1.序篇-本文结构
1 | protobuf |
作为目前各大公司中最广泛使用的高效的协议数据交换格式工具库,会大量作为流式数据传输的序列化方式,所以在 flink sql 中如果能实现
1 | protobuf |
的
1 | format |
会非常有用(目前社区已经有对应的实现,不过目前还没有 merge,预计在 1.14 系列版本中能 release)。
1 | issue |
1 | pr |
见:https://github.com/apache/flink/pull/14376
这一节主要介绍 flink sql 中怎么自定义实现
1 | format |
,其中以最常使用的
1 | protobuf |
作为案例来介绍。
- 背景篇-为啥需要 protobuf format
- 目标篇-protobuf format 预期效果
- 难点剖析篇-此框架建设的难点、目前有哪些实现
- 维表实现篇-实现的过程
- 总结与展望篇
如果想在本地直接测试下:
- 在公众号后台回复
- flink sql 知其所以然(五)| 自定义 protobuf format获取源码(源码基于 1.13.1 实现)
- flink sql 知其所以然(五)| 自定义 protobuf format获取源码(源码基于 1.13.1 实现)
- flink sql 知其所以然(五)| 自定义 protobuf format获取源码(源码基于 1.13.1 实现)
- 执行源码包中的
1flink.examples.sql._05.format.formats.SocketWriteTest
测试类来制造 protobuf 数据
- 然后执行源码包中的
1flink.examples.sql._05.format.formats.ProtobufFormatTest
测试类来消费 protobuf 数据,并且打印在 console 中,然后就可以在 console 中看到结果。
2.背景篇-为啥需要 protobuf format
关于为什么选择
1 | protobuf |
可以看这篇文章,写的很详细:
http://hengyunabc.github.io/thinking-about-grpc-protobuf/?utm_source=tuicool&utm_medium=referral
在实时计算的领域中,为了可读性会选择
1 | json |
,为了效率以及一些已经依赖了
1 | grpc |
