修改也不会报错。
-
若省略修改次数或修改次数超过旧字符串出现次数,则会将旧字符串全部修改为新字符串。不会报错
2
3
4
5
6
7
8
9
10
2print(name.replace("o", "oo", 1))
3print(name.replace("o", "o", 8))
4print(name.rindex("oo","www"))
5
6执行结果为:|helloo word
7 |helloo woord
8 |hello word
9
10
第二行执行结果不是6个o 是因为字符串为不可变类型。
2.split() 根据分隔符多次分割成两部分,返回列表
- 格式为:字符串.replace("分割子串", 分割次数)
- 当字符串中存在分割子串时,会返回一个
列表,其中包含根据
分割子串前后各生成的新字符串;当字符串中不包含分割字串时,不会报错,只是不会有任何分割
-
省略分割次数或分割次数大于分割子串出现的次数,则会将所有分割子串全部分割
-
rsplit()表示从右侧开始分割
2
3
4
5
6
7
8
2print(name.rsplit("o", 8))
3print(name.split("oo"))
4
5执行结果为:|['hell', ' w', 'rd']
6 |['hello word']
7
8
3.partition() 根据分隔符分割一次成三部分,返回元祖
- 格式为:字符串.partition("分割子串")
- 若字符串中存在分割子串,则会返回一个
元祖其中包括以分割子串将字符串
分割成的三个字符串:分割子串前、分割子串和分割子串后
-
若字符串中不存在分割子串,不会报错,会返回一个元祖其中包括原字符串和'', ''(两个单引号引起来的逗号)
2
3
4
5
6
7
8
2print(name.partition("ll"))
3print(name.rpartition("oo"))
4
5执行结果为:|('he', 'll', 'o word')
6 |('hello word', '', '')
7
8
4. splitlines() 根据\n多次分割成两部分,返回列表
- 格式为:字符串.splitlines()
- 没有任何参数
- 按照\n分隔 ,返回一个
列表,其中包含多个\n前和\n后形成的字符串
-
若不存在\n,则会返回一个仅包含原字符串的列表
2
3
4
5
6
7
8
9
10
2name1 = "hel\nlo \nword"
3print(name.splitlines())
4print(name1.splitlines())
5
6执行结果为:|['hello wo\trd']
7 |['hel', 'lo ', 'word']
8
9
10
5. join() 将全字符串的序列按拼接符拼接成新字符串
-
格式为:拼接符.join(全字符串序列)
-
全字符串序列包括列表、元祖、字典、集合。若为字典则只拼接键
-
若序列不是全为字符串或拼接符不是字符串会报错
2
3
4
5
6
7
8
9
10
11
12
2t1 = ('红', '包', '拿', '来')
3print('$'.join(list1))
4print('¥'.join(t1))
5tuple1 = {"name": "xiao", "age": 13}
6print("%%".join(tuple1))
7
8执行结果为:|恭$喜$发$财
9 |红¥包¥拿¥来
10 |name%%age
11
12
6. strip() 删除首尾指定字符
- 格式为: 字符串.strip("指定字符")
- 若
不指定字符,则默认删除空白字符(\t、\n、空格)
-
若指定字符,则会删除首尾的指定字符
-
若首位没有要删除的字符,不会报错
-
lstrip()表示删除首部的空白字符,rstrip()表示删除尾部的空白字符
2
3
4
5
6
7
8
9
10
11
2name1 = "eeeelel \t hello word \n"
3print(name.strip())
4print(name.strip("ee"))
5print(name1.strip("ee"))
6
7执行结果为:|hello word
8 | \t hello word \n
9 |lel hello word
10
11
7 ljust() 使⽤指定字符填充⾄指定⻓度,左对齐返回
- 格式为: 字符串.ljust(指定长度, "指定字符")
- 若
不指定字符,则默认使用空格填充,若指定字符,则会按照指定字符填充
-
不可不指定长度,若指定长的小于原字符串长度,不会报错,仅会返回原字符串,不会加以任何修改
-
rjust()表示有对齐
-
center()表示居中对齐,若需填充的字符为奇数,居中对齐时左侧会多一个
2
3
4
5
6
7
8
9
10
11
12
2print(name.ljust(15, "-"))
3print(name.rjust(15))
4print(name.rjust(5, "-"))
