Linux Shell 编程
-
1.为什么要学习 Shell 编程
-
2.Shell 是什么
-
3.快速入门shell 脚本
-
3.1 什么是脚本
- 3.2 脚本格式要求
- 3.3 脚本的常用执行方式
- 3.4 shell脚本的内存环境
-
4.shell 的变量
-
4.1 Shell 的变量的介绍
- 4.2 shell 变量的定义
-
4.2.1 基本语法
* 4.2.3 定义变量的规则
* 4.2.4 *将命令的返回值赋给变量
* 4.2.5 单引号与双引号的区别 -
5.设置环境变量
-
5.1 基本语法
- 5.2 自定义环境变量
-
6.位置参数变量
-
6.1 介绍
- 6.2 基本语法
- 6.3 位置参数变量应用实例
-
7.预定义变量
-
7.1 基本介绍
- 7.2 基本语法
- 7.3 应用实例
-
8.运算符
-
9.条件判断
-
9.1 基本语法
- 9.3 常用判断条件
- 9.4 应用实例
-
10.流程控制
-
10.1 if 判断
- 10.2 case 语句
- 10.3 for 循环
-
比较$*和$@区别
* for 循环体中使用cat- 10.4 while 循环
-
11.read 读取控制台输入
-
12.函数
-
12.1 系统函数
- 12.2 自定义函数
-
13.Shell 编程综合案例
1.为什么要学习 Shell 编程
1)Linux 运维工程师在进行服务器集群管理时, 需要编写 Shell 程序来进行服务器管理。
2)对于 JavaEE 和 Python 程序员来说, 工作的需要, 你的老大会要求你编写一些 Shell 脚本进行程序或者是服务器的维护, 比如编写一个定时备份数据库的脚本。
3)对于大数据程序员来说, 需要编写 Shell 程序来管理集群。
2.Shell 是什么
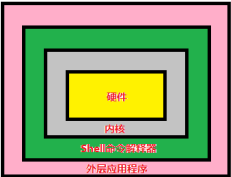
Shell 是一个命令行解释器,它为用户提供了一个向 Linux 内核发送请求以便运行程序的界面系统级程序, 用户可以用 Shell 来启动、 挂起、 停止甚至是编写一些程序.
Linux 中的 Shell 有很多类型,其中最常用的几种是:
- Bourne shell (sh)
- C shell (csh)
- Korn shell (ksh)
1)Bourne shell: 是 UNIX 最初使用的 shell,并且在每种 UNIX 上都可以使用, 在 shell 编程方面相当优秀,但在处理与用户的交互方面做得不如其他几种shell。
2)Bourne Again shell:Linux 操作系统缺省的 shell 是Bourne Again shell,它是 Bourne shell 的扩展,简称 Bash,与 Bourne shell 完全向后兼容,并且在Bourne shell 的基础上增加、增强了很多特性。Bash放在/bin/bash中,它有许多特色,可以提供如命令补全、命令编辑和命令历史表等功能,它还包含了很多 C shell 和 Korn shell 中的优点,有灵活和强大的编程接口,同时又有很友好的用户界面。
Linux提供的Shell解析器有:
2
3
4
5
6
7
8
9
2/bin/sh
3/bin/bash
