1.概述
目前,随着大数据的浪潮,Kafka 被越来越多的企业所认可,如今的Kafka已发展到0.10.x,其优秀的特性也带给我们解决实际业务的方案。对于数据分流来说,既可以分流到离线存储平台(HDFS),离线计算平台(Hive仓库),也可以分流实时流水计算(Storm,Spark)等,同样也可以分流到海量数据查询(HBase),或是及时查询(ElasticSearch)。而今天笔者给大家分享的就是Kafka 分流数据到 ElasticSearch。
2.内容
我们知道,ElasticSearch是有其自己的套件的,简称ELK,即ElasticSearch,Logstash以及Kibana。ElasticSearch负责存储,Logstash负责收集数据来源,Kibana负责可视化数据,分工明确。想要分流Kafka中的消息数据,可以使用Logstash的插件直接消费,但是需要我们编写复杂的过滤条件,和特殊的映射处理,比如系统保留的
1 | 1` |
_uid
1 | 1` |
字段等需要我们额外的转化。今天我们使用另外一种方式来处理数据,使用Kafka的消费API和ES的存储API来处理分流数据。通过编写Kafka消费者,消费对应的业务数据,将消费的数据通过ES存储API,通过创建对应的索引的,存储到ES中。其流程如下图所示:
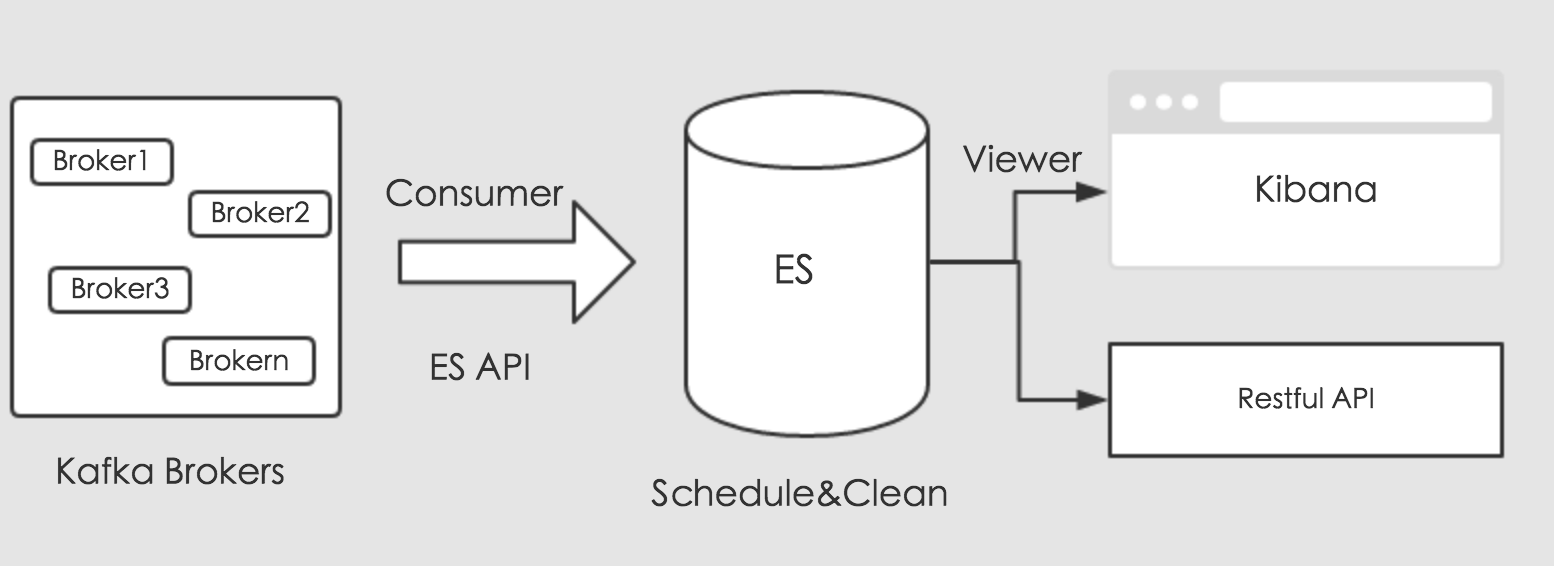
上图可知,消费收集的数据,通过ES提供的存储接口进行存储。存储的数据,这里我们可以规划,做定时调度。最后,我们可以通过Kibana来可视化ES中的数据,对外提供业务调用接口,进行数据共享。
3.实现
下面,我们开始进行实现细节处理,这里给大家提供实现的核心代码部分,实现代码如下所示:
3.1 定义ES格式
我们以插件的形式进行消费,从Kafka到ES的数据流向,只需要定义插件格式,如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2 "job": {
3 "content": {
4 "reader": {
5 "name": "kafka",
6 "parameter": {
7 "topic": "kafka_es_client_error",
8 "groupid": "es2",
9 "bootstrapServers": "k1:9094,k2:9094,k3:9094"
10 },
11 "threads": 6
12 },
13 "writer": {
14 "name": "es",
15 "parameter": {
16 "host": [
17 "es1:9300,es2:9300,es3:9300"
18 ],
19 "index": "client_error_%s",
20 "type": "client_error"
21 }
22 }
23 }
24 }
25}
26
这里处理消费存储的方式,将读和写的源分开,配置各自属性即可。
3.2 数据存储
这里,我们通过每天建立索引进行存储,便于业务查询,实现细节如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
2
3 private final static Logger LOG = LoggerFactory.getLogger(EsProducer.class);
4 private final KafkaConsumer<String, String> consumer;
5 private ExecutorService executorService;
6 private Configuration conf = null;
7 private static int counter = 0;
8
9 public EsProducer() {
10 String root = System.getProperty("user.dir") + "/conf/";
11 String path = SystemConfigUtils.getProperty("kafka.x.plugins.exec.path");
12 conf = Configuration.from(new File(root + path));
13 Properties props = new Properties();
14 props.put("bootstrap.servers", conf.getString("job.content.reader.parameter.bootstrapServers"));
15 props.put("group.id", conf.getString("job.content.reader.parameter.groupid"));
16 props.put("enable.auto.commit", "true");
17 props.put("auto.commit.interval.ms", "1000");
18 props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
19 props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
20 consumer = new KafkaConsumer<String, String>(props);
21 consumer.subscribe(Arrays.asList(conf.getString("job.content.reader.parameter.topic")));
22 }
23
24 public void execute() {