的公司会选择
1 | protobuf |
来做数据序列化,那么自然而然,日志的序列化方式也会选择
1 | protobuf |
。
而官方目前已经 release 的版本中是没有提供 flink sql api 的
1 | protobuf format |
的。如下图,基于 1.13 版本。
https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/connectors/table/overview/
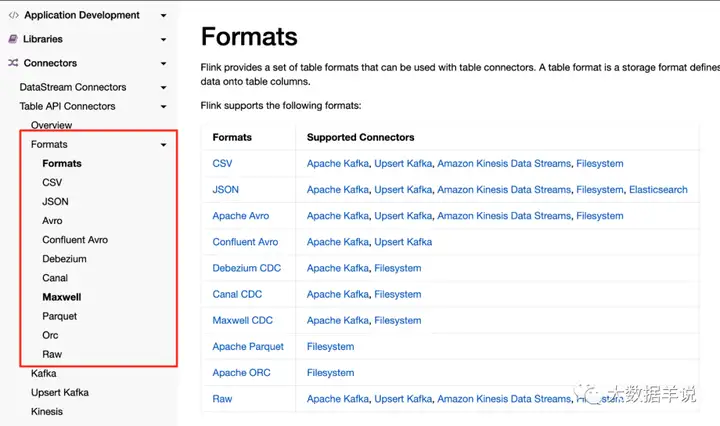
1
因此本文在介绍怎样自定义一个 format 的同时,实现一个 protobuf format 来给大家使用。
3.目标篇-protobuf format 预期效果
预期效果是先实现几种最基本的数据类型,包括 protobuf 中的
1 | message |
(自定义 model)、
1 | map |
(映射)、
1 | repeated |
(列表)、其他基本数据类型等,这些都是我们最常使用的类型。
预期 protobuf message 定义如下:
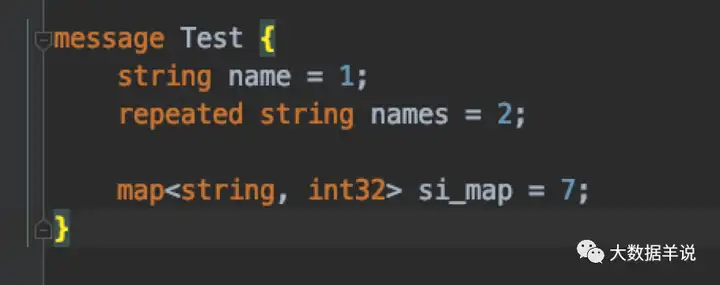
2
测试数据源数据如下,博主把 protobuf 的数据转换为 json,以方便展示,如下图:
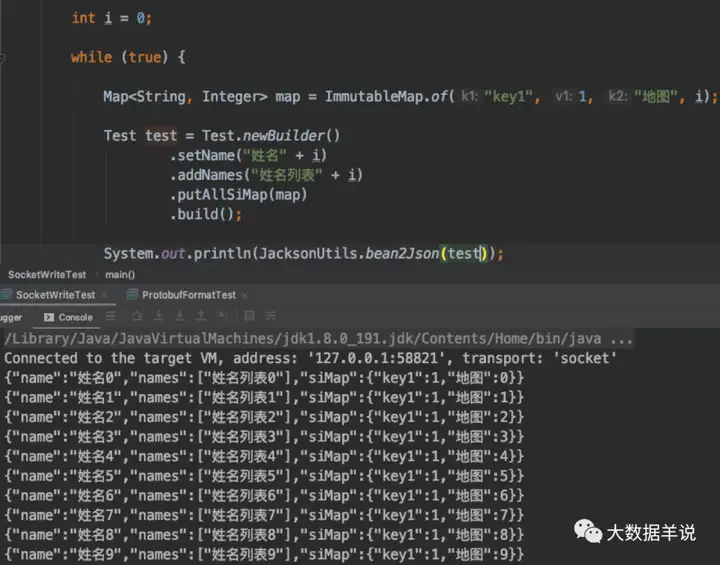
3
预期 flink sql:
数据源表 DDL:
2
3
4
5
6
7
8
9
10
11
12
name STRING
, names ARRAY<STRING>
, si_map MAP<STRING, INT>
)
WITH (
'connector' = 'socket',
'hostname' = 'localhost',
'port' = '9999',
'format' = 'protobuf',
'protobuf.class-name' = 'flink.examples.sql._04.format.formats.protobuf.Test'
)
数据汇表 DDL:
2
3
4
5
6
7
name STRING
, names ARRAY<STRING>
, si_map MAP<STRING, INT>
) WITH (
'connector' = 'print'
)
Transform 执行逻辑:
