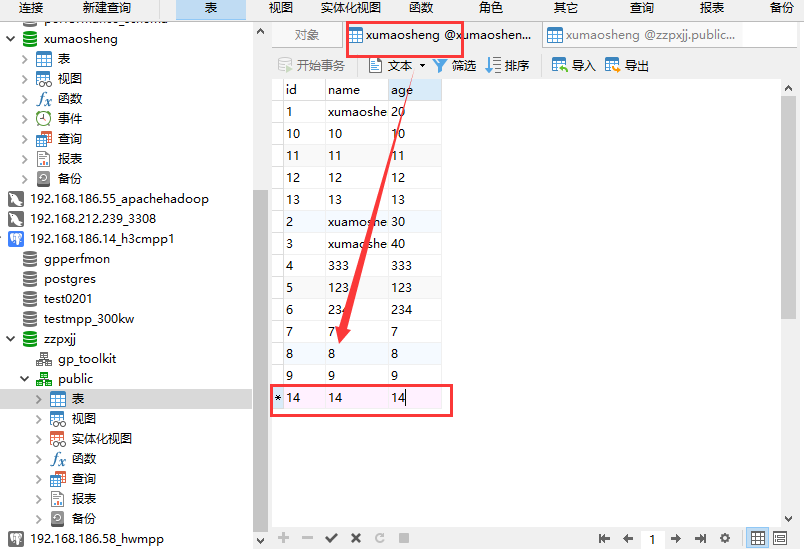
1. 需求
将mysql增量变化的数据,实时的插入到postgresql数据库中,方法有多种实现,这里采用通过flume配置mysql的数据库源,然后flume采集到mysql的增量数据,作为kafka的生产者,然后进入kafka短暂存储,storm作为kafka的消费者,消费到kafka中的增量mysql数据,进行处理,插入到postgresql中。
整个实验环境在HDP环境中,也可以自行搭建Apache Hadoop平台。
2. kafka
2
3
4
5
6
7
8
2
3./kafka-topics.sh --create --zookeeper 192.168.186.48:2181 --replication-factor 1 --partitions 1 --topic xumaosheng
4./kafka-topics.sh --list --zookeeper 192.168.186.48:2181
5./kafka-console-producer.sh --broker-list 192.168.186.48:6667 --topic xumaosheng
6./kafka-console-consumer.sh --zookeeper 192.168.186.48:2181 --topic xumaosheng --from-beginning
7
8
上述命令,可以简单模拟,通过kafka实现生产者,消费者。
但是实际过程中,不是单单的shell端生产消费,所以上述命令只需要创建topic即可。
3. flume
在安装了flume的节点上,在flume的conf目录下,添加mysql-flume.conf文件,内容如下:
a1.channels = ch-1
a1.sources = src-1
a1.sinks = k1
###########sql source#################
#For each one of the sources, the type is defined
a1.sources.src-1.type = org.keedio.flume.source.SQLSource
a1.sources.src-1.hibernate.connection.url =
jdbc:mysql://192.168.186.48:3306/xumaosheng
#Hibernate Database connection properties
a1.sources.src-1.hibernate.connection.user =
ambari
a1.sources.src-1.hibernate.connection.password =
Gepoint
a1.sources.src-1.hibernate.connection.autocommit = true
a1.sources.src-1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
a1.sources.src-1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
a1.sources.src-1.run.query.delay=5000
a1.sources.src-1.status.file.path =
/usr/hdp/2.6.3.0-235/flume
a1.sources.src-1.status.file.name = sqlSource.status
#Custom query
a1.sources.src-1.start.from = 0
a1.sources.src-1.custom.query =
select id, name,age from xumaosheng where id > $@$ order by id asc
a1.sources.src-1.batch.size = 1000
a1.sources.src-1.max.rows = 1000
a1.sources.src-1.hibernate.connection.provider_class = org.hibernate.connection.C3P0ConnectionProvider
a1.sources.src-1.hibernate.c3p0.min_size=1
a1.sources.src-1.hibernate.c3p0.max_size=10
################################################################
a1.channels.ch-1.type = memory
a1.channels.ch-1.capacity = 10000
a1.channels.ch-1.transactionCapacity = 10000
a1.channels.ch-1.byteCapacityBufferPercentage = 20
a1.channels.ch-1.byteCapacity = 800000
################################################################
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic =
xumaosheng
a1.sinks.k1.brokerList =
192.168.186.48:6667
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.channel = c1
a1.sinks.k1.channel = ch-1
a1.sources.src-1.channels=ch-1
注意标红的地方需要对应修改,并且需要下载mysql驱动包,以及flume-ng-sql-source-1.4.3.jar包,放到flume的lib下。
执行:
2
3
2
3
如果需要后台执行:
2
3
2
3
可以通过简单的代码测试,能否从kafka消费到数据!