4/sbin/nologin
5/bin/dash
6/bin/tcsh
7/bin/csh
8
9
bash和sh的关系:
2
3
4
5
2-rwxr-xr-x. 1 root root 941880 5月 11 2016 bash
3lrwxrwxrwx. 1 root root 4 5月 27 2017 sh -> bash
4
5
Centos默认的解析器是bash:
2
3
4
2/bin/bash
3
4
3.快速入门shell 脚本
3.1 什么是脚本
脚本是针对于解释型语言,编译型语言没有这个东西。因为编译型语言直接编译为机器码,不需要解释执行。
脚本到底是啥呢?
脚本就是解释型语言命令行的一个集合。
3.2 脚本格式要求
1.脚本以 #!/bin/bash 开头
#!/bin/bash是指:此脚本使用/bin/bash来解释执行
- #! 是特殊的表示符
- 其后面跟的是解释此脚本的shell的路径
其实第一句的#!是对脚本的解释器程序路径,脚本的内容是由解释器解释的,我们可以用各种各样的解释器来写对应的脚本。
比如说/bin/csh脚本,/bin/perl脚本,/bin/awk脚本,/bin/sed脚本,甚至/bin/echo等等。
2.脚本需要有可执行权限
chmod 744 myshell.sh
3.3 脚本的常用执行方式
1.方式 1:赋予脚本文件可执行权限
- 1)首先要赋予 helloworld.sh 脚本的+x 权限
- 2)输入脚本的绝对路径或相对路径,执行脚本
当使用命令./shell.sh自执行该脚本时,首先得有执行权限;其次脚本得指定解释器(如以#!/bin/bash开头);如果没有指定,则默认以bash解释器执行。
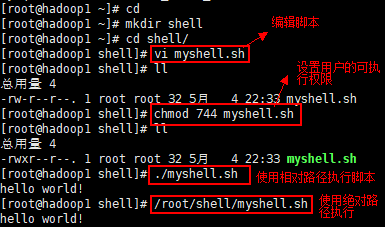
2.方式 2使用指定解释器执行脚本:sh+脚本
- 不用赋予脚本+x 权限,直接执行即可(不推荐)
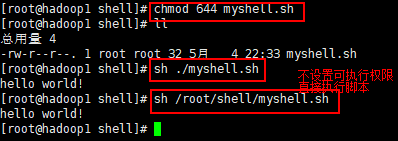
当脚本使用指定解释器时,使用该解释器执行脚本。
3.4 shell脚本的内存环境
当使用shell通过SSH远程登录到linux系统时,系统会创建一个对应的shell进程,该进程是sshd进程的子进程,每个登录的shell都有一个自己的进程。
例如,使用Xshell打开两个系统会话,同时在一个会话中输入命令 bash。系统中会有如下进程:
2
3
4
5
6
7
8
9
2root 2345 1 0 10:02 ? 00:00:00 /usr/sbin/sshd
3root 3153 2345 0 10:29 ? 00:00:02 sshd: root@pts/0
4root 3157 3153 0 10:29 pts/0 00:00:00 -bash
5root 3506 2345 0 14:46 ? 00:00:00 sshd: root@pts/1
6root 3512 3506 0 14:47 pts/1 00:00:00 -bash
7root 3533 3512 0 14:48 pts/1 00:00:00 bash
8
9
可以看出,每一个SSH连接都会创建一个sshd进程的子进程,如2345进程的3153、3506子进程,并为当前shell——bash创建一个子进程。

