前言
分享一下分布式锁
案例介绍
在尝试了解分布式锁之前,大家可以想象一下,什么场景下会使用分布式锁?
单机应用架构中,秒杀案例使用ReentrantLcok或者synchronized来达到秒杀商品互斥的目的。然而在分布式系统中,会存在多台机器并行去实现同一个功能。也就是说,在多进程中,如果还使用以上JDK提供的进程锁,来并发访问数据库资源就可能会出现商品超卖的情况。因此,需要我们来实现自己的分布式锁。
实现一个分布式锁应该具备的特性:
- 高可用、高性能的获取锁与释放锁
- 在分布式系统环境下,一个方法或者变量同一时间只能被一个线程操作
- 具备锁失效机制,网络中断或宕机无法释放锁时,锁必须被删除,防止死锁
- 具备阻塞锁特性,即没有获取到锁,则继续等待获取锁
- 具备非阻塞锁特性,即没有获取到锁,则直接返回获取锁失败
- 具备可重入特性,一个线程中可以多次获取同一把锁,比如一个线程在执行一个带锁的方法,该方法中又调用了另一个需要相同锁的方法,则该线程可以直接执行调用的方法,而无需重新获得锁
几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项。”所以,很多系统在设计之初就要对这三者做出取舍。在互联网领域的绝大多数的场景中,都需要牺牲强一致性来换取系统的高可用性,系统往往只需要保证“最终一致性”,只要这个最终时间是在用户可以接受的范围内即可。
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式事务、分布式锁等。有的时候,我们需要保证一个方法在同一时间内只能被同一个线程执行。在单机环境中,Java中其实提供了很多并发处理相关的API,但是这些API在分布式场景中就无能为力了。也就是说单纯的Java Api并不能提供分布式锁的能力。所以针对分布式锁的实现目前有多种方案。
针对分布式锁的实现,目前比较常用的有以下几种方案:
- 基于数据库实现分布式锁
- 基于缓存(redis,memcached,tair)实现分布式锁
- 基于Zookeeper实现分布式锁
前两种对于分布式生产环境来说并不是特别推荐,高并发下数据库锁性能太差,Redis在锁时间限制和缓存一致性存在一定问题。最好的方式是用 Zookeeper 如何实现分布式锁。
在分析这几种实现方案之前我们先来想一下,我们需要的分布式锁应该是怎么样的?(这里以方法锁为例,资源锁同理)
-
可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
-
这把锁要是一把可重入锁(避免死锁)
-
这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
-
有高可用的获取锁和释放锁功能
-
获取锁和释放锁的性能要好
基于缓存实现分布式锁
相比较于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点。而且很多缓存是可以集群部署的,可以解决单点问题。
目前有很多成熟的缓存产品,包括Redis,memcached以及我们公司内部的Tair。
这里以Tair为例来分析下使用缓存实现分布式锁的方案。关于Redis和memcached在网络上有很多相关的文章,并且也有一些成熟的框架及算法可以直接使用。
基于Tair的实现分布式锁其实和Redis类似,其中主要的实现方式是使用TairManager.put方法来实现。
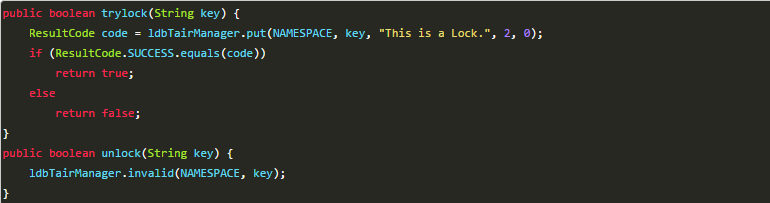
以上实现方式同样存在几个问题:
这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在tair中,其他线程无法再获得到锁。
这把锁只能是非阻塞的,无论成功还是失败都直接返回。
这把锁是非重入的,一个线程获得锁之后,在释放锁之前,无法再次获得该锁,因为使用到的key在tair中已经存在。无法再执行put操作。
当然,同样有方式可以解决。
- 没有失效时间?tair的put方法支持传入失效时间,到达时间之后数据会自动删除。
- 非阻塞?while重复执行。
- 非可重入?在一个线程获取到锁之后,把当前主机信息和线程信息保存起来,下次再获取之前先检查自己是不是当前锁的拥有者。
但是,失效时间我设置多长时间为好?如何设置的失效时间太短,方法没等执行完,锁就自动释放了,那么就会产生并发问题。如果设置的时间太长,其他获取锁的线程就可能要平白的多等一段时间。这个问题使用数据库实现分布式锁同样存在
总结
可以使用缓存来代替数据库来实现分布式锁,这个可以提供更好的性能,同时,很多缓存服务都是集群部署的,可以避免单点问题。并且很多缓存服务都提供了可以用来实现分布式锁的方法,比如Tair的put方法,redis的setnx方法等。并且,这些缓存服务也都提供了对数据的过期自动删除的支持,可以直接设置超时时间来控制锁的释放。
使用缓存实现分布式锁的优点
- 性能好,实现起来较为方便。
使用缓存实现分布式锁的缺点
- 通过超时时间来控制锁的失效时间并不是十分的靠谱。
基于Zookeeper实现分布式锁
实现原理
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能存在唯一文件名。
数据模型
- PERSISTENT 持久化节点,节点创建后,不会因为会话失效而消失
- EPHEMERAL 临时节点, 客户端session超时此类节点就会被自动删除
- EPHEMERAL_SEQUENTIAL 临时自动编号节点
- PERSISTENT_SEQUENTIAL 顺序自动编号持久化节点,这种节点会根据当前已存在的节点数自动加 1
监视器(watcher)
当创建一个节点时,可以注册一个该节点的监视器,当节点状态发生改变时,watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次。