5print(name.center(15, "-"))
6
7执行结果为:|hello word-----
8 | hello word
9 |hello word
10 |---hello word--
11
12
判断
所谓判断即是判断真假,返回的结果是布尔型数据类型:True 或 False。
1
.startswith()
检查字符串是否是以指定⼦串开头,可指定范围检测
2
.endswith()
检查字符串是否是以指定⼦串结尾,可指定范围检测
3
.isalpha()
判断字符串有并且所有字符都是字⺟
4
.isdigit()
判断字符串有且只有数字
5
.isalnum()
判断字符串有且所有字符都是字⺟或数字
6
.isspace()
如果字符串中只包含空⽩字符(\t、\n、空格)
list 列表类型
- 格式为:变量名=[2, 2.2, True, "字符串", [列表], (元祖), {字典}]
- 凡是用一对中括号[]引起来的内容皆称为列表,为
可变类型
- 列表嵌套:变量名=[[], [], []], 定义空列表:变量名=[]
- 列表可以⼀次性存储多个不同数据,但为了方便循环遍历处理数据,一般放置相同类型的数据
列表的常⽤操作
列表为
可变类型,使用常用操作,是在原列表中修改数据,修改前后期
id(数据储存地址)不变,所以
不需要使用原变量接收改变后的数据,进行重新赋值。如果
重新赋值,不会在原列表进行修改,而是新建一列表然后复制,即
其id(数据储存地址)回发生变化
查
1
列表[下标]
索引为根据一个下标,取出一个数据
1
列表[下标范围]
切片为根据一个下标范围,取出多个数据
2
.index()
由数据找索引 ,无则报错
3
.count()
由数据查出现次数
4
len()
由列表数据查字符串长度
5
max()
在同类型数据中查找到最大值 (“啊”>“A”>“a”>“1”)
5
min()
在同类型数据中查找到最小值
6
数据 in 列表
判断数据是否在列表中,在返回Ture
6
数据 not in 列表
判断数据是否在列表中,在返回False
1. 索引和切片
索引为根据一个下标,取出一个数据,并将以数据
原类型输出。
- 格式为:列表[下标]
- 下标若不小于列表长度,否则会报错(
下标越界)
- 下标可为负,表示从右往左数第几个
切片为根据一个下标范围,取出多个数据,并将其生成一个新列表输出。
- 格式为:列表[开始下标:结束下标:步长] ,步长表示选取间隔
- 其中下标和步长可正可负。 下标为负,表示从右往左数第几个;步长为负表示从右往左取值**。
- 切片规则:
包括开始下标数据,不包括结束下标数据并且
开始到结束的方向需要与步长的方向一致,否则取值为空
-
切片顺序:先取开始下标的数据作为第一个数据,然后再根据步长取其他值,而非根据开始下标加上步长后再取第一个数据。
-
省略开始下标表示从0开始取值,省略结束下标表示取到最后,省略步长时最后一个冒号也可省,表示从左到右依次取值。
2
3
4
5
6
7
8
2print(name_list[2], type(name_list[2]))
3print(name_list[-2::-2])
4
5执行结果为:|A <class 'str'>
6 |['啊', 'N', 'b']
7
8
2. index() 由数据查找索引
- 格式为:列表.index(要查询数据, start=开始下标, stop=结束下表)
- 检测要查询的数据是否包含在 列表的指定范围(开始下标和结束下标之间,不包含结束下标)
- 若在指定范围内,则
返回第一次查询到列表索引值,不在则报错
-
开始下标和结束下标可以省略,表示搜索全文,若填写一个下标表示从下标开始搜索直至结束,而不是从开始搜索至下标位置
2
3
4
5
6
2print(name_list.index("A", 1))
3
4执行结果为:|2
5
6
3. count() 由数据查找出现次数
格式为:列表.count(要查找数据)
- 检测要查询的数据是否包含在 列表中,若在指定范围内,则
返回出现的次数,不在则返回0
2
3
4
5
6
7
8
2print(name_list.count("a"))
3print(name_list.count("1"))
4
5执行结果为:|2
6 |0
7
8
4. len() 查字符串长度
格式为:len(要查找的列表)
-
检测要查询的列表的长度,返回int型
2
3
4
5
6
2print(len(name_list), type(len(name_list)))
3
4执行结果为:|7 <class 'int'>
5
6
增
1
.append()
将数据以一个整体追加到列表结尾
2
.expend()
将序列遍历式逐一追加到列表结尾
3
+=
将序列遍历式逐一追加到列表结尾,要求与效果以expend()完全一致
4
.insert()
将要追加的数据插入到指定位置
1.append():将数据以一个整体追加到列表结尾