2
3
SELECT *
FROM protobuf_source
下面是我在本地跑的结果:
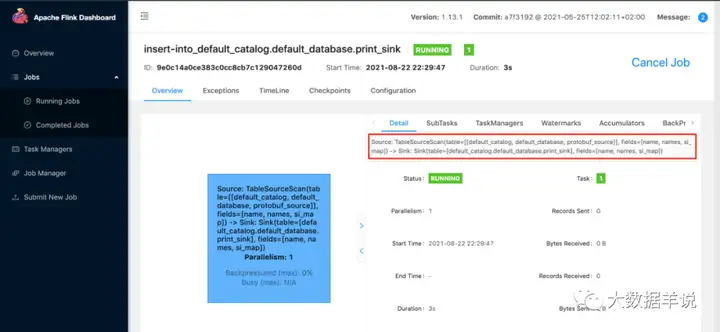
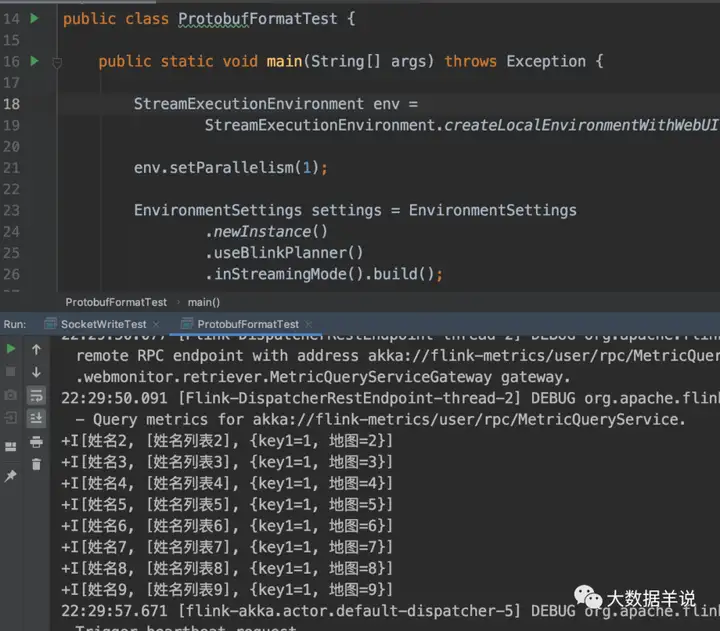
可以看到打印的结果,数据是正确的被反序列化读入,并且最终输出到 console。
4.难点剖析篇-目前有哪些实现
目前业界可以参考的实现如下:https://github.com/maosuhan/flink-pb, 也就是这位哥们负责目前 flink protobuf 的 format。
这种实现的具体使用方式如下:
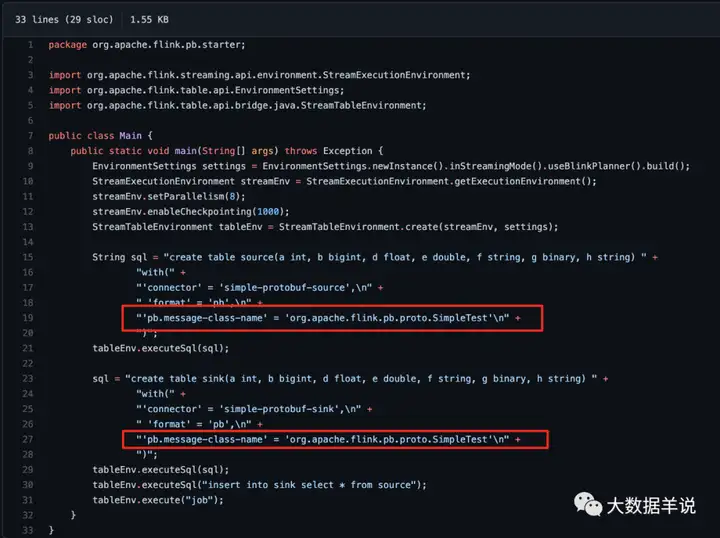
7
其实现有几个特点:
- 复杂性:用户需要在 flink sql 程序运行时,将对应的 protobuf java 文件引入 classpath,这个特点是复合 flink 这样的通用框架的特点的。但是如果需要在各个公司场景要做一个流式处理平台的场景下,各个 protobuf sdk 可能都位于不同的 jar 包中,那么其 jar 包管理可能是一个比较大的问题。
- 高效 serde:一般很多场景下为了通用化 serde protobuf message,可能会选择 DynamicMessage 来处理 protobuf message,但是其 serde 性能相比原生 java code 的性能比较差。因为特点 1 引入了 protobuf 的 java class,所以其 serde function 可以基于 codegen 实现,而这将极大提高 serde 效率,效率提高就代表着省钱啊,可以吹逼的。
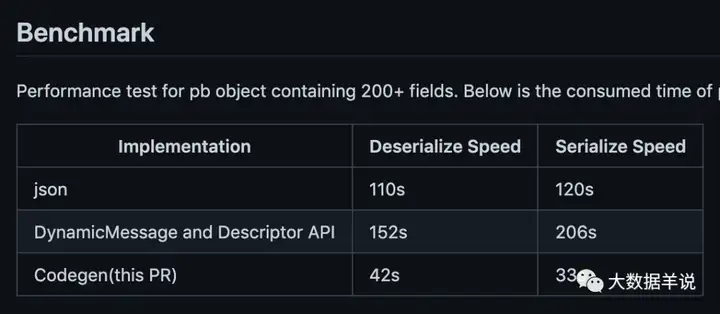
8
Notes:
当然博主针对第一点也有一些想法,比如怎样做到不依赖 protobuf java 文件,只依赖 protobuf 的 message 定义即可或者只依赖其 descriptor。目前博主的想法如下:
- flink 程序在客户端获取到对应的 protobuf message 定义
- 然后根据这个定义恢复出 proto 文件
- 客户端本地执行 protoc 将此文件编译为 java 文件
- 客户端本地动态将此 java 文件编译并 load 到 jvm 中
- 使用 codegen 然后动态生成执行代码
一气呵成!!!