而进程3533是在进程3512对应的bash环境中输入 bash 命令开启的子进程,属于3512shell的子shell。
shell变量存储在哪?
在当前shell中定义的变量存储在自身进程的内存中,当进程结束(如当前会话结束),相应的内存也就释放,变量也就会释放。
如何永久使用?
将shell变量存储到系统变量中。
注意:执行的shell脚本与自己使用的shell不是一个shell
如有以下脚本a.sh
2
3
4
5
6
2mkdir a
3cd a
4touch b.txt
5
6
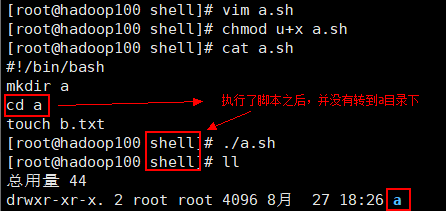
运行之后,并不会转到a目录。
因为:执行脚本时,会在当前shell下启动一个子shell——这是一个独立的shell。同样的,在当前shell中直接输入以下命令也是同样的效果:
2
3
4
5
6
7
2mkdir a
3cd a
4touch b
5exit ->退出到自己的shell
6
7
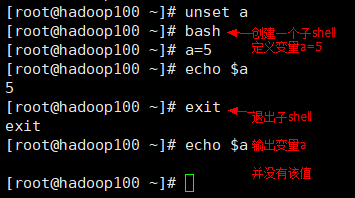
为什么要使用bash启动一个子shell?
因为,当前shell并不一定是bash环境。
脚本中不能使用父shell中的变量,除非:
1)export a -> 将 shell 变量输出为环境变量
或
2)source a.sh ->将脚本在当前shell环境中执行脚本,并不创建子shell
4.shell 的变量
4.1 Shell 的变量的介绍
1) Linux Shell 中的变量分为:
- 系统变量
- 用户自定义变量。
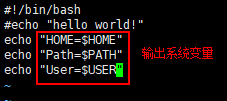
2) 系统变量: $HOME、 $PWD、 $SHELL、 $USER ……
echo $HOME
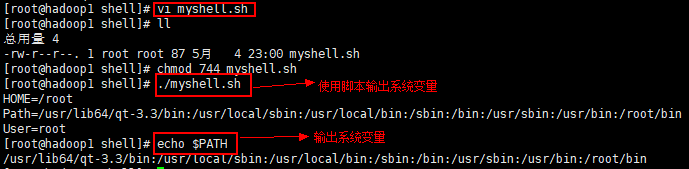
myshell.sh 中的内容:
3) 显示当前 shell 中所有变量: set
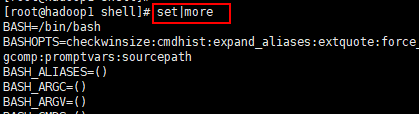
4.2 shell 变量的定义
4.2.1 基本语法
- a)定义变量: 变量=值
- b)撤销变量: unset 变量
- c)声明静态变量: readonly 变量, 注意: 不能 unset
- d)定义全局环境变量:可把变量提升为全局环境变量, 可供其他 shell 程序使用【一会举例 】
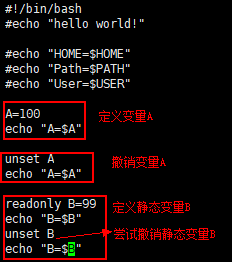
案例
案例 1: 定义变量 A,撤销变量 A
案例 2: 定义静态变量 B,尝试撤销静态变量
a)脚本内容:
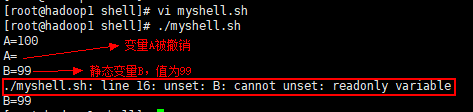
b)脚本运行结果:
4.2.3 定义变量的规则
1)变量名称可以由字母、 数字和下划线组成, 但是不能以数字开头。
2)等号两侧不能有空格****
3)变量名称一般习惯为大写
4.2.4 *将命令的返回值赋给变量
1) A=
1 | 1` |
ls -la
1 | 1` |
反引号:运行里面的命令,并把结果返回给变量 A
2) A=$(ls -la) 等价于反引号
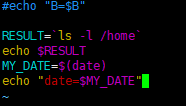
4.2.5 单引号与双引号的区别
单引号会自动对引入的内容作转义,即消除特殊字符的意义。
2
3
4
2ccc
3
4
2
3
4
5
6
7
8
9
10
11
12
13
14
2# 双引号括起,$1依旧表示为传入的第一个参数
3if [ "$1"x = ax ]
4then
5 echo aaa
6# 单引号括起,$1表示为一个普通字符串
7elif [ '$1'x = bx ]
8then
9 echo bbb
10else
11 echo ccc
12fi
13
14
5.设置环境变量
5.1 基本语法
export 变量名=变量值 (功能描述: 将 shell 变量输出为环境变量)
source 配置文件 (功能描述: 让修改后的配置信息立即生效)
echo $变量名 (功能描述: 查询环境变量的值)
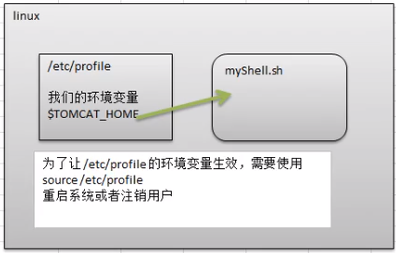
案例:
1)在/etc/profile 文件中定义 TOMCAT_HOME 环境变量
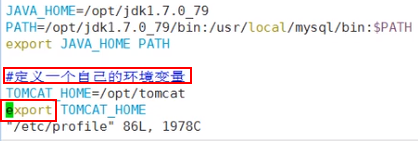
2)查看环境变量 TOMCAT_HOME 的值
echo $TOMCAT_HOME
3)在另外一个 shell 程序中使用 TOMCAT_HOME