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
2 <dependency>
3 <groupId>org.apache.kafka</groupId>
4 <artifactId>kafka_2.10</artifactId>
5 <version>0.8.2.0</version>
6 <exclusions>
7 <exclusion>
8 <groupId>org.apache.zookeeper</groupId>
9 <artifactId>zookeeper</artifactId>
10 </exclusion>
11 <exclusion>
12 <groupId>org.slf4j</groupId>
13 <artifactId>slf4j-log4j12</artifactId>
14 </exclusion>
15 </exclusions>
16 </dependency>
17 <dependency>
18 <groupId>org.apache.storm</groupId>
19 <artifactId>storm-core</artifactId>
20 <version>0.9.5</version>
21 <exclusions>
22 <exclusion>
23 <groupId>org.slf4j</groupId>
24 <artifactId>log4j-over-slf4j</artifactId>
25 </exclusion>
26 <exclusion>
27 <groupId>org.slf4j</groupId>
28 <artifactId>slf4j-api</artifactId>
29 </exclusion>
30 </exclusions>
31 </dependency>
32 <dependency>
33 <groupId>org.apache.storm</groupId>
34 <artifactId>storm-kafka</artifactId>
35 <version>0.9.5</version>
36 </dependency>
37 <dependency>
38 <groupId>com.google.code.gson</groupId>
39 <artifactId>gson</artifactId>
40 <version>2.4</version>
41 </dependency>
42 <dependency>
43 <groupId>redis.clients</groupId>
44 <artifactId>jedis</artifactId>
45 <version>2.7.3</version>
46 </dependency>
47 <dependency>
48 <groupId>commons-io</groupId>
49 <artifactId>commons-io</artifactId>
50 <version>2.4</version>
51 </dependency>
52 <dependency>
53 <groupId>org.postgresql</groupId>
54 <artifactId>postgresql</artifactId>
55 <version>42.2.5.jre7</version>
56 </dependency>
57 </dependencies>
58
59
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
2
3import java.util.HashMap;
4import java.util.List;
5import java.util.Map;
6import java.util.Properties;
7
8import kafka.consumer.Consumer;
9import kafka.consumer.ConsumerConfig;
10import kafka.consumer.ConsumerIterator;
11import kafka.consumer.KafkaStream;