具体实现其实可以参考:https://stackoverflow.com/questions/28381659/how-to-compile-protocol-buffers-schema-at-runtime
5.实现篇-实现的过程
5.1.flink format 工作原理
其实上节已经详细描述了 flink sql 对于 source\sink\format 的加载机制。
- 通过 SPI 机制加载所有的 source\sink\format 工厂
1Factory
- 过滤出 DeserializationFormatFactory\SerializationFormatFactory + format 标识的 format 工厂类
- 通过 format 工厂类创建出对应的 format
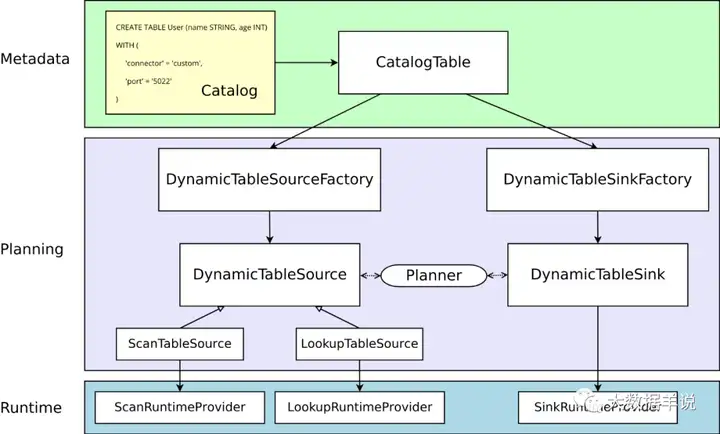
12
flink sql 知其所以然(一)| source\sink 原理

11
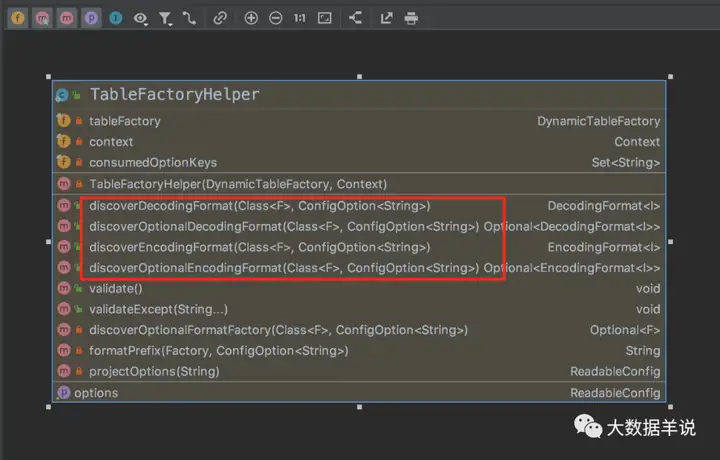
如图 serde format 是通过
1 | TableFactoryHelper.discoverDecodingFormat |
和
1 | TableFactoryHelper.discoverEncodingFormat |
创建的
2
3
4
5
6
7
8
// or use the provided helper utility
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// discover a suitable decoding format
final DecodingFormat<DeserializationSchema<RowData>> decodingFormat = helper.discoverDecodingFormat(
DeserializationFormatFactory.class,
FactoryUtil.FORMAT);
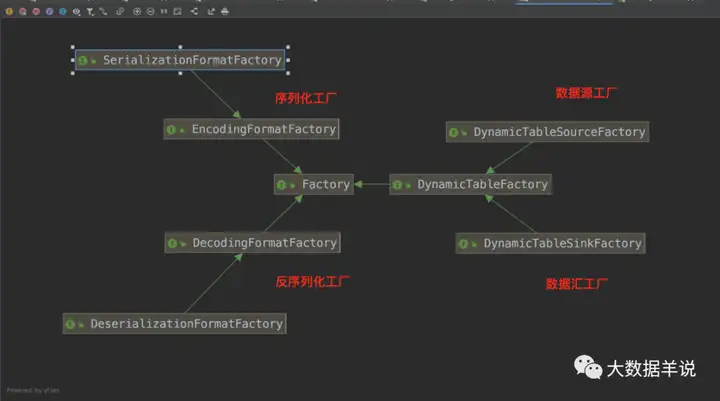
16
所有通过 SPI 的 source\sink\formt 插件都继承自
1 | Factory |
。
整体创建 format 方法的调用链如下图。
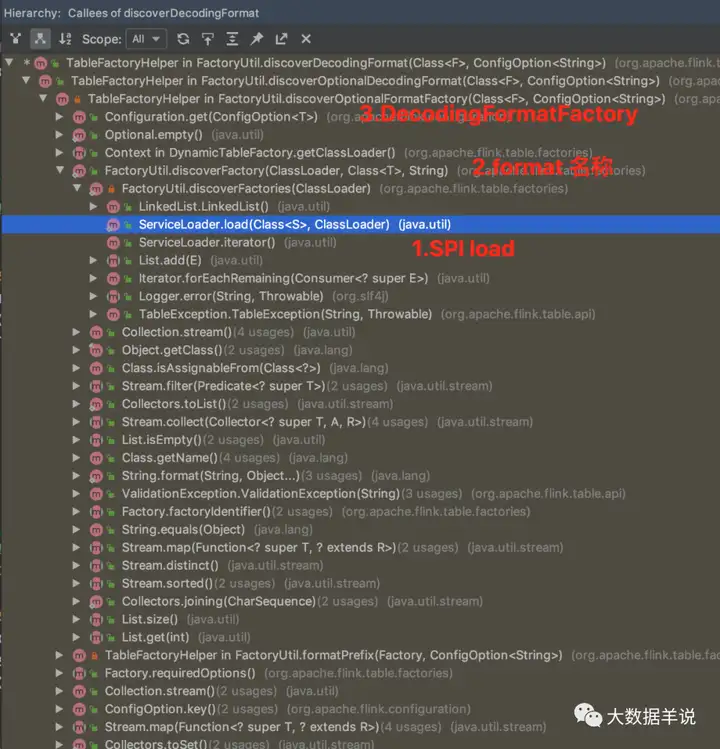
13
5.2.flink protobuf format 实现
最终实现如下,涉及到了几个实现类:
-
1ProtobufFormatFactory
-
1ProtobufOptions
-
1ProtobufRowDataDeserializationSchema
-
1ProtobufToRowDataConverters