根据zookeeper的这些特性,我们来看看如何利用这些特性来实现分布式锁:
- 创建一个锁目录lock
- 线程A获取锁会在lock目录下,创建临时顺序节点
- 获取锁目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁
- 线程B创建临时节点并获取所有兄弟节点,判断自己不是最小节点,设置监听(watcher)比自己次小的节点
- 线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是最小的节点,获得锁
基于zookeeper临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
来看下Zookeeper能不能解决前面提到的问题。
锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
-
非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
-
不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
-
单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。
代码分析
尽管ZooKeeper已经封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。但是如果让一个普通开发者去手撸一个分布式锁还是比较困难的,在秒杀案例中我们直接使用 Apache 开源的curator 开实现 Zookeeper 分布式锁。
这里我们使用以下版本,截止目前最新版4.0.1:
2
3
4
5
6
7
2<dependency>
3 <groupId>org.apache.curator</groupId>
4 <artifactId>curator-recipes</artifactId>
5 <version>2.10.0</version>
6</dependency>
7
首先,我们看下InterProcessLock接口中的几个方法:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2* 获取锁、阻塞等待、可重入
3*/
4public void acquire() throws Exception;
5
6/**
7* 获取锁、阻塞等待、可重入、超时则获取失败
8*/
9public boolean acquire(long time, TimeUnit unit) throws Exception;
10
11/**
12* 释放锁
13*/
14public void release() throws Exception;
15
16/**
17* Returns true if the mutex is acquired by a thread in this JVM
18*/
19boolean isAcquiredInThisProcess();
20
获取锁
2
3
4
5
6
7
8
9
2public void acquire() throws Exception
3 {
4 if ( !internalLock(-1, null) )
5 {
6 throw new IOException("Lost connection while trying to acquire lock: " + basePath);
7 }
8 }
9
具体实现
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2 {
3 /*
4 实现同一个线程可重入性,如果当前线程已经获得锁,
5 则增加锁数据中lockCount的数量(重入次数),直接返回成功
6 */
7 //获取当前线程
8 Thread currentThread = Thread.currentThread();
9 //获取当前线程重入锁相关数据
10 LockData lockData = threadData.get(currentThread);
11 if ( lockData != null )
12 {
13 //原子递增一个当前值,记录重入次数,后面锁释放会用到
14 lockData.lockCount.incrementAndGet();
15 return true;
16 }
17 //尝试连接zookeeper获取锁
18 String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
19 if ( lockPath != null )
20 {
21 //创建可重入锁数据,用于记录当前线程重入次数
22 LockData newLockData = new LockData(currentThread, lockPath);
23 threadData.put(currentThread, newLockData);
24 return true;
25 }
26 //获取锁超时或者zk通信异常返回失败
27 return false;
28 }
29
Zookeeper获取锁实现:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
2 {
3 //获取当前时间戳
4 final long startMillis = System.currentTimeMillis();
5 //如果unit不为空(非阻塞锁),把当前传入time转为毫秒
6 final Long millisToWait = (unit != null) ? unit.toMillis(time) : null;
7 //子节点标识
