1.概述
在《Kafka实战-实时日志统计流程》一文中,谈到了Storm的相关问题,在完成实时日志统计时,我们需要用到Storm去消费Kafka Cluster中的数据,所以,这里我单独给大家分享一篇Storm Cluster的搭建部署。以下是今天的分享目录:
- Storm简述
- 基础软件
- 安装部署
- 效果预览
下面开始今天的内容分享。
2.Storm简述
Twitter将Storm开源了,这是一个分布式的、容错的实时计算系统,已被贡献到Apache基金会,下载地址如下所示:
2
2
Storm的主要特点如下:
- 简单的编程模型。类似于MapReduce降低了并行批处理复杂性,Storm降低了进行实时处理的复杂性。
- 可以使用各种编程语言。你可以在Storm之上使用各种编程语言。默认支持Clojure、Java、Ruby和Python。要增加对其他语言的支持,只需实现一个简单的Storm通信协议即可。
- 容错性。Storm会管理工作进程和节点的故障。
- 水平扩展。计算是在多个线程、进程和服务器之间并行进行的。
- 可靠的消息处理。Storm保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
- 快速。系统的设计保证了消息能得到快速的处理,使用ØMQ作为其底层消息队列。
- 本地模式。Storm有一个本地模式,可以在处理过程中完全模拟Storm集群。这让你可以快速进行开发和单元测试。
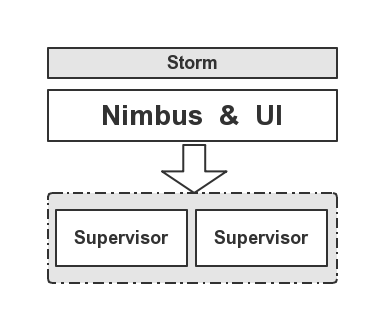
Storm集群由一个主节点和多个工作节点组成。主节点运行了一个名为“Nimbus”的守护进程,用于分配代码、布置任务及故障检测。每个工作节 点都运行了一个名为“Supervisor”的守护进程,用于监听工作,开始并终止工作进程。Nimbus和Supervisor都能快速失败,而且是无 状态的,这样一来它们就变得十分健壮,两者的协调工作是由Apache的ZooKeeper来完成的。
Storm的术语包括Stream、Spout、Bolt、Task、Worker、Stream Grouping和Topology。Stream是被处理的数据。Spout是数据源。Bolt处理数据。Task是运行于Spout或Bolt中的 线程。Worker是运行这些线程的进程。Stream Grouping规定了Bolt接收什么东西作为输入数据。数据可以随机分配(术语为Shuffle),或者根据字段值分配(术语为Fields),或者广播(术语为All),或者总是发给一个Task(术语为Global),也可以不关心该数据(术语为None),或者由自定义逻辑来决定(术语为 Direct)。Topology是由Stream Grouping连接起来的Spout和Bolt节点网络。在Storm Concepts页面里对这些术语有更详细的描述。
3.基础软件
在搭建Storm集群时,我们需要有Storm安装包,这里我采用的是Apache 版本的Storm安装包,下载链接如下所示:
Storm安装包 《下载地址》
ZooKeeper安装包 《下载地址》
在下载完成相关依赖基础软件后,下面我们开始安装部署Storm集群。
4.安装部署
首先,我们解压相关依赖基础软件,关于ZK的安装环节,这里不做介绍,大家可以参考我写的《配置高可用的Hadoop平台》,里面有详细介绍如何安装ZK的步骤,下面重点介绍Storm集群搭建详情。