- 格式为:列表.append(要追加的数据)
- 含义:将要追加的数据以一个整体追加到列表
末尾
- 如果
追加的数据是⼀个序列,则将整个序列追加到列表末尾
2
3
4
5
6
7
2name_list.append(['赵六', '钱七'])
3print(name_list)
4
5执行结果为:|['张三', '李四', '王五', ['赵六', '钱七']]
6
7
2.expend():将序列遍历式逐一追加到列表结尾
- 格式为:列表.append(要追加的序列)
- 含义:将要追加的序列遍历式逐一追加到列表
末尾
-
追加的数据必须是⼀个序列若不是序列会报错
2
3
4
5
6
7
2name_list.expend(['赵六', '钱七'])
3print(name_list)
4
5执行结果为:|['张三', '李四', '王五', '赵六', '钱七']
6
7
2. += :将序列遍历式逐一追加到列表结尾
- 格式为:列表+=要追加的序列
- 其与expend()方法要求和效果完全一致,也是在列表的原数据上进行遍历式追加列表结尾
- 含义:将要追加的序列遍历式逐一追加到列表
末尾
-
追加的数据必须是⼀个序列若不是序列会报错
2
3
4
5
6
7
2name_list.expend(['赵六', '钱七'])
3print(name_list)
4
5执行结果为:|['张三', '李四', '王五', '赵六', '钱七']
6
7
3.insert():将要追加的数据插入到指定位置
- 格式为:列表.insert(下标,要追加的数据)
- 含义:将要追加的数据以一个整体插入到列表
指定下标位置,原位置及之后的数据往后移
-
追加的数据必须是⼀个序列若不是序列会报错
2
3
4
5
6
7
2name_list.expend(1, ['赵六', '钱七'])
3print(name_list)
4
5执行结果为:|['张三', ['赵六', '钱七'], '李四', '王五']
6
7
删除
1
del或del ()
带下标删列表指定位置数据,不带下标删列表
2
.pop()
删除指定下标的数据(默认为最后⼀个),并返回删除的数据
3
.remove()
移除列表中某个数据的第⼀个匹配项
4
.clear()
清空列表所有数据,返回空列表
1. del 带下标删列表指定位置数据,不带下标删列表
分函数和关键字两种删除方式
1.关键字形式(常用)
- 格式为:del 列表[下标] 或 del 列表
前者为删除列表指定下标位置数据,后者为删除整个列表
2.函数形式
-
格式为:del(列表[下标]) 或 del(列表) 前者为删除列表指定下标位置数据,后者为删除整个列表
2
3
4
5
6
7
8
9
10
2del name_list[1] # del(name_list[1])
3print(name_list)
4del name_list # del(name_list)
5print(name_list)
6
7执行结果为:|['张三', '王五']
8 |NameError: name 'name_list' is not defined
9
10
2. pop():删除指定下标的数据(默认为最后⼀个),并返回删除的数据
- 格式为:变量 = 列表.pop(指定下标)
- 有返回值(删除掉的数据),需要有变量接受,否则得不到删掉的数据
- 若不指定下标,
默认删除最后一个数据
2
3
4
5
6
7
2name = name_list.pop(2)
3print(name)
4
5执行结果为:|王五
6
7
3.remove():移除列表中某个数据的第⼀个匹配项
- 格式为:列表.remove(指定数据)
- 删除列表中
指定数据的第一个匹配项
- 若不指定下标,
默认删除最后一个数据
2
3
4
5
6
7
8
9
10
2name_list.remove("王五")
3print(name_list)
4name_list.remove("wangwu")
5print(name_list)
6
7执行结果为:|['张三', '李四', '王五']
8 |ValueError: list.remove(x): x not in list
9
10
修改
1
列表[下标] = 值
修改指定下标数据,不修改内存地址
2
列表 = 值
表示重新赋值,修改内存地址
3
. reverse()
将列表中的数据逆置处理,即顺序颠倒
4
.sort()
将整个列表进行以升序或降序重新排列
1. 修改数据,不修改内存地址
根据列表索引进行索引所在位置值的重新赋值
-
格式为:列表[下标] = 值
2
3
4
5
6
7
8
9
2print(id(name_list), name_list)
3name_list[1] = "马六"
4print(id(name_list), name_list)
5
6执行结果为:|1873320599816 ['张三', "王五", '李四', '王五']
