上篇我们在使用Downward API将Pod的labels 信息 annotations信息过载到Volume这个实例中出现了问题,本节先解决上篇的内容再回头讲解今天的内容。
上篇中,我们mouthPaht指定的目录的是/etc下面的目录,由于docker的容器的目录结构,docker容器是对下层的文件系统有只对权限,但是没有修改权限,所以导致报一些了rootfs的错误。
现在我们将yaml文件修改为这个样子。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2apiVersion: v1
3kind: Pod
4metadata:
5 name: dapi-test-pod-volume
6 labels:
7 zone: us-est-coast
8 cluster: test-cluster
9 rack: rack-22
10 annotations:
11 build: two
12 builder: john-doe
13spec:
14 containers:
15 - name: test-container
16 image: busybox
17 imagePullPolicy: IfNotPresent
18 command: ["/bin/sh","-c"]
19 args:
20 - while true;do
21 if [[ -e /var/labels ]];then
22 echo -en "\n\n";cat /var/labels; fi;
23 if [[ -e /var/annotations ]];then
24 echo -en "\n\n";cat /var/annotations; fi;
25 sleep 60;
26 done;
27 volumeMounts:
28 - name: podinfo
29 mountPath: /var
30 readOnly: false
31
32
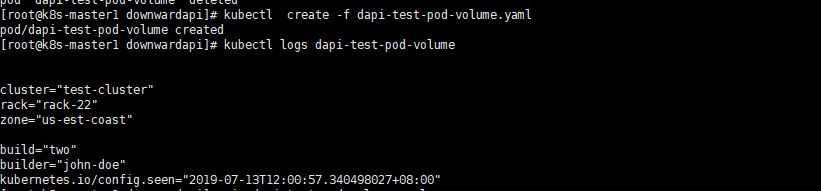
上节的问题我们就说到这里。下面我们回到我们这节的主题。
Pod生命周期和重启策略
Pod在整个生命周期中被系统定义为各种状态,熟悉Pod的各种状态对于理解如何设置Pod的调度策略、重启策略是很有必要的。
Pod的状态表如下所述:
Pending
API Server 已经创建该Pod,但在Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程
Running
Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
Succeeded
Pod内所有容器均成功执行后退出,且不会再重启
Failed
Pod内所有容器均已退出,但至少有一个容器退出为失败状态
Unknown
由于某种原因无法获取该Pod的状态,可能由于网络通信不畅导致。
Pod的重启策略(RestartPolicy)应用于Pod内的所有容器,并且仅在Pod所处的Node上由kubelet进行判断和重启操作。当某个个容器异常退出或者健康检查失败时,kubelet将根据RestartPolicy的设置来进行相应的操作。
Pod的重启策略包括Always、OnFailure和Never,默认值为Always。
◎ Always:当容器失效时,由kubelet自动重启该容器。
◎ OnFailure:当容器终止运行且退出码不为0时,由kubelet自动重启该容器。
◎ Never:不论容器运行状态如何,kubelet都不会重启该容器。
kubelet重启失效容器的时间间隔以sync-frequency乘以2n来计算,例如1、2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
Pod的重启策略与控制方式息息相关,当前可用于管理Pod的控制器包括ReplicationController、Job、DaemonSet及直接通过kubelet管理(静态Pod)。每种控制器对Pod的重启策略要求如下。
◎ RC和DaemonSet:必须设置为Always,需要保证该容器持续运行。
◎ Job:OnFailure或Never,确保容器执行完成后不再重启。
◎ kubelet:在Pod失效时自动重启它,不论将RestartPolicy设置为什么值,也不会对Pod进行健康检查。
结合Pod的状态和重启策略,表3.3列出一些常见的状态转换场景。
| Pod包含的容器数 | Pod当前的状态 | 发生事件 | Pod的结果状态 | ||
| RestarPolicy=Always | RestartPolicy=OnFailure | RestartPolicy=Never | |||
| 包含1个容器 | Running | 容器成功退出 | Running | Succeeded | Succeeded |
| 包含1个容器 | Running | 容器失败退出 | Running | Running | Failed |
| 包含两个容器 | Running | 1个容器失败退出 | Running | Running | Running |
| 包含两个容器 | Running | 容器被OOM杀掉 | Running | Running | Failed |
1 | 1 |
Kubernetes 对 Pod 的健康状态可以通过两类探针来检查:LivenessProbe 和ReadinessProbe,kubelet定期执行这两类探针来诊断容器的健康状况。
(1)LivenessProbe探针:用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet将杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该容器的LivenessProbe探针返回的值永远是Success。
(2)ReadinessProbe探针:用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接收请求。对于被Service管理的Pod,Service与Pod Endpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Read状态的Pod加回后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。