8 final byte[] localLockNodeBytes = (revocable.get() != null) ? new byte[0] : lockNodeBytes;
9
10 //尝试次数
11 int retryCount = 0;
12 String ourPath = null;
13 boolean hasTheLock = false;
14 boolean isDone = false;
15 //自旋锁,循环获取锁
16 while ( !isDone )
17 {
18 isDone = true;
19 try
20 {
21 //在锁节点下创建临时且有序的子节点,例如:_c_008c1b07-d577-4e5f-8699-8f0f98a013b4-lock-000000001
22 ourPath = driver.createsTheLock(client, path, localLockNodeBytes);
23 //如果当前子节点序号最小,获得锁则直接返回,否则阻塞等待前一个子节点删除通知(release释放锁)
24 hasTheLock = internalLockLoop(startMillis, millisToWait, ourPath);
25 }
26 catch ( KeeperException.NoNodeException e )
27 {
28 //异常处理,如果找不到节点,这可能发生在session过期等时,因此,如果重试允许,只需重试一次即可
29 if ( client.getZookeeperClient().getRetryPolicy().allowRetry(retryCount++, System.currentTimeMillis() - startMillis, RetryLoop.getDefaultRetrySleeper()) )
30 {
31 isDone = false;
32 }
33 else
34 {
35 throw e;
36 }
37 }
38 }
39 //如果获取锁则返回当前锁子节点路径
40 if ( hasTheLock )
41 {
42 return ourPath;
43 }
44 return null;
45 }
46
判断是否为最小节点:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
2 {
3 boolean haveTheLock = false;
4 boolean doDelete = false;
5
6 try
7 {
8 if ( revocable.get() != null )
9 {
10 client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
11 }
12
13 //自旋获取锁
14 while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock )
15 {
16 //获取所有子节点集合
17 List<String> children = getSortedChildren();
18
19 //判断当前子节点是否为最小子节点
20 String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
21
22 PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
23 //如果是最小节点则获取锁
24 if ( predicateResults.getsTheLock() )
25 {
26 haveTheLock = true;
27 }
28 else
29 {
30 //获取前一个节点,用于监听
31 String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
32 synchronized(this)
33 {
34 try
35 {
36 //这里使用getData()接口而不是checkExists()是因为,如果前一个子节点已经被删除了那么会抛出异常而且不会设置事件监听器,而checkExists虽然也可以获取到节点是否存在的信息但是同时设置了监听器,这个监听器其实永远不会触发,对于Zookeeper来说属于资源泄露
37 client.getData().usingWatcher(watcher).forPath(previousSequencePath);
38 if ( millisToWait != null )
39 {
40 millisToWait -= (System.currentTimeMillis() - startMillis);
41 startMillis = System.currentTimeMillis();
42 //如果设置了获取锁等待时间
43 if ( millisToWait <= 0 )
44 {
45 doDelete = true; // 超时则删除子节点
46 break;
47 }
48 //等待超时时间
49 wait(millisToWait);
50 }
51 else
52 {
53 wait();//一直等待
54 }
55 }
56 catch ( KeeperException.NoNodeException e )
57 {
58 // it has been deleted (i.e. lock released). Try to acquire again
59 //如果前一个子节点已经被删除则deException,只需要自旋获取一次即可
60 }
61 }
62 }
63 }
64 }
65 catch ( Exception e )
66 {
67 ThreadUtils.checkInterrupted(e);
68 doDelete = true;
69 throw e;