-
解压Storm安装包
2
2
-
配置环节变量
2
3
2export PATH=$PATH:$STORM_HOME/bin
3
-
配置Storm配置文件(storm.yaml)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2storm.zookeeper.servers:
3 - "dn1"
4 - "dn2"
5 - "dn3"
6storm.zookeeper.port: 2181
7
8nimbus.host: "dn1"
9
10supervisor.slots.ports:
11 - 6700
12 - 6701
13 - 6702
14 - 6703
15
16storm.local.dir: "/home/hadoop/data/storm"
17
下面我们来看Storm的角色分配,如下图所示:
在配置完成相关文件后,我们使用scp命令将文件分发到各个节点,命令如下所示:
2
3
2[hadoop@dn1 ~]$ scp -r storm-0.9.4/ hadoop@dn3:~/
3
-
启动ZK集群
2
3
4
5
2[hadoop@dn1 ~]$ zkServer.sh start
3[hadoop@dn2 ~]$ zkServer.sh start
4[hadoop@dn3 ~]$ zkServer.sh start
5
-
启动集群
2
2
2
3
4
2[hadoop@dn2 ~]$ storm supervisor &
3[hadoop@dn3 ~]$ storm supervisor &
4
-
启动Storm UI
2
2
-
查看启动进程
2
3
4
5
6
22098 Jps
31983 core
41893 QuorumPeerMain
51930 nimbus
6
2
3
4
5
6
7
8
21763 worker
31762 worker
41662 QuorumPeerMain
51765 worker
61692 supervisor
71891 Jps
8
2
3
4
5
22016 QuorumPeerMain
32057 supervisor
42213 Jps
5
5.效果预览
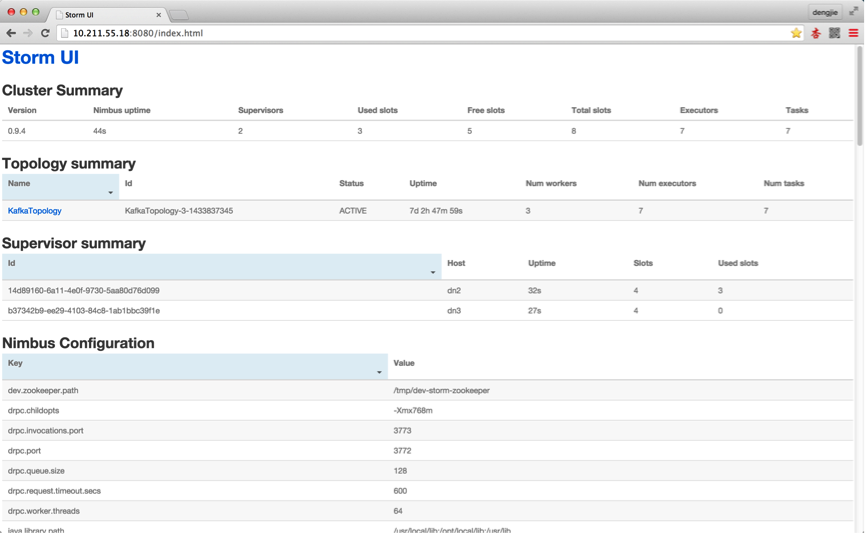
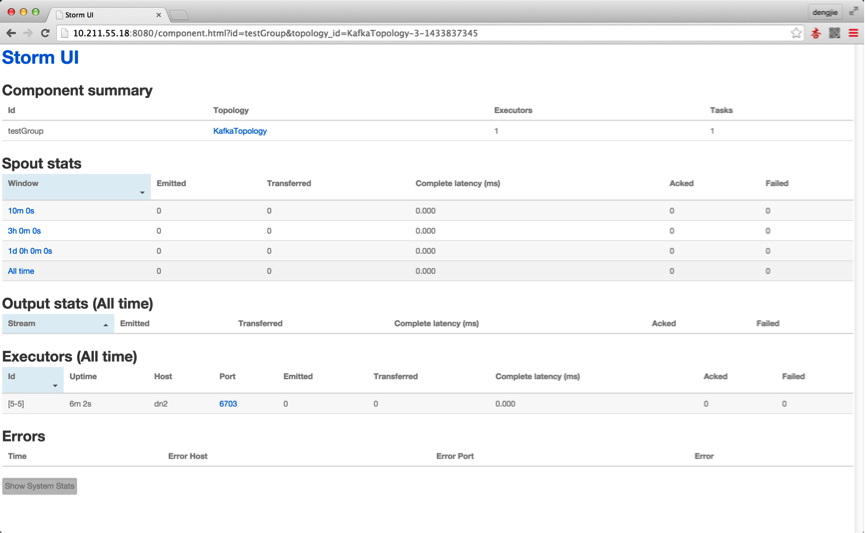
由于,集群我做过测试,提交过Topology,所以截图中会有提交记录,从上面的dn2节点的进程中也可以看出,有相应的worker进程,若是首次安装,未提交任务是不会有对应的显示的,下面附上Storm UI中相关的截图预览,如下图所示:

6.总结
这就是本篇为大家介绍的Storm Cluster的搭建部署,从上面的Storm的分布图中我们可以细心的发现,Storm的分布存在单点问题,国外已经有Storm HA版本,不过这个非官方版本,目前Storm提供了一些机制来保证即使在节点挂了或者消息被丢失的情况下也能正确的进行数据处理,可以参考官方给出的解决方案,地址如下所示:
2
2
7.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