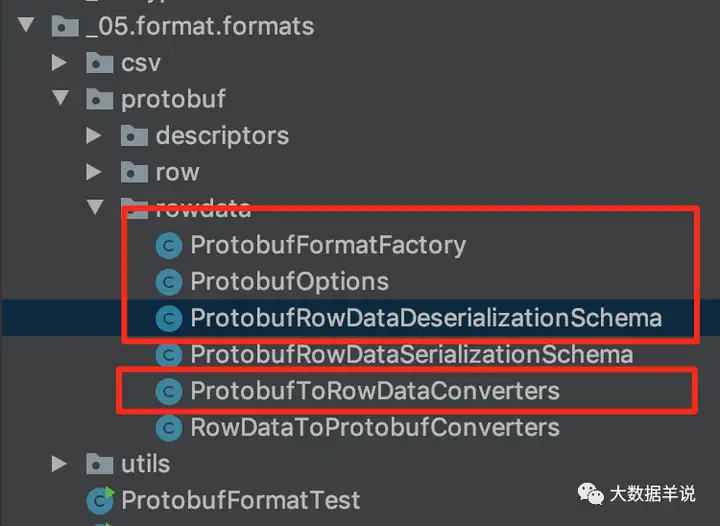
14
具体流程:
- 定义 SPI 的工厂类
1ProtobufFormatFactory implements DeserializationFormatFactory
,并且在 resource\META-INF 下创建 SPI 的插件文件
- 实现
1ProtobufFormatFactory#factoryIdentifier
标识
1protobuf - 实现
1ProtobufFormatFactory#createDecodingFormat
来创建对应的
1DecodingFormat<DeserializationSchema<RowData>>,
1DecodingFormat是用来封装具体的反序列化器的,实现
1DecodingFormat<DeserializationSchema<RowData>>#createRuntimeDecoder,返回
1ProtobufRowDataDeserializationSchema - 定义
1ProtobufRowDataDeserializationSchema implements DeserializationSchema<RowData>
,这个就是具体的反序列化器,其实与 datastream api 相同
- 实现
1ProtobufRowDataDeserializationSchema#deserialize
方法,与 datastream 相同,这个方法就是将
1byte[]序列化为
1RowData的具体逻辑
- 注意这里还实现了一个类
1ProtobufToRowDataConverters
,其作用就是在客户端创建出具体的将
1byte[]序列化为
1RowData的具体工具类,其会根据用户定义的表字段类型动态生成数据转换的 converter 类(策略模式:https://www.runoob.com/design-pattern/strategy-pattern.html),相当于表的 schema 确定之后,其 converter 也会确定
上述实现类的具体关系如下:
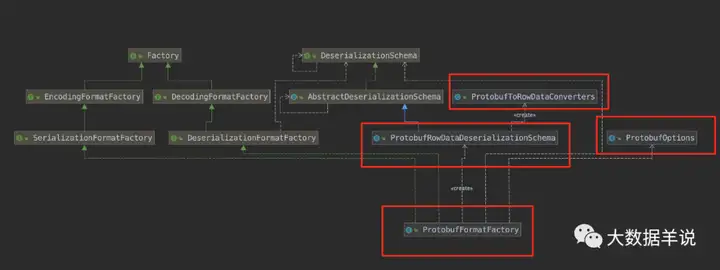
19
介绍完流程,进入具体实现方案细节:
1 | ProtobufFormatFactory |
主要创建 format 的逻辑:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
public static final String IDENTIFIER = "protobuf";
@Override
