Go 语言相比Java等一个很大的优势就是可以方便地编写并发程序。Go 语言内置了 goroutine 机制,使用goroutine可以快速地开发并发程序, 更好的利用多核处理器资源。这篇文章学习 goroutine 的应用及其调度实现。
一、Go语言对并发的支持
使用goroutine编程
使用 go 关键字用来创建 goroutine 。将go声明放到一个需调用的函数之前,在相同地址空间调用运行这个函数,这样该函数执行时便会作为一个独立的并发线程。这种线程在Go语言中称作goroutine。
goroutine的用法如下:
2
3
4
5
6
7
8
9
10
11
12
13
2 go GetThingDone(param1, param2)
3
4 //新建一个匿名方法并执行
5 go func(param1, param2) {
6
7 }(val1, val2)
8
9 //直接新建一个 goroutine 并在 goroutine 中执行代码块
10 go {
11 //do someting...
12 }
13
因为 goroutine 在多核 cpu 环境下是并行的。如果代码块在多个 goroutine 中执行,我们就实现了代码并行。
如果需要了解程序的执行情况,怎么拿到并行的结果呢?需要配合使用channel进行。
使用Channel控制并发
Channels用来同步并发执行的函数并提供它们某种传值交流的机制。
通过channel传递的元素类型、容器(或缓冲区)和传递的方向由“<-”操作符指定。
可以使用内置函数 make分配一个channel:
2
3
4
5
6
2 s := make(chan string, 3) // non-zero capacity
3
4 r := make(<-chan bool) // can only read from
5 w := make(chan<- []os.FileInfo) // can only write to
6
配置runtime.GOMAXPROCS
使用下面的代码可以显式的设置是否使用多核来执行并发任务:
2
2
GOMAXPROCS的数目根据任务量分配就可以,但是不要大于cpu核数。
配置并行执行比较适合适合于CPU密集型、并行度比较高的情景,如果是IO密集型使用多核的化会增加cpu切换带来的性能损失。
了解了Go语言的并发机制,接下来看一下goroutine 机制的具体实现。
二、区别并行与并发
进程、线程与处理器
在现代操作系统中,线程是处理器调度和分配的基本单位,进程则作为资源拥有的基本单位。每个进程是由私有的虚拟地址空间、代码、数据和其它各种系统资源组成。线程是进程内部的一个执行单元。 每一个进程至少有一个主执行线程,它无需由用户去主动创建,是由系统自动创建的。 用户根据需要在应用程序中创建其它线程,多个线程并发地运行于同一个进程中。
并行与并发
并行与并发(Concurrency and Parallelism)是两个不同的概念,理解它们对于理解多线程模型非常重要。
在描述程序的并发或者并行时,应该说明从进程或者线程的角度出发。
-
并发:一个时间段内有很多的线程或进程在执行,但何时间点上都只有一个在执行,多个线程或进程争抢时间片轮流执行
-
并行:一个时间段和时间点上都有多个线程或进程在执行
非并发的程序只有一个垂直的控制逻辑,在任何时刻,程序只会处在这个控制逻辑的某个位置,也就是顺序执行。如果一个程序在某一时刻被多个CPU流水线同时进行处理,那么我们就说这个程序是以并行的形式在运行。
并行需要硬件支持,单核处理器只能是并发,多核处理器才能做到并行执行。
-
并发是并行的必要条件,如果一个程序本身就不是并发的,也就是只有一个逻辑执行顺序,那么我们不可能让其被并行处理。
-
并发不是并行的充分条件,一个并发的程序,如果只被一个CPU进行处理(通过分时),那么它就不是并行的。
举一个例子,编写一个最简单的顺序结构程序输出"Hello World",它就是非并发的,如果在程序中增加多线程,每个线程打印一个"Hello World",那么这个程序就是并发的。如果运行时只给这个程序分配单个CPU,这个并发程序还不是并行的,需要部署在多核处理器上,才能实现程序的并行。
三、几种不同的多线程模型
用户线程与内核级线程