25 executorService = Executors.newFixedThreadPool(conf.getInt("job.content.reader.threads"));
26 while (true) {
27 ConsumerRecords<String, String> records = consumer.poll(100);
28 if (null != records) {
29 executorService.submit(new KafkaConsumerThread(records, consumer));
30 }
31 }
32 }
33
34 public void shutdown() {
35 try {
36 if (consumer != null) {
37 consumer.close();
38 }
39 if (executorService != null) {
40 executorService.shutdown();
41 }
42 if (!executorService.awaitTermination(10, TimeUnit.SECONDS)) {
43 LOG.error("Shutdown kafka consumer thread timeout.");
44 }
45 } catch (InterruptedException ignored) {
46 Thread.currentThread().interrupt();
47 }
48 }
49
50 class KafkaConsumerThread implements Runnable {
51
52 private ConsumerRecords<String, String> records;
53
54 public KafkaConsumerThread(ConsumerRecords<String, String> records, KafkaConsumer<String, String> consumer) {
55 this.records = records;
56 }
57
58 @Override
59 public void run() {
60 String index = conf.getString("job.content.writer.parameter.index");
61 String type = conf.getString("job.content.writer.parameter.type");
62 for (TopicPartition partition : records.partitions()) {
63 List<ConsumerRecord<String, String>> partitionRecords = records.records(partition);
64 for (ConsumerRecord<String, String> record : partitionRecords) {
65 JSONObject json = JSON.parseObject(record.value());
66 List<Map<String, Object>> list = new ArrayList<>();
67 Map<String, Object> map = new HashMap<>();
68 index = String.format(index, CalendarUtils.timeSpan2EsDay(json.getLongValue("_tm") * 1000L));
69
70 if (counter < 10) {
71 LOG.info("Index : " + index);
72 counter++;
73 }
74
75 for (String key : json.keySet()) {
76 if ("_uid".equals(key)) {
77 map.put("uid", json.get(key));
78 } else {
79 map.put(key, json.get(key));
80 }
81 list.add(map);
82 }
83
84 EsUtils.write2Es(index, type, list);
85 }
86 }
87 }
88
89 }
90
91}
92
这里消费的数据源就处理好了,接下来,开始ES的存储,实现代码如下所示:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
2
3
4
5
6
7
8
9
10
11 private static TransportClient client = null;
12
13
14
15
16
17
18
19
20
21 static {
22
23
24
25
26
27 if (client == null) {
28
29
30
31
32
33 client = new PreBuiltTransportClient(Settings.EMPTY);
34
35
36
37
38
39 }
40
41
42
43
44
45 String root = System.getProperty("user.dir") + "/conf/";
46
47
48
49
50
51 String path = SystemConfigUtils.getProperty("kafka.x.plugins.exec.path");
52
53
54
55
56
57 Configuration conf = Configuration.from(new File(root + path));