public DecodingFormat<DeserializationSchema<RowData>> createDecodingFormat(Context context,
ReadableConfig formatOptions) {
FactoryUtil.validateFactoryOptions(this, formatOptions);
// 1.获取到 protobuf 的 class 全路径
final String className = formatOptions.get(PROTOBUF_CLASS_NAME);
try {
// 2.load class
Class<GeneratedMessageV3> protobufV3 =
(Class<GeneratedMessageV3>) this.getClass().getClassLoader().loadClass(className);
// 3.创建 DecodingFormat
return new DecodingFormat<DeserializationSchema<RowData>>() {
@Override
public DeserializationSchema<RowData> createRuntimeDecoder(DynamicTableSource.Context context,
DataType physicalDataType) {
// 4.获取到 table schema rowtype
final RowType rowType = (RowType) physicalDataType.getLogicalType();
// 5.创建对应的 DeserializationSchema 作为反序列化器
return new ProtobufRowDataDeserializationSchema(
protobufV3
, true
, rowType);
}
@Override
public ChangelogMode getChangelogMode() {
return ChangelogMode.insertOnly();
}
};
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
@Override
public String factoryIdentifier() {
return IDENTIFIER;
}
...
}
resources\META-INF 文件:
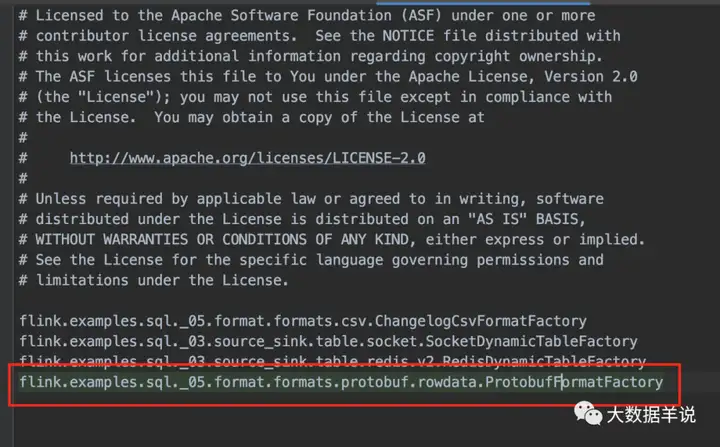
17
1 | ProtobufRowDataDeserializationSchema |
主要实现反序列化的逻辑:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
...