线程的实现可以分为两类:用户级线程(User-LevelThread, ULT)和内核级线程(Kemel-LevelThread, KLT)。用户线程由用户代码支持,内核线程由操作系统内核支持。
多线程模型
多线程模型即用户级线程和内核级线程的不同连接方式。
(1)多对一模型(M : 1)
将多个用户级线程映射到一个内核级线程,线程管理在用户空间完成。 此模式中,用户级线程对操作系统不可见(即透明)。
优点: 这种模型的好处是线程上下文切换都发生在用户空间,避免的模态切换(mode switch),从而对于性能有积极的影响。
缺点:所有的线程基于一个内核调度实体即内核线程,这意味着只有一个处理器可以被利用,在多处理器环境下这是不能够被接受的,本质上,用户线程只解决了并发问题,但是没有解决并行问题。如果线程因为 I/O 操作陷入了内核态,内核态线程阻塞等待 I/O 数据,则所有的线程都将会被阻塞,用户空间也可以使用非阻塞而 I/O,但是不能避免性能及复杂度问题。
(2) 一对一模型(1:1)
将每个用户级线程映射到一个内核级线程。
每个线程由内核调度器独立的调度,所以如果一个线程阻塞则不影响其他的线程。
优点:在多核处理器的硬件的支持下,内核空间线程模型支持了真正的并行,当一个线程被阻塞后,允许另一个线程继续执行,所以并发能力较强。
缺点:每创建一个用户级线程都需要创建一个内核级线程与其对应,这样创建线程的开销比较大,会影响到应用程序的性能。
(3)多对多模型(M : N)
内核线程和用户线程的数量比为 M : N,内核用户空间综合了前两种的优点。
这种模型需要内核线程调度器和用户空间线程调度器相互操作,本质上是多个线程被绑定到了多个内核线程上,这使得大部分的线程上下文切换都发生在用户空间,而多个内核线程又可以充分利用处理器资源。
四、goroutine机制的调度实现
goroutine机制实现了M : N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置的调度器,可以让多核CPU中每个CPU执行一个协程。
理解goroutine机制的原理,关键是理解Go语言scheduler的实现。
调度器是如何工作的
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched, 前三个定义在runtime.h中,Sched定义在proc.c中。
-
Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
-
M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
-
P结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分。
-
G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
Processor的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有GOMAXPROCS个线程在运行go代码。
参考这篇传播很广的博客:http://morsmachine.dk/go-scheduler
我们分别用三角形,矩形和圆形表示Machine Processor和Goroutine。
在单核处理器的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。 多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。
在正常情况下,scheduler会按照上面的流程进行调度,但是线程会发生阻塞等情况,看一下goroutine对线程阻塞等的处理。
线程阻塞
当正在运行的goroutine阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M线程放弃了它的Processor,P转到新的线程中去运行。
runqueue执行完成
当其中一个Processor的runqueue为空,没有goroutine可以调度。它会从另外一个上下文偷取一半的goroutine。
五、对并发实现的进一步思考
Go语言的并发机制还有很多值得探讨的,比如Go语言和Scala并发实现的不同,Golang CSP 和Actor模型的对比等。