12import kafka.javaapi.consumer.ConsumerConnector;
13
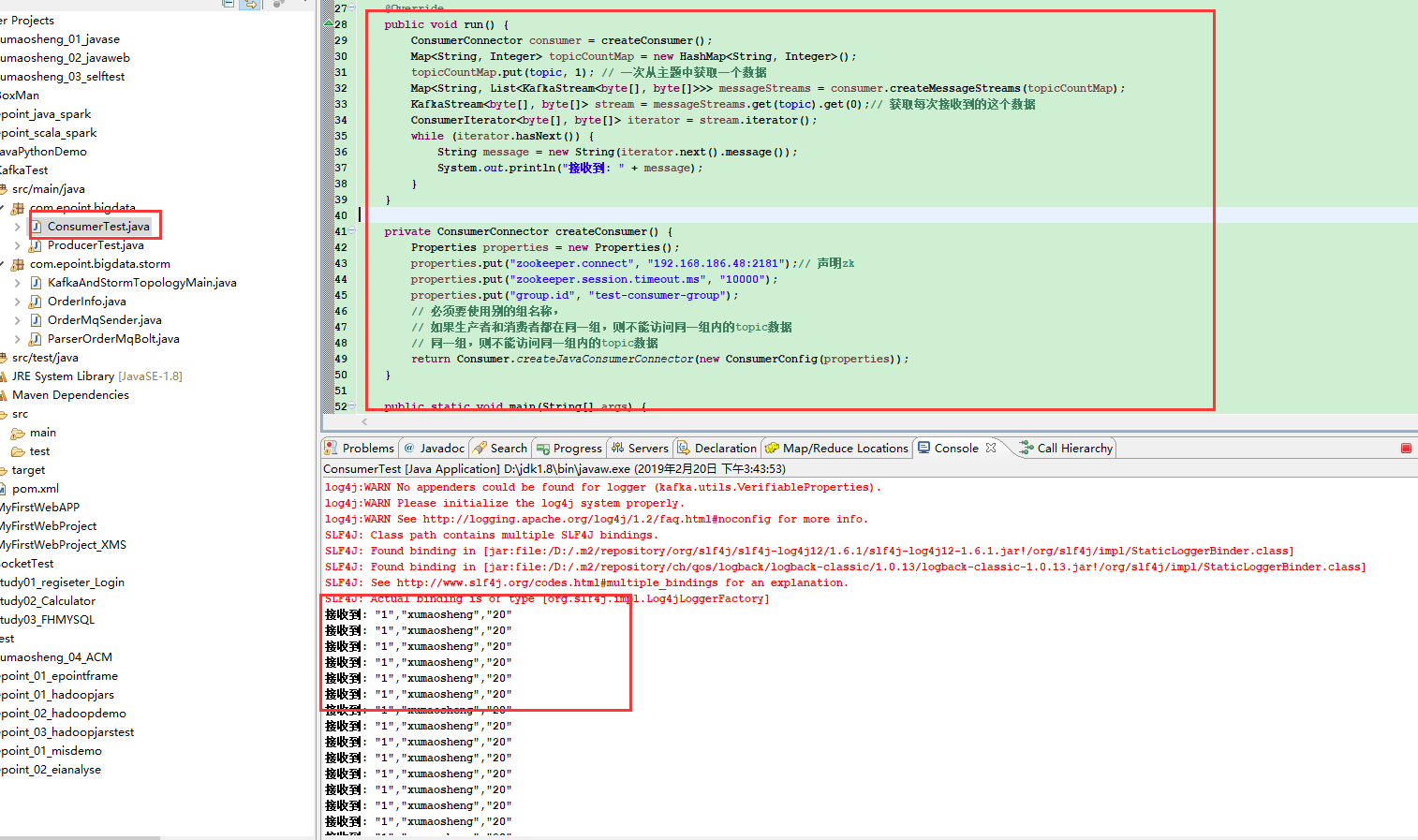
14public class ConsumerTest extends Thread {
15
16 private String topic;
17
18 public ConsumerTest(String topic) {
19 super();
20 this.topic = topic;
21 }
22
23 @Override
24 public void run() {
25 ConsumerConnector consumer = createConsumer();
26 Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
27 topicCountMap.put(topic, 1); // 一次从主题中获取一个数据
28 Map<String, List<KafkaStream<byte[], byte[]>>> messageStreams = consumer.createMessageStreams(topicCountMap);
29 KafkaStream<byte[], byte[]> stream = messageStreams.get(topic).get(0);// 获取每次接收到的这个数据
30 ConsumerIterator<byte[], byte[]> iterator = stream.iterator();
31 while (iterator.hasNext()) {
32 String message = new String(iterator.next().message());
33 System.out.println("接收到: " + message);
34 }
35 }
36
37 private ConsumerConnector createConsumer() {
38 Properties properties = new Properties();
39 properties.put("zookeeper.connect", "192.168.186.48:2181");// 声明zk
40 properties.put("zookeeper.session.timeout.ms", "10000");
41 properties.put("group.id", "test-consumer-group");
42 // 必须要使用别的组名称,
43 // 如果生产者和消费者都在同一组,则不能访问同一组内的topic数据
44 // 同一组,则不能访问同一组内的topic数据
45 return Consumer.createJavaConsumerConnector(new ConsumerConfig(properties));
46 }
47
48 public static void main(String[] args) {
49 new ConsumerTest("xumaosheng").start();// 使用kafka集群中创建好的主题 test
50 }
51}
52
53
4. storm
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
2
3import java.sql.Connection;
4import java.sql.DriverManager;
5import java.sql.Statement;
6import java.util.Map;
7
8import backtype.storm.task.TopologyContext;
9import backtype.storm.topology.BasicOutputCollector;
10import backtype.storm.topology.IBasicBolt;
11import backtype.storm.topology.OutputFieldsDeclarer;