LivenessProbe和ReadinessProbe均可配置以下三种实现方式。
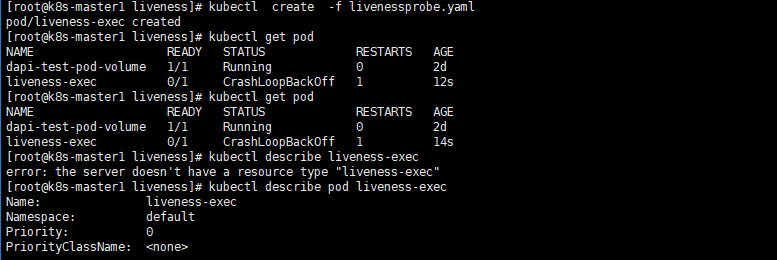
(1)ExecAction: 在容器内部执行一个命令,如果该命令的返回码为0,则表明容器健康。
在下面的例子中,通过执行“cat /tmp/health” 命令来判断一个容器运行是否正常。在该Pod运行后,将在创建/tmp/health文件10s后删除该文件,而LivenessProbe健康检查的初始探测时间(initialDelaySeconds)为15s,探测结果是Fail,将导致kubelet杀掉该容器并重启它:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2kind: Pod
3metadata:
4 labels:
5 test: liveness
6 name: liveness-exec
7spec:
8 containers:
9 - name: liveness
10 image: busybox
11 args:
12 - /bin/sh
13 - c
14 - echo ok > /tmp/health; sleep 10; rm -rf /tmp/health; sleep 600
15 livenessProbe:
16 exec:
17 command:
18 - cat /tmp/health
19 initialDelaySeconds: 15
20 timeoutSeconds: 1
21
22

(2)TCPSocketAction:通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康。
在下面的例子中,通过容器内的localhost:80建立TCP连接进行健康检查:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2kind: Pod
3metadata:
4 name: pod-with-healthcheck
5spec:
6 containers:
7 - name: nginx
8 image: nginx
9 ports:
10 - containerPort: 80
11 livenessProbe:
12 tcpSocket:
13 port: 80
14 initialDelaySeconds: 30
15 timeoutSeconds: 1
16
17

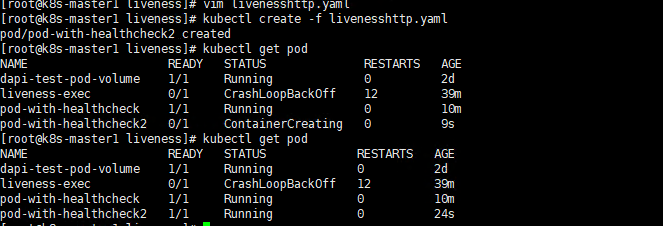
(3)HTTPGetAction: 通过容器的IP地址、端口号及路径调用HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器健康。
在下面的例子中,kubelet定时发送HTTP请求到localhost:80/_status/healthz来进行容器应用的健康检查:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2kind: Pod
3metadata:
4 name: pod-with-healthcheck2
5spec:
6 containers:
7 - name: nginx
8 image: nginx
9 ports:
10 - containerPort: 80
11 livenessProbe:
12 httpGet:
13 path: /_status/healthz
14 port: 80
15 initialDelaySeconds: 30
16 timeoutSeconds: 1
17
18
对于每种探测方法,都需要设置initialDelaySeconds和timeoutSeconds两个参数,它们的含义分别如下。
initialDelaySeconds:启动容器后进行首次健康检查的等待时间,单位为s
timeoutSeconds: 健康坚持发送请求后等待响应的超时时间,单位为s。当超时发生时,kubelet会认为容器已经无法提供服务,将会重启该容器。
k8s的ReadinessProbe机制无法满足某些复杂应用对容器内服务可用状态的判断,所以k8s引入Pod Ready++特性对Readiness探测机制进行扩展。
通过Pod Readiness Gates机制,用户可以将自动以的ReadinessProbe探测方式设置在Pod上,辅助k8s设置Pod何时达到服务可用状态(Ready)。为了使自动以的ReadinessProbe生效,用户提供一个外部的控制器(Controller)来设置相应的Condition状态。
Pod的Readiness Gates 在Pod定义中的ReadinessGate字段进行设置。下面的例子设置了一个类型为www.example.com/feature-1的Readiness Gate:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2.....
3spec:
4 readinessGates:
5 - conditionType: "www.example.com/feature-1"
6status:
7 conditions:
8 - type: Ready # Kubernetes系统内置的名为Ready的Condition
9 status: "True"
10 lastProbeTime: null
11 lastTransitionTime: 2019-03-15T00:00:00Z
12 - type: "wwww.example.com/feature-1"
13 status: "False"
14 lastProbeTime: null
15 lastTransitionTime: 2019-07-15T00:00:00Z
16 containerStatuses:
17 - containerID: docker://abcd..
18 ready: true
19.....
20
新增的自定义Condition的状态(status)将由用户自定义的外部控制器设置,默认值为False。Kubernetes将在判断全部readinessGates条件都为True时,才设置Pod为服务可用状态。