了解并发机制的这些实现,可以帮助我们更好的进行并发程序的开发,实现性能的最优化。
关于三种多线程模型,可以关注一下Java语言的实现。
我们知道Java通过JVM封装了底层操作系统的差异,而不同的操作系统可能使用不同的线程模型,例如Linux和windows可能使用了一对一模型,solaris和unix某些版本可能使用多对多模型。JVM规范里没有规定多线程模型的具体实现,1:1(内核线程)、N:1(用户态线程)、M:N(混合)模型的任何一种都可以。谈到Java语言的多线程模型,需要针对具体JVM实现,比如Oracle/Sun的HotSpot VM,默认使用1:1线程模型。
参考链接
http://www.infoq.com/cn/articles/knowledge-behind-goroutine
http://jolestar.com/parallel-programming-model-thread-goroutine-actor/
其他说明:
Go线程实现模型MPG
M指的是Machine,一个M直接关联了一个内核线程。
P指的是”processor”,代表了M所需的上下文环境,也是处理用户级代码逻辑的处理器。
G指的是Goroutine,其实本质上也是一种轻量级的线程。
三者关系如下图所示:
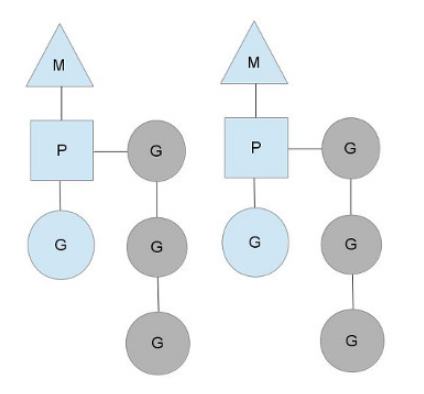
以上这个图讲的是两个线程(内核线程)的情况。一个M会对应一个内核线程,一个M也会连接一个上下文P,一个上下文P相当于一个“处理器”,一个上下文连接一个或者多个Goroutine。P(Processor)的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数runtime.GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有固定数量的线程在运行go代码。Goroutine中就是我们要执行并发的代码。图中P正在执行的Goroutine为蓝色的;处于待执行状态的Goroutine为灰色的,灰色的Goroutine形成了一个队列runqueues
三者关系的宏观的图为:

抛弃P(Processor)
你可能会想,为什么一定需要一个上下文,我们能不能直接除去上下文,让Goroutine的runqueues挂到M上呢?答案是不行,需要上下文的目的,是让我们可以直接放开其他线程,当遇到内核线程阻塞的时候。
一个很简单的例子就是系统调用sysall,一个线程肯定不能同时执行代码和系统调用被阻塞,这个时候,此线程M需要放弃当前的上下文环境P,以便可以让其他的Goroutine被调度执行。
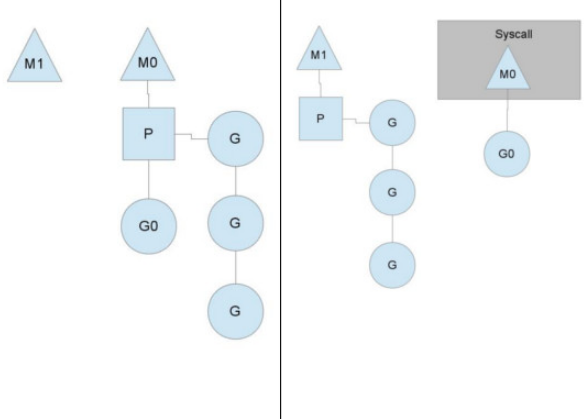
如上图左图所示,M0中的G0执行了syscall,然后就创建了一个M1(也有可能本身就存在,没创建),(转向右图)然后M0丢弃了P,等待syscall的返回值,M1接受了P,将·继续执行Goroutine队列中的其他Goroutine。
当系统调用syscall结束后,M0会“偷”一个上下文,如果不成功,M0就把它的Gouroutine G0放到一个全局的runqueue中,然后自己放到线程池或者转入休眠状态。全局runqueue是各个P在运行完自己的本地的Goroutine runqueue后用来拉取新goroutine的地方。P也会周期性的检查这个全局runqueue上的goroutine,否则,全局runqueue上的goroutines可能得不到执行而饿死。
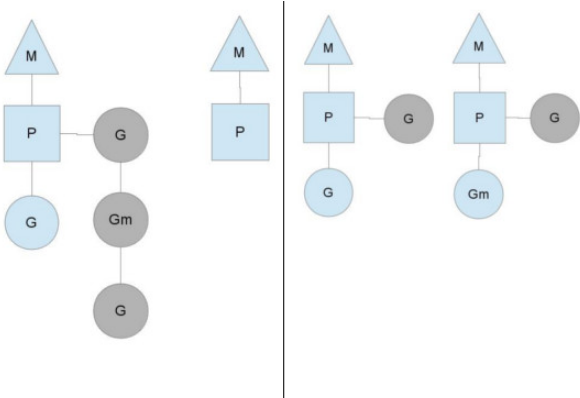
均衡的分配工作
按照以上的说法,上下文P会定期的检查全局的goroutine 队列中的goroutine,以便自己在消费掉自身Goroutine队列的时候有事可做。假如全局goroutine队列中的goroutine也没了呢?就从其他运行的中的P的runqueue里偷。
每个P中的Goroutine不同导致他们运行的效率和时间也不同,在一个有很多P和M的环境中,不能让一个P跑完自身的Goroutine就没事可做了,因为或许其他的P有很长的goroutine队列要跑,得需要均衡。
该如何解决呢?