注意: 在输出 TOMCAT_HOME 环境变量前, 需要让其生效
source /etc/profile
5.2 自定义环境变量
不建议在 /etc/profile 文件直接配置环境变量。看该文件的注释:去/etc/profile.d/文件夹,自定义自己的文件配置!!
2
3
4
5
6
7
8
9
10
11
12
13
2# /etc/profile
3
4# System wide environment and startup programs, for login setup
5# Functions and aliases go in /etc/bashrc
6
7# It's NOT a good idea to change this file unless you know what you
8# are doing. It's much better to create a custom.sh shell script in
9# /etc/profile.d/ to make custom changes to your environment, as this
10# will prevent the need for merging in future updates.
11……
12
13
除非你知道你在做什么,否则改变这个文件不是一个好主意。在/etc/profile.d/中创建一个custom.sh shell脚本来对环境进行自定义更改要好得多,因为这将满足将来的更新中的合并需求。
案例:配置JDK环境变量
2
3
4
5
6
7
2[zxy@hadoop102 profile.d]$ sudo vim jdk.sh
3#JAVA_HOME
4export JAVA_HOME=/opt/module/jdk1.8.0_144
5export PATH=$PATH:$JAVA_HOME/bin
6
7
保存后退出,让修改后的文件生效,并测试JDK是否安装成功:
2
3
4
5
2[atguigu@hadoop101 jdk1.8.0_144]$ java -version
3java version "1.8.0_144"
4
5
6.位置参数变量
6.1 介绍
当我们执行一个 shell 脚本时, 如果希望获取到命令行的参数信息, 就可以使用到位置参数变量。
比如 : ./myshell.sh 100 200 , 这个就是一个执行 shell 的命令行, 可以在 myshell 脚本中获取到参数信息
6.2 基本语法
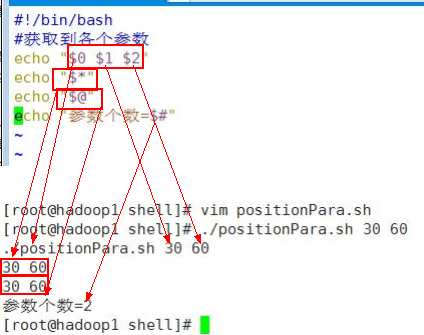
- $n (功能描述: n 为数字,
$0 代表命令本身, $1-$9 代表第一到第九个参数, 十以上的参数, 十以上的参数需要用大括号包含, 如${10})
- $* (功能描述: 这个变量代表命令行中所有的参数, $*把所有的参数看成一个整体)
- $@(功能描述: 这个变量也代表命令行中所有的参数, 不过$@把每个参数区分对待)
- $#(功能描述: 这个变量代表命令行中所有参数的个数)
6.3 位置参数变量应用实例
案例: 编写一个 shell 脚本 positionPara.sh , 在脚本中获取到命令行的各个参数信息
7.预定义变量
7.1 基本介绍
就是 shell 设计者事先已经定义好的变量, 可以直接在 shell 脚本中使用
7.2 基本语法
-
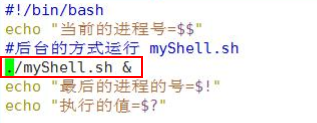
$$ (功能描述: 当前进程的进程号(PID) )
-
$! (功能描述: 后台运行的最后一个进程的进程号(PID) )
-
$?(功能描述: 最后一次执行的命令的返回状态。 如果这个变量的值为 0, 证明上一个命令正确执行; 如果这个变量的值为非 0(具体是哪个数, 由命令自己来决定) , 则证明上一个命令执行不正确)
7.3 应用实例
在一个 shell 脚本中简单使用一下预定义变量
8.运算符
学习如何在 shell 中进行各种运算操作。
基本语法
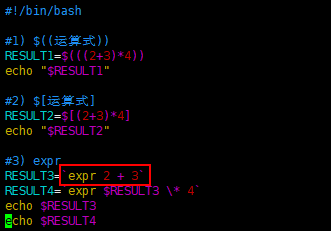
- $((运算式)) 或 $[运算式]
- expr m + n
注意 expr 运算符间要有空格
- expr m – n
- expr *, /, % 乘, 除, 取余
9.条件判断
9.1 基本语法
[ condition ](注意 condition 前后要有空格)
或
test condition
[ condition ]:当条件非空返回 true, 可使用$?验证(0 为 true, >1 为 false)
- [ abc ] 返回 true
- [] 返回 false
9.3 常用判断条件
1)两个整数的比较
- = 可以用做字符串比较
- -lt 小于 less than
- -le 小于等于 less than or equal to
- -eq 等于 equal
- -gt 大于 greater than
- -ge 大于等于 greater than or equal to
- -ne 不等于 not equal to
[ 2 -le 5 ] (2小于等于5)
2)按照文件权限进行判断
- -r 有读的权限 [ -r 文件 ]
- -w 有写的权限
- -x 有执行的权限
[ -r 文件 ]
3)按照文件类型进行判断
- -f 文件存在并且是一个常规的文件(file)
- -e 文件存在 (existence)
- -d 文件存在并是一个目录 (directory)
4)多条件判断(&& 表示前一条命令执行成功时,才执行后一条命令,|| 表示上一条命令执行失败后,才执行下一条命令)
- [ condition ] && echo OK || echo notok
案例实操:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2[zxy@hadoop101 datas]$ [ 23 -ge 22 ]
3[zxy@hadoop101 datas]$ echo $?
40
5
6(2)helloworld.sh是否具有写权限
7[zxy@hadoop101 datas]$ [ -w helloworld.sh ]
8[zxy@hadoop101 datas]$ echo $?
90
10
11(3)/home/atguigu/cls.txt目录中的文件是否存在
12[zxy@hadoop101 datas]$ [ -e /home/atguigu/cls.txt ]
13[zxy@hadoop101 datas]$ echo $?
141
15
16(4)多条件判断(&& 表示前一条命令执行成功时,才执行后一条命令,|| 表示上一条命令执行失败后,才执行下一条命令)
17[zxy@hadoop101 ~]$ [ condition ] && echo OK || echo notok
18OK
19[zxy@hadoop101 datas]$ [ condition ] && [ ] || echo notok
20notok
21
22
9.4 应用实例
案例 1: “ok"是否等于"ok”
案例 2: 23 是否大于等于 22
案例 3: /root/install.log 目录中的文件是否存在
案例 4:myshell.sh 文件是否有可执行权限