7 |1873320599816 ['张三', '马六', '李四', '王五']
8
9
2. 重新赋值,修改内存地址
对整个列表进行重新赋值
-
格式为:列表 = 值
2
3
4
5
6
7
8
9
2print(id(name_list), name_list)
3name_list = ["马六", "田七"]
4print(id(name_list), name_list)
5
6执行结果为: |1336607760648 ['张三', '王五', '李四', '王五']
7 |1336607760712 ['马六', '田七']
8
9
3. reverse() 将整个列表进行逆置,数据顺序颠倒
-
格式为:列表.reverse()
2
3
4
5
6
7
8
9
10
2name_list.sort()
3print(name_list)
4name_list.sort(reverse=True)
5print(name_list)
6
7执行结果为: |['12', '2', 'A', 'N', 'a', 'b', '啊']
8 |['啊', 'b', 'a', 'N', 'A', '2', '12']
9
10
4. sort() 将整个列表进行以升序或降序重新排列
- 格式为:列表.sort(reverse=False)
- 其中列表中的数据必须为
同类型数据,否则报错
- reverse为默认参数,
默认为False(升序),改为True表示降序排列
-
(“啊”>“A”>“a”>“1”)
2
3
4
5
6
7
2name_list.reverse()
3print(name_list)
4
5执行结果为: |['王五', '李四', '王五', '张三']
6
7
列表推导式
指的轻量级循环创建列表
-
格式为:变量名 = [ 要输出成列表的项 for 临时变量 in 序列 for嵌套 if判断]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2print([i for i in (1, 2, 3, 4)]) # for循环结合元组
3print([i+"!" for i in "hello word"]) # for循环结合字符串
4print(["@"+i for i in {"a", "b", "c"}]) # for循环结合集合
5print([i for i in {"name": "小明", "age": 12}.items()]) # for循环结合字典及其内置所有键值对函数
6print([i for i in range(2, 9) if i % 3 == 0]) # for循环结合if判断
7print([(i, j) for i in range(1, 4) for j in range(2, 4)]) # for嵌套结合range
8my_list = ({"name": "李四", "age": 20}, {"name": "王五", "age": 22})
9print([u for u in my_list if u["age"] > 20]) # for循环结合if判断和字典
10
11执行结果为: |[1, 2, 3, 4]
12 |[1, 2, 3, 4]
13 |['h!', 'e!', 'l!', 'l!', 'o!', ' !', 'w!', 'o!', 'r!', 'd!']
14 |['@b', '@c', '@a']
15 |[('name', '小明'), ('age', 12)]
16 |[3, 6]
17 |[(1, 2), (1, 3), (2, 2), (2, 3), (3, 2), (3, 3)]
18 |[{'name': '王五', 'age': 22}]
19
20
tuple 元组类型
- 格式为:变量名=(2, 2.2, True, "字符串", [列表], (元祖), {字典})
- 元组可以⼀次性存储多个不同数据,但为了方便循环遍历处理数据,一般放置相同类型的数据
- 凡是用一对小括号()引起来的内容皆称为元组,为不可变类型
- 若 括号中只有一个数据,数据类型为数据的数据类型,不一定为元组,若想要是元祖类型需要在数据后面加一个逗号
- 列表嵌套:变量名 = ((), (),()), 定义空元祖:变量名 = (),一个元素的元组:变量名 = (数据,)
元组的常⽤操作
元组为不可变类型,只能重新赋值不可修改,常将列表型数据转化为元组,从而进行数据保存。因此元组除了查询没有其他操作
注意:元组的第一层数据是不可修改的,但如果其中有可变类型,还是可以修改可变类型中的数据的。但一般定义元组就表示数据不可改,所以不要轻易修改元组中的可变类型
查询
1
列表[下标]
索引为根据一个下标,取出一个数据
1
列表[下标范围]
切片为根据一个下标范围,取出多个数据
2
.index()
由数据找索引 ,无则报错
3
.count()
由数据查出现次数
4
len()
由列表数据查字符串长度