70 }
71 finally
72 {
73 if ( doDelete )
74 {
75 deleteOurPath(ourPath);//获取锁超时则删除节点
76 }
77 }
78 return haveTheLock;
79 }
80
释放锁
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
2 {
3 Thread currentThread = Thread.currentThread();
4 LockData lockData = threadData.get(currentThread);
5 //没有获取锁,你释放个球球,如果为空抛出异常
6 if ( lockData == null )
7 {
8 throw new IllegalMonitorStateException("You do not own the lock: " + basePath);
9 }
10 //获取重入数量
11 int newLockCount = lockData.lockCount.decrementAndGet();
12 //如果重入锁次数大于0,直接返回
13 if ( newLockCount > 0 )
14 {
15 return;
16 }
17 //如果重入锁次数小于0,抛出异常
18 if ( newLockCount < 0 )
19 {
20 throw new IllegalMonitorStateException("Lock count has gone negative for lock: " + basePath);
21 }
22 try
23 {
24 //释放锁
25 internals.releaseLock(lockData.lockPath);
26 }
27 finally
28 {
29 //移除当前线程锁数据
30 threadData.remove(currentThread);
31 }
32 }
33
测试案例
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
2 * 基于curator的zookeeper分布式锁
3 */
4public class CuratorUtil {
5 private static String address = "192.168.1.180:2181";
6 public static void main(String[] args) {
7 //1、重试策略:初试时间为1s 重试3次
8 RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
9 //2、通过工厂创建连接
10 CuratorFramework client = CuratorFrameworkFactory.newClient(address, retryPolicy);
11 //3、开启连接
12 client.start();
13 //4 分布式锁
14 final InterProcessMutex mutex = new InterProcessMutex(client, "/curator/lock");
15 //读写锁
16 //InterProcessReadWriteLock readWriteLock = new InterProcessReadWriteLock(client, "/readwriter");
17 ExecutorService fixedThreadPool = Executors.newFixedThreadPool(5);
18 for (int i = 0; i < 5; i++) {
19 fixedThreadPool.submit(new Runnable() {
20 @Override
21 public void run() {
22 boolean flag = false;
23 try {
24 //尝试获取锁,最多等待5秒
25 flag = mutex.acquire(5, TimeUnit.SECONDS);
26 Thread currentThread = Thread.currentThread();
27 if(flag){
28 System.out.println("线程"+currentThread.getId()+"获取锁成功");
29 }else{
30 System.out.println("线程"+currentThread.getId()+"获取锁失败");
31 }
32 //模拟业务逻辑,延时4秒
33 Thread.sleep(4000);
34 } catch (Exception e) {
35 e.printStackTrace();
36 } finally{
37 if(flag){
38 try {
39 mutex.release();
40 } catch (Exception e) {
41 e.printStackTrace();
42 }
43 }
44 }
45 }
46 });
47 }
48 }
49}
50
这里我们开启5个线程,每个线程获取锁的最大等待时间为5秒,为了模拟具体业务场景,方法中设置4秒等待时间。开始执行main方法,通过ZooInspector监控/curator/lock下的节点如下图:
对,没错,设置4秒的业务处理时长就是为了观察生成了几个顺序节点。果然如案例中所述,每个线程都会生成一个节点并且还是有序的。
观察控制台,我们会发现只有两个线程获取锁成功,另外三个线程超时获取锁失败会自动删除节点。线程执行完毕我们刷新一下/curator/lock节点,发现刚才创建的五个子节点已经不存在了。
zookeeper缺点:
使用ZK实现的分布式锁好像完全符合了本文开头我们对一个分布式锁的所有期望。但是,其实并不是,Zookeeper实现的分布式锁其实存在一个缺点,那就是性能上可能并没有缓存服务那么高。因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。ZK中创建和删除节点只能通过Leader服务器来执行,然后将数据同不到所有的Follower机器上。
其实,使用Zookeeper也有可能带来并发问题,只是并不常见而已。考虑这样的情况,由于网络抖动,客户端可ZK集群的session连接断了,那么zk以为客户端挂了,就会删除临时节点,这时候其他客户端就可以获取到分布式锁了。就可能产生并发问题。这个问题不常见是因为zk有重试机制,一旦zk集群检测不到客户端的心跳,就会重试,Curator客户端支持多种重试策略。多次重试之后还不行的话才会删除临时节点。(所以,选择一个合适的重试策略也比较重要,要在锁的粒度和并发之间找一个平衡。)
总结
使用Zookeeper实现分布式锁的优点
- 有效的解决单点问题,不可重入问题,非阻塞问题以及锁无法释放的问题。实现起来较为简单。
使用Zookeeper实现分布式锁的缺点
- 性能上不如使用缓存实现分布式锁。 需要对ZK的原理有所了解。
基于数据库实现分布式锁
基于数据库表
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
创建这样一张数据库表:
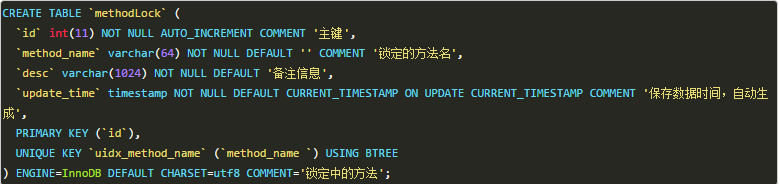
当我们想要锁住某个方法时,执行以下SQL:

因为我们对method_name做了唯一性约束,这里如果有多个请求同时提交到数据库的话,数据库会保证只有一个操作可以成功,那么我们就可以认为操作成功的那个线程获得了该方法的锁,可以执行方法体内容。
当方法执行完毕之后,想要释放锁的话,需要执行以下Sql:

上面这种简单的实现有以下几个问题:
- 这把锁强依赖数据库的可用性,数据库是一个单点,一旦数据库挂掉,会导致业务系统不可用。
- 这把锁没有失效时间,一旦解锁操作失败,就会导致锁记录一直在数据库中,其他线程无法再获得到锁。
- 这把锁只能是非阻塞的,因为数据的insert操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作。
- 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据中数据已经存在了。
当然,我们也可以有其他方式解决上面的问题。
- 数据库是单点?搞两个数据库,数据之前双向同步。一旦挂掉快速切换到备库上。
- 没有失效时间?只要做一个定时任务,每隔一定时间把数据库中的超时数据清理一遍。
- 非阻塞的?搞一个while循环,直到insert成功再返回成功。
- 非重入的?在数据库表中加个字段,记录当前获得锁的机器的主机信息和线程信息,那么下次再获取锁的时候先查询数据库,如果当前机器的主机信息和线程信息在数据库可以查到的话,直接把锁分配给他就可以了。
基于数据库排他锁
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
我们还用刚刚创建的那张数据库表。可以通过数据库的排他锁来实现分布式锁。 基于MySql的InnoDB引擎,可以使用以下方法来实现加锁操作:

在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁(这里再多提一句,InnoDB引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给method_name添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。)。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:

通过connection.commit()操作来释放锁。
这种方法可以有效的解决上面提到的无法释放锁和阻塞锁的问题。
- 阻塞锁? for update语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。
- 锁定之后服务宕机,无法释放?使用这种方式,服务宕机之后数据库会自己把锁释放掉。
- 但是还是无法直接解决数据库单点和可重入问题。
这里还可能存在另外一个问题,虽然我们对method_name 使用了唯一索引,并且显示使用for update来使用行级锁。但是,MySql会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。如果发生这种情况就悲剧了。。。
还有一个问题,就是我们要使用排他锁来进行分布式锁的lock,那么一个排他锁长时间不提交,就会占用数据库连接。一旦类似的连接变得多了,就可能把数据库连接池撑爆
总结
总结一下使用数据库来实现分布式锁的方式,这两种方式都是依赖数据库的一张表,一种是通过表中的记录的存在情况确定当前是否有锁存在,另外一种是通过数据库的排他锁来实现分布式锁。
数据库实现分布式锁的优点
- 直接借助数据库,容易理解。
数据库实现分布式锁的缺点
-
会有各种各样的问题,在解决问题的过程中会使整个方案变得越来越复杂。
-
操作数据库需要一定的开销,性能问题需要考虑。
-
使用数据库的行级锁并不一定靠谱,尤其是当我们的锁表并不大的时候。
三种方案的比较
上面几种方式,哪种方式都无法做到完美。就像CAP一样,在复杂性、可靠性、性能等方面无法同时满足,所以,根据不同的应用场景选择最适合自己的才是王道。
- 从理解的难易程度角度(从低到高)
数据库 > 缓存 > Zookeeper
- 从实现的复杂性角度(从低到高)
Zookeeper >= 缓存 > 数据库
- 从性能角度(从高到低)
缓存 > Zookeeper >= 数据库
- 从可靠性角度(从高到低)
Zookeeper > 缓存 > 数据库