判断条件也可以使用 test 替换,详情见 man test
10.流程控制
10.1 if 判断
1.if 判断基本语法
2
3
4
5
6
7
8
9
10
11
12
13
14
2then
3 程序
4fi
5或者
6if [ 条件判断式 ]
7 then
8 程序
9 elif [条件判断式]
10 then
11 程序
12fi
13
14
2.注意事项:
- 1)[ 条件判断式 ]: 中括号和条件判断式之间必须有空格
- 2)推荐使用第二种方式
3.应用实例
案例: 请编写一个 shell 程序, 如果输入的参数, 大于等于 60, 则输出 “及格了”, 如果小于 60,则输出 “不及格”

10.2 case 语句
1.基本语法
2
3
4
5
6
7
8
9
10
11
12
13
14
2"值 1")
3 如果变量的值等于值 1, 则执行程序 1
4;;
5"值 2")
6 如果变量的值等于值 2, 则执行程序 2
7;;
8 …省略其他分支…
9*)
10如果变量的值都不是以上的值, 则执行此程序
11;;
12esac
13
14
2.实例
当命令行参数是 1 时, 输出 “周一”, 是 2 时, 就输出"周二", 其它情况输出 “other”

10.3 for 循环
1.基本语法 1
2
3
4
5
6
2do
3 程序
4done
5
6
应用实例
案例 1 : 打印命令行输入的参数 【会使用到$* 与 $@】

比较$*和$@区别
1)$* 和 $@都表示传递给函数或脚本的所有参数,不被双引号“”包含时,都以$1 $2 …$n的形式输出所有参数
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
2[tom@hadoop101 datas]$ vim for.sh
3
4#!/bin/bash
5# 不加双引号
6for i in $*
7do
8 echo "ban zhang love $i "
9done
10
11for j in $@
12do
13 echo "ban zhang love $j"
14done
15
16[tom@hadoop101 datas]$ bash for.sh cls xz bd
17ban zhang love cls
18ban zhang love xz
19ban zhang love bd
20ban zhang love cls
21ban zhang love xz
22ban zhang love bd
23
24
2)当它们被双引号“”包含时,“$*”会将所有的参数作为一个整体,以“$1 $2 …$n”的形式输出所有参数;“$@”会将各个参数分开,以“$1” “$2”…”$n”的形式输出所有参数。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3#!/bin/bash
4#$*中的所有参数看成是一个整体,所以这个for循环只会循环一次
5for i in "$*"
6do
7 echo "ban zhang love $i"
8done
9
10#$@中的每个参数都看成是独立的,所以“$@”中有几个参数,就会循环几次
11for j in "$@"
12do
13 echo "ban zhang love $j"
14done
15
16[tom@hadoop101 datas]$ chmod 777 for.sh
17[tom@hadoop101 datas]$ bash for.sh cls xz bd
18ban zhang love cls xz bd
19ban zhang love cls
20ban zhang love xz
21ban zhang love bd
22
23
2.基本语法 2
2
3
4
5
6
2do
3 程序
4done
5
6
应用实例
案例 1 : 从 1 加到 100 的值输出显示

for 循环体中使用cat
2
3
4
5
6
7
8
9
2for i in `cat $HADOOP_HOME/etc/hadoop/workers`
3do
4 echo "========== Start Zookeeper in $i =========="
5 ssh $i '$ZOOKEEPER_HOME/bin/zkServer.sh start'
6 echo $?
7done
8
9
10.4 while 循环
1.基本语法
2
3
4
5
6
2do
3 程序
4done
5
6
2.应用实例
案例 1 : 从命令行输入一个数 n, 统计从 1+…+ n 的值是多少?