5
max()
在同类型数据中查找到最大值 (“啊”>“A”>“a”>“1”)
5
min()
在同类型数据中查找到最小值
6
数据 in 元组
判断数据是否在元组中,在返回Ture
6
数据 not in 元组
判断数据是否在元组中,在返回False
1. 索引和切片
索引为根据一个下标,取出一个数据,并将以数据
原类型输出。
- 格式为:元组[下标]
- 下标若不小于元组长度,否则会报错(
下标越界)
- 下标可为负,表示从右往左数第几个
切片为根据一个下标范围,取出多个数据,并将其生成一个新元组输出。
- 格式为:元组[开始下标:结束下标:步长] ,步长表示选取间隔
- 其中下标和步长可正可负。 下标为负,表示从右往左数第几个;步长为负表示从右往左取值**。
- 切片规则:
包括开始下标数据,不包括结束下标数据并且
开始到结束的方向需要与步长的方向一致,否则取值为空
-
切片顺序:先取开始下标的数据作为第一个数据,然后再根据步长取其他值,而非根据开始下标加上步长后再取第一个数据。
-
省略开始下标表示从0开始取值,省略结束下标表示取到最后,省略步长时最后一个冒号也可省,表示从左到右依次取值。
2
3
4
5
6
7
8
2print(tuple1[2], type(tuple1[2]))
3print(tuple1[-2::-2])
4
5执行结果为:|A <class 'str'>
6 |['啊', 'N', 'b']
7
8
2. index() 由数据查找索引
- 格式为:元组.index(要查询数据, start=开始下标, end=结束下表)
- 检测要查询的数据是否包含在 元组的指定范围(开始下标和结束下标之间,不包含结束下标)
- 若在指定范围内,则
返回第一次查询到元组索引值,不在则报错
-
开始下标和结束下标可以省略,表示搜索全文,若填写一个下标表示从下标开始搜索直至结束,而不是从开始搜索至下标位置
2
3
4
5
6
2print(tuple1.index("A", 1))
3
4执行结果为:|2
5
6
3. count() 由数据查找出现次数
格式为:元组.count(要查找数据)
- 检测要查询的数据是否包含在 元组中,若在指定范围内,则
返回出现的次数,不在则返回0
2
3
4
5
6
7
8
2print(tuple1.count("a"))
3print(tuple1.count("1"))
4
5执行结果为:|2
6 |0
7
8
4. len() 查字符串长度
格式为:len(要查找的元组)
-
检测要查询的元组的长度,返回int型
2
3
4
5
6
2print(len(tuple1), type(len(tuple1)))
3
4执行结果为:|8 <class 'int'>
5
6
dict 字典类型
- 格式为:变量名 = {键1: 值1, 键2: 值2}
- 字典在python
3.6之前为无序的,在3.6以后方才改为有序字典
- 字典
以键值对的形式存储的数据,键是唯一的,若增加数据时键已存在,则会将原有的值覆盖。
- 因字典之前为无序的,因此
无法使用下表进行索引和切片,只能通过key对其索引
- 凡是用一对小括号{}引起来的
键值对形式数据皆称为字典,为可变类型
- 定义空字典:变量名 = {} 或 变量名 = dict()
- 字典一般是
储存描述性信息,增加代码的可读性。如:每个学生学号、姓名、年龄等信息
字典的常⽤操作
字典为可变类型,使用以下常用操作内存地址不会发生变化
获取数据
字典[键]
根据指定键获取对应值,若键不存在报错
获取数据
.get(键, 默认值)
根据指定键获取对应值,若键不存在,返回默认值
添加和修改元素
字典[键] = 值
键不存在为增加,存在为修改
删除
del或del ()
带下标删字典指定键数据,不带下标删字典
删除
.pop()
删除指定下标的数据(默认为最后⼀个),并返回删除的数据
清空
.clear()
清空字典所有数据,返回空列表
查长度
len()
测量字典中,键值对的个数
所有键
.keys()
返回一个包含字典所有键的列表
所有值
.values()
返回一个包含字典所有值的列表
所有键值对
items()
返回一个包含字典所有键值对的列表
获取数据
1.键索引
- 格式:字典[键]
- 索引存在的键,返回键值对中的值
- 索引存
不在的键,会发生异常
2.get()
- 在我们
不确定字典中是否存在某个键而又想获取其值时,可以使用get方法,还
可以设置默认值
- 格式:字典.get(键, 默认值)
- 索引
不存在的键,获取到空的内容,不会出现异常
- 索引
存在的键,无论是否有默认值,都返回
原字典中键值对中的值
- 索引
不存在的键,并且
有默认值,会
返回默认值
2
3
4
5
6
7
8
9
10
11
12
13
14
2print(info['name'])
3print(info.get('age', 20))
4print(info.get('sex'))
5print(info.get('sex', "男"))