private ProtobufToRowDataConverters.ProtobufToRowDataConverter runtimeConverter;
public ProtobufRowDataDeserializationSchema(
Class<? extends GeneratedMessageV3> messageClazz
, boolean ignoreParseErrors
, RowType expectedResultType) {
this.ignoreParseErrors = ignoreParseErrors;
Preconditions.checkNotNull(messageClazz, "Protobuf message class must not be null.");
this.messageClazz = messageClazz;
this.descriptorBytes = null;
this.descriptor = ProtobufUtils.getDescriptor(messageClazz);
this.defaultInstance = ProtobufUtils.getDefaultInstance(messageClazz);
// protobuf 本身的 schema
this.protobufOriginalRowType = (RowType) ProtobufSchemaConverter.convertToRowDataTypeInfo(messageClazz);
this.expectedResultType = expectedResultType;
// 1.根据 table schema 动态创建出对应的反序列化器
this.runtimeConverter = new ProtobufToRowDataConverters(false)
.createRowDataConverterByLogicalType(this.descriptor, this.expectedResultType);
}
@Override
public RowData deserialize(byte[] bytes) throws IOException {
if (bytes == null) {
return null;
}
try {
// 2.将 bytes 反序列化为 protobuf message
Message message = this.defaultInstance
.newBuilderForType()
.mergeFrom(bytes)
.build();
// 3.反序列化逻辑,从 protobuf message 中获取字段转换为 RowData
return (RowData) runtimeConverter.convert(message);
} catch (Throwable t) {
if (ignoreParseErrors) {
return null;
}
throw new IOException(
format("Failed to deserialize Protobuf '%s'.", new String(bytes)), t);
}
}
...
可以注意到上述反序列化的主要逻辑就集中在
1 | runtimeConverter |
上,即
1 | ProtobufToRowDataConverters.ProtobufToRowDataConverter |
。
1 | ProtobufToRowDataConverters.ProtobufToRowDataConverter |
就是在
1 | ProtobufToRowDataConverters |
中定义的。
1 | ProtobufToRowDataConverters.ProtobufToRowDataConverter |
其实就是一个 convertor 接口:
2
3
4
public interface ProtobufToRowDataConverter extends Serializable {
Object convert(Object object);
}
其作用就是将 protobuf message 中的每一个字段转换成为
1 | RowData |
中的每一个字段。
1 | ProtobufToRowDataConverters |
中就定义了具体转换逻辑,如截图所示,每一个 LogicalType 都定义了 protobuf message 字段转换为 flink 数据类型的逻辑:
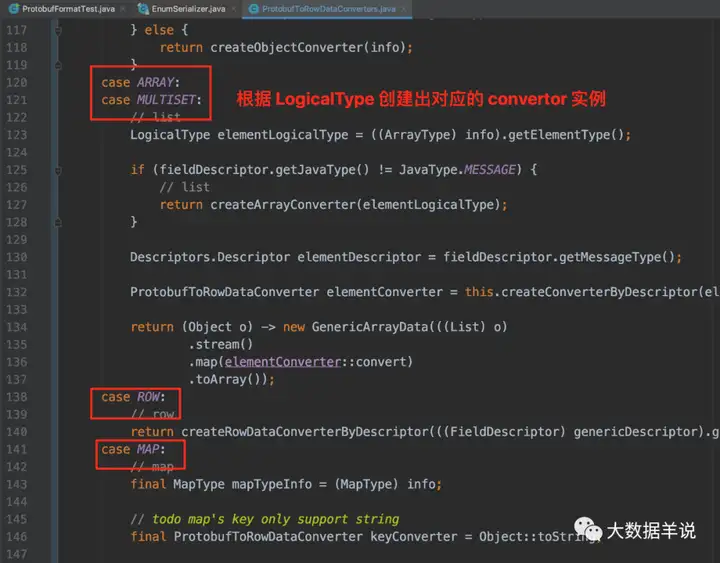
18
源码公众号后台回复flink sql 知其所以然(五)| 自定义 protobuf format获取。
6.总结与展望篇
6.1.总结
本文主要是针对 flink sql protobuf format 进行了原理解释以及对应的实现。如果你正好需要这么一个 format,直接公众号后台回复flink sql 知其所以然(五)| 自定义 protobuf format获取源码吧。
6.2.展望
当然上述只是 protobuf format 一个基础的实现,用于生产环境还有很多方面可以去扩展的。
- 性能优化、通用化:protobuf java class 本地 codegen 来提高任务性能
- 数据质量:异常 AOP,alert 等