Go的做法倒也直接,从其他P中偷一半!
1、用户级线程
把整个线程实现部分放在用户空间中,内核对线程一无所知,内核看到的就是一个单线程进程。只有一个用户栈
优点:
1)整个用户级线程的切换发生在用户空间,这样的线程切换至少比陷入内核要快一个数量级(不需要陷入内核、不需要上下文切换、不需要对内存高速缓存进行刷新,这就使得线程调度非常快捷)
2)用户级线程有比较好的可扩展性,线程能够利用的表空间和堆栈空间比内核级线程多,这是因为在内核空间中内核线程需要一些固定的表格空间和堆栈空间,如果内核线程的数量非常大,就会出现问题。
3)可以在不支持线程的操作系统中实现。
4)创建和销毁线程、线程切换代价等线程管理的代价比内核线程少得多, 因为保存线程状态的过程和调用程序都只是本地过程
5)允许每个进程定制自己的调度算法,线程管理比较灵活。这就是必须自己写管理程序,与内核线程的区别
6)线程的调度不需要内核直接参与,控制简单。
缺点:
1)一个线程阻塞,会阻塞该进程中其他所有的线程(具体,举个例子)
比如:线程发生I/O或页面故障引起的阻塞时,如果调用阻塞系统调用则内核由于不知道有多线程的存在,而会阻塞整个进程从而阻塞所有线程
页面失效也会产生类似的问题。
2)如果一个线程开始运行,那么该进程中其他线程就不能运行,除非第一个线程自动放弃CPU。因为在一个单独的进程内部,没有时钟中断,所以不能用轮转调度(轮流)的方式调度线程
2、核心级线程
在内核中有一个用来记录系统中所有线程的线程表(TCB,进程表PCB),当某个线程希望创建一个新线程或撤销一个已有线程时,它进行一个系统调用,这个系统调用通过对线程表的更新完成线程的创建或撤销工作。
一个用户栈,一个内核栈,分别保存在用户空间和内核空间,TCB切换发生在内核空间,TCB切换会造成这两个栈的切换
优点:
1)当一个线程阻塞时,内核根据选择,可以运行同一个进程或其他进程
缺点:
1)在内核中创建和撤销线程的开销比较大,速度慢
3、用户级、核心级线程相结合:
在一些系统中,使用组合方式的多线程实现, 线程创建完全在用户空间中完成,线程的调度和同步也在应用程序中进行. 一个应用程序中的多个用户级线程被映射到一些(小于或等于用户级线程的数目)内核级线程上。
下图说明了用户级与内核级的组合实现方式, 在这种模型中,每个内核级线程有一个可以轮流使用的用户级线程集合
平时我们使用的pthread线程库就是一个组合方式的多线程
4、用户级、核心级线程优缺点、区别:
1)内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
2)用户级线程的创建、撤消和调度不需要OS内核的支持,是在语言(如Java)这一级处理的;而内核支持线程的创建、撤消和调度都需OS内核提供支持,而且与进程的创建、撤消和调度大体是相同的。
3)用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
4)在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行;在有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
5) 用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
5、当一个多线程进程创建新的进程时面临的问题:
1)子进程是否继承所有的线程;
2)信号是发给进程而不是线程的,那么当一个信号到达时,由那个线程来处理,线程可以“注册”它们感兴趣的信号
参考书籍:《现代操作系统》