12import backtype.storm.tuple.Tuple;
13
14public class MyKafkaBolt implements IBasicBolt {
15
16 private static final long serialVersionUID = 1L;
17
18 @Override
19 public void cleanup() {
20 // TODO Auto-generated method stub
21
22 }
23
24 @Override
25 public void execute(Tuple input, BasicOutputCollector collector) {
26 // TODO Auto-generated method stub
27
28 String kafkaMsg = input.getString(0);
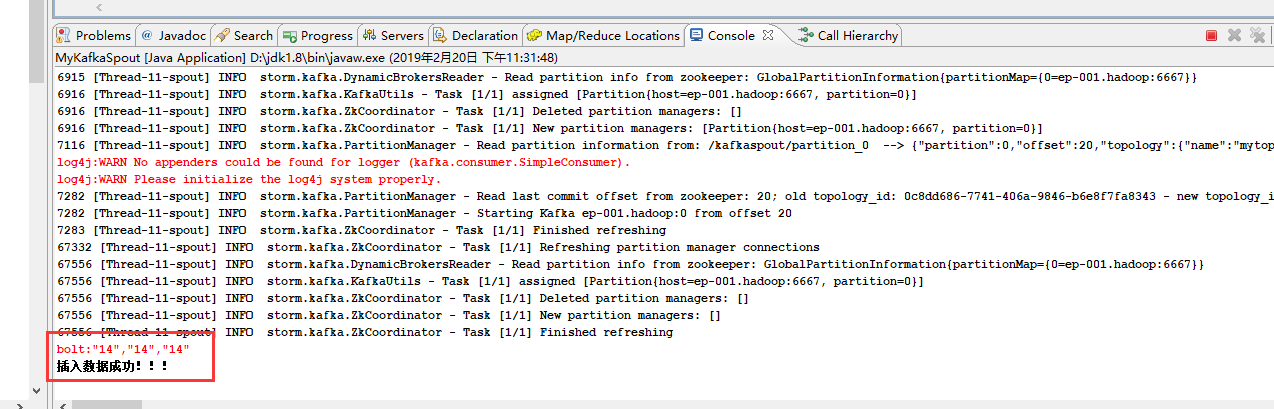
29 System.err.println("bolt:" + kafkaMsg);
30 String[] arr = kafkaMsg.replaceAll("\"", " ").split(",");
31 insert("xumaosheng", arr[0], arr[1], arr[2]);
32 }
33
34 @Override
35 public void prepare(Map stormConf, TopologyContext context) {
36 // TODO Auto-generated method stub
37
38 }
39
40 @Override
41 public void declareOutputFields(OutputFieldsDeclarer declarer) {
42 // TODO Auto-generated method stub
43
44 }
45
46 @Override
47 public Map<String, Object> getComponentConfiguration() {
48 // TODO Auto-generated method stub
49 return null;
50 }
51
52 private static Connection getConn() {
53 String url = "jdbc:postgresql://192.168.186.14:5434/zzpxjj";
54 String user = "dbuser";
55 String pwd = "123456";
56 Connection conn = null;
57 try {
58 Class.forName("org.postgresql.Driver");
59 conn = DriverManager.getConnection(url, user, pwd);
60 } catch (Exception e) {
61 e.printStackTrace();
62 }
63 return conn;
64 }
65
66 // insert
67 private static void insert(String tablename, String id, String name, String age) {
68 String sql = "insert into " + tablename + "(id,name,age) values('" + id + "','" + name + "','" + age + "')";
69 try {
70 Statement stmt = (Statement) getConn().createStatement();
71 stmt.executeUpdate(sql);
72 System.out.println("插入数据成功!!!");
73 stmt.close();
74 } catch (Exception e) {
75 e.printStackTrace();
76 }
77 }
78}
79
80