6print(info['sex'])
7
8执行结果为:|周瑜
9 |18
10 |None
11 |男
12 |KeyError: 'sex'
13
14
添加和修改元素
- 格式:字典[键] = 值 添加后的格式键:值
- 当新增的
键不存在时,表示
增加数据(键值对)
- 当新增的
键存在是,则表示
修改原字典的相同键的值。(因为字典中的
键是唯一的)
2
3
4
5
6
7
8
2info["sex"] = "男" # 键"sex"原字典中不存在,为添加数据
3info["age"] = 22 # 键"age"原字典中存在,为添加数据
4print(info)
5
6执行结果为:|{'name': '周瑜', 'age': 22, 'sex': '男'}
7
8
update() 字典合并(更新字典)
-
格式:字典1.update(字典2)
-
将字典2中的键值对更新到字典1中(字典2中不重复键的键值对添加到字典1中,重复键的值更新到字典1中)
2
3
4
5
6
7
8
2info2 = {"sex": "男", 'age': 22}
3info1.update(info2)
4print(info)
5
6执行结果为:|{'name': '周瑜', 'age': 22, 'sex': '男'}
7
8
删除
1. del 带下标删字典指定键数据,不带下标删字典
分为函数和关键字两种删除方式
1.关键字形式(常用)
- 格式为:del 字典[键] 或 del 字典
前者为删除字典指定下标位置数据,后者为删除整个字典
2.函数形式
-
格式为:del(字典[键]) 或 del(字典) 前者为删除字典指定下标位置数据,后者为删除整个字典
2
3
4
5
6
7
8
9
10
2del name_dict["sex"] # del(name_dict["sex"])
3print(name_dict)
4del name_dict # del(name_dict), 删除后不能访问
5print(name_dict)
6
7执行结果为:|{'name': '小明', 'age': 20}
8 |NameError: name 'name_dict' is not defined
9
10
2. pop():删除指定下标的数据(默认为最后⼀个),并返回删除的数据
-
格式为:变量 = 字典.pop(指定键)
-
有返回值(指定键对应的值),需要有变量接受,否则得不到删掉的数据
-
必须指定一个存在的键,后则会报错
2
3
4
5
6
7
8
9
2deldata = name_dict.pop("sex")
3print(deldata)
4print(name_dict)
5
6执行结果为:|男
7 |{'name': '小明', 'age': 20}
8
9
set 集合数据
- 格式为:变量名 = {值1, 值2}
- 集合为
可变类型,但不可承载可变类型,其中只能承载数字型数据、字符串、元祖。
- 其中
数据不能重复,若其它类型(列表、元祖)转变时会
去重。
- 不能通过下标取值和切片
- 凡是用一对小括号{}引起来的非键值对数据皆称为集合
- 定义空集合:变量名 = set() 而非 变量名 = {}
- 一般用于列表数据的去重
字典的常⽤操作
字典为可变类型,使用以下常用操作内存地址不会发生变化
获取数据
字典[键]
根据指定键获取对应值,若键不存在报错
获取数据
.get(键, 默认值)
根据指定键获取对应值,若键不存在,返回默认值
添加和修改元素
字典[键] = 值
键不存在为增加,存在为修改
删除
del或del ()
带下标删字典指定键数据,不带下标删字典
删除
.pop()
删除指定下标的数据(默认为最后⼀个),并返回删除的数据
2
3
4
5
6
2print(list(set(list1)))
3
4执行结果为:|[1, 2, 3, 7]
5
6
数据类型转换
int(x)
将x转换为一个十进制整数
只含整数的字符串、float型(只留下整数部分,舍弃小数部分)和bool型
float(x)
将x转换为一个浮点数
只含数的字符串、float型和bool型
str(x)
将对象 x 转换为字符串
all
tuple(s)
将序列 s 转换为一个元组
str型(会将其按顺序展开)、list型、set型(无序去重记录)、dict型(按顺序记录键,不记录值)
list(s)
将序列 s 转换为一个列表
str型(会将其按顺序展开)、tuple型、set型(无序去重记录)、dict型(按顺序记录键,不记录值)
eval(str)
计算字符串中有效Python表达式
包含有效表达式的字符串, 返回值为一个对象
repr(x)
将对象 x 转换为表达式字符串
chr(x)
将整数x转换为Unicode字符
ord(x)
将字符x转换为它的ASCII整数值
hex(x)
将整数x转换为十六进制字符串
oct(x)
将整数x转换为八进制字符串
bin(x)
将整数x转换为二进制字符串