11.read 读取控制台输入
1.基本语法
read [选项] [参数]
1)选项:
- -p:指定读取值时的提示符;
- -t:指定读取值时等待的时间(秒),如果没有在指定的时间内输入, 就不再等待了。
2)参数:
- 变量: 指定读取值的变量名,将输入值传入该变量
2.应用实例
案例 1: 读取控制台输入一个 num 值
案例 2: 读取控制台输入一个 num 值, 在 10 秒内输入。

12.函数
函数介绍:
shell 编程和其它编程语言一样, 有系统函数, 也可以自定义函数, (系统函数中, 我们这里就介绍两个)。
12.1 系统函数
**1)basename **
- 功能: 返回完整路径最后 / 的部分, 常用于获取文件名
基本语法:
basename [pathname] [suffix]
basename [string] [suffix] (功能描述: basename 命令会删掉所有的前缀包括最后一个(‘/’ )字符, 然后将字符串显示出来。
选项:
- suffix 为后缀, 如果 suffix 被指定了, basename 会将 pathname 或 string 中的 suffix 去掉。

**2)dirname **
- 功能: 返回完整路径最后 / 的前面的部分, 常用于返回路径部分
基本语法:
dirname 文件绝对路径
- 功能描述: 从给定的包含绝对路径的文件名中去除文件名(非目录的部分) , 然后返回剩下的路径(目录的部分)。

12.2 自定义函数
1)基本语法
2
3
4
5
6
7
8
2#方括号表示可选
3{
4 Action;
5 [return int;]
6}
7
8
- 小括号与function至少需要存在一个
- 小括号里并不需要形参
- 调用直接写函数名: funname [值]
2)应用实例
案例 1: 计算输入两个参数的和(read):getSum

3)经验技巧
- a)必须在调用函数地方之前,先声明函数,shell脚本是逐行运行。不会像其它语言一样先编译。
- b)函数返回值,只能通过$?系统变量获得,可以显示加:return返回,如果不加,将以最后一条命令运行结果,作为返回值。return后跟数值n(0-255)
13.Shell 编程综合案例
1.需求分析
- 1)每天凌晨 2:10 备份 数据库 atguiguDB 到 /data/backup/db
- 2)备份开始和备份结束能够给出相应的提示信息
- 3)备份后的文件要求以备份时间为文件名, 并打包成 .tar.gz 的形式, 比如:
2018-03-12_230201.tar.gz
- 4)在备份的同时, 检查是否有 10 天前备份的数据库文件, 如果有就将其删除。
2.编写一个 shell 脚本
1)思路分析

2)代码实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
2#案例:完成数据库的定时备份
3
4#备份的路径
5BACKUP=/data/backup/db
6#当前的时间作为文件名
7DATETIME=$(date +%Y_%m_%d_%H%M%S)
8
9#可以输出变量调试
10#echo ${DATETIME}
11
12echo "=======开始备份========"
13echo "=======备份的路径是 $BACKUP/$DATETIME.tar.gz"
14
15#主机
16HOST=localhost
17#用户名
18DB_USER=root
19#密码
20DB_PWD=root
21#备份数据库名
22DATABASE=atguiguDB
23
24#创建备份的路径
25#如果备份的路径文件夹存在,就使用,否则就创建
26[ ! -d "$BACKUP/$DATETIME" ] && mkdir -p "$BACKUP/$DATETIME"
27
28#执行mysql的备份数据库的指令,将其压缩为文件
29mysqldump -u${DB_USER} -p${DB_PWD} --host=$HOST $DATABASE | gzip > $BACKUP/$DATETIME/$DATETIME.sql.gz
30
31#打包备份文件夹
32cd $BACKUP
33tar -zcvf $DATETIME.tar.gz $DATETIME
34
35#删除临时目录
36rm -rf $BACKUP/$DATETIME
37
38#删除10天前的备份文件
39find $BACKUP -mtime +10 -name "*.tar.gz" -exec rm -rf {} \;
40
41echo "=====备份文件成功==========="
42
43
设置定时任务:
[root@hadoop101 ~]# crontab -e