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
2
3import java.util.ArrayList;
4import java.util.List;
5
6import backtype.storm.Config;
7import backtype.storm.LocalCluster;
8import backtype.storm.StormSubmitter;
9import backtype.storm.generated.AlreadyAliveException;
10import backtype.storm.generated.InvalidTopologyException;
11import backtype.storm.spout.SchemeAsMultiScheme;
12import backtype.storm.topology.TopologyBuilder;
13import storm.kafka.KafkaSpout;
14import storm.kafka.SpoutConfig;
15import storm.kafka.StringScheme;
16import storm.kafka.ZkHosts;
17
18public class MyKafkaSpout {
19
20 public static void main(String[] args) throws Exception {
21 // TODO Auto-generated method stub
22
23 String topic = "xumaosheng1";
24 ZkHosts zkHosts = new ZkHosts("192.168.186.48:2181");
25 SpoutConfig spoutConfig = new SpoutConfig(zkHosts, topic, "", "kafkaspout");
26 List<String> zkServers = new ArrayList<String>();
27 zkServers.add("192.168.186.48");
28 spoutConfig.zkServers = zkServers;
29 spoutConfig.zkPort = 2181;
30 spoutConfig.socketTimeoutMs = 30 * 1000;
31 spoutConfig.scheme = new SchemeAsMultiScheme(new StringScheme());
32
33 TopologyBuilder builder = new TopologyBuilder();
34 builder.setSpout("spout", new KafkaSpout(spoutConfig), 1);
35 builder.setBolt("bolt1", new MyKafkaBolt(), 1).shuffleGrouping("spout");
36
37 Config conf = new Config();
38 conf.setDebug(false);
39
40 if (args.length > 0) {
41 try {
42 StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
43 } catch (AlreadyAliveException e) {
44 e.printStackTrace();
45 } catch (InvalidTopologyException e) {
46 e.printStackTrace();
47 }
48 } else {
49 LocalCluster localCluster = new LocalCluster();
50 localCluster.submitTopology("mytopology", conf, builder.createTopology());
51 }
52 }
53}
54
55
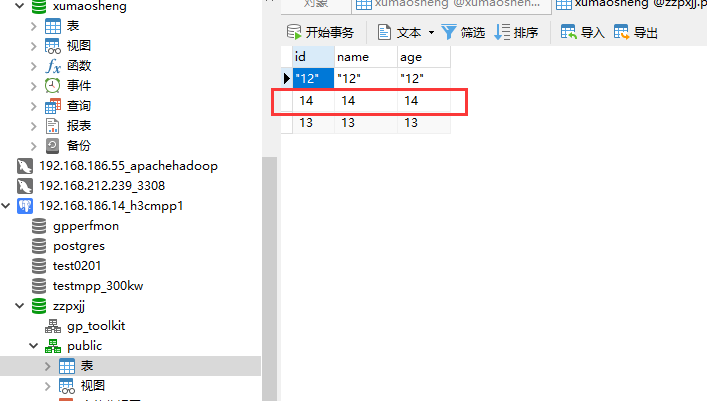
5. 结果验证