58
59
60
61
62
63 List<Object> hosts = conf.getList("job.content.writer.parameter.host");
64
65
66
67
68
69 for (Object object : hosts) {
70
71
72
73
74
75 try {
76
77
78
79
80
81 client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(object.toString().split(":")[0]), Integer.parseInt(object.toString().split(":")[1])));
82
83
84
85
86
87 } catch (Exception e) {
88
89
90
91
92
93 e.printStackTrace();
94
95
96
97
98
99 }
100
101
102
103
104
105 }
106
107
108
109
110
111 }
112
113
114
115
116
117
118
119
120
121 public static void write2Es(String index, String type, List<Map<String, Object>> dataSets) {
122
123
124
125
126
127
128
129
130
131 BulkRequestBuilder bulkRequest = client.prepareBulk();
132
133
134
135
136
137 for (Map<String, Object> dataSet : dataSets) {
138
139
140
141
142
143 bulkRequest.add(client.prepareIndex(index, type).setSource(dataSet));
144
145
146
147
148
149 }
150
151
152
153
154
155
156
157
158
159 bulkRequest.execute().actionGet();
160
161
162
163
164
165 // if (client != null) {
166
167
168
169
170
171 // client.close();
172
173
174
175
176
177 // }
178
179
180
181
182
183 }
184
185
186
187
188
189
190
191
192
193 public static void close() {
194
195
196
197
198
199 if (client != null) {
200
201
202
203
204
205 client.close();
206
207
208
209
210
211 }
212
213
214
215
216
217 }
218
219
220
221
222}
223
这里,我们利用BulkRequestBuilder进行批量写入,减少频繁写入率。
4.调度
存储在ES中的数据,如果不需要长期存储,比如:我们只需要存储及时查询数据一个月,对于一个月以前的数据需要清除掉。这里,我们可以编写脚本直接使用Crontab来进行简单调用即可,脚本如下所示:
2
3
4
5
2# <Usage>: ./delete_es_by_day.sh kafka_error_client logsdate 30 </Usage>
3
4echo "<Usage>: ./delete_es_by_day.sh kafka_error_client logsdate 30 </Usage>"
5
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
2daycolumn=$2
3savedays=$3
4format_day=$4
5
6if [ ! -n "$savedays" ]; then
7 echo "Oops. The args is not right,please input again...."
8 exit 1
9fi
10
11if [ ! -n "$format_day" ]; then
12 format_day='%Y%m%d'
13fi
14
15sevendayago=`date -d "-${savedays} day " +${format_day}`
16
17curl -XDELETE "es1:9200/${index_name}/_query?pretty" -d "
18{
19 "query": {
20 "filtered": {
21 "filter": {
22 "bool": {
23 "must": {
24 "range": {
25 "${daycolumn}": {
26 "from": null,
27 "to": ${sevendayago},
28 "include_lower": true,
29 "include_upper": true
30 }
31 }
32 }
33 }
34 }
35 }
36 }
37}"
38
39echo "Finished."
40
然后,在Crontab中进行定时调度即可。
5.总结
这里,我们在进行数据写入ES的时候,需要注意,有些字段是ES保留字段,比如
1 | 1` |
_uid
1 | 1` |
,这里我们需要转化,不然写到ES的时候,会引发冲突导致异常,最终写入失败。
