近几天家里出了些事情,所以耽搁了更新的进度,希望大家可以谅解。
Job: 批处理调度
Kubernetes从1.2版本开始支持批处理类型的应用,我们可以通过Kubernetes Job资源对象来定义并启动一个批处理任务。批处理任务通常并行(或者串行)启动多个计算进(work item),处理完成后,整个批处理任务结束。按照批处理任务实现方式的不同,批处理任务可以分为以下的几种模式。
◎ Job Template Expansion模式:一个Job对象对应一个待处理的Work item,有几个Work item就产生几个独立的Job,通常适合Work item数量少、每个Work item要处理的数据量比较大的场景,比如有一个100GB的文件作为一个Work item,总共有10个文件需要处理。
◎ Queue with Pod Per Work Item模式:采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,在这种模式下,Job会启动N个Pod,每个Pod都对应一个Work item。
◎ Queue with Variable Pod Count模式:也是采用一个任务队列存放Work item,一个Job对象作为消费者去完成这些Work item,但与上面的模式不同,Job启动的Pod数量是可变的。
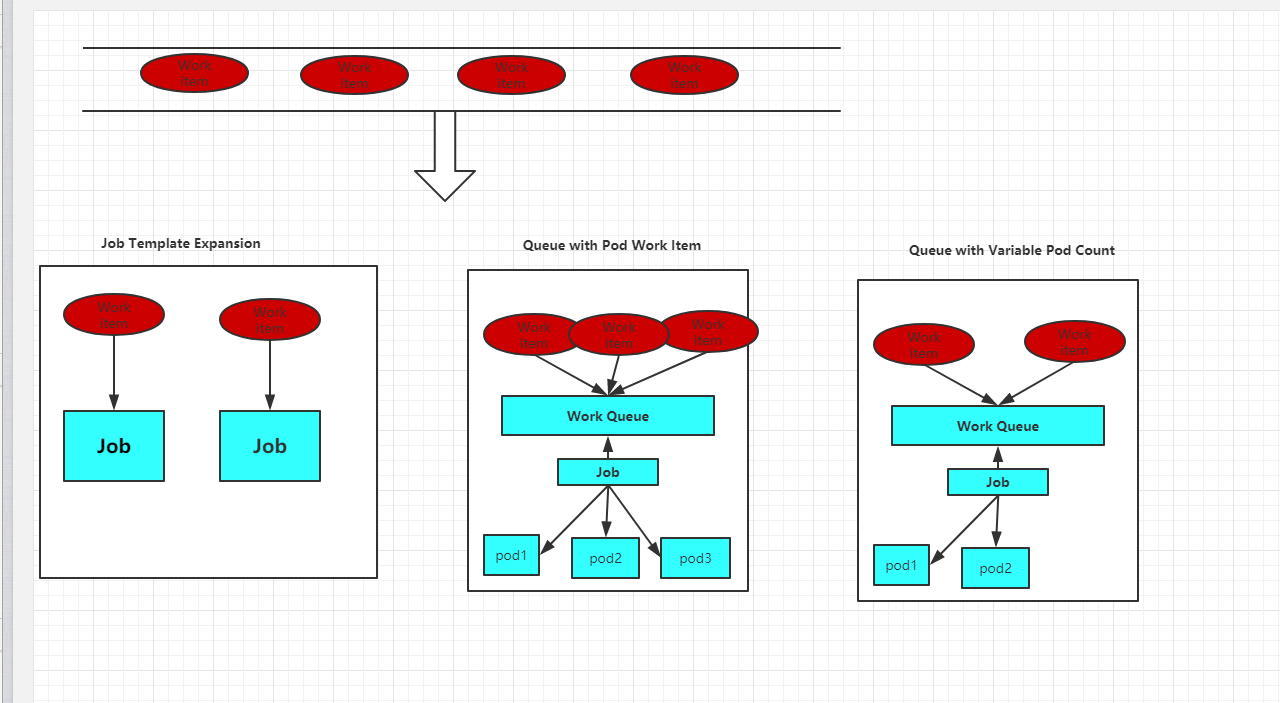
还有一种被称为Single Job with Static Work Assignment的模式,也是一个Job产生多个Pod,但它采用程序静态方式分配任务项,而不是采用队列模式进行动态分配。
以下是几种模式的一个对比表:
Job Template Expansion
/
/
是
是
Qucue with Pod Per Work Item
是
/
有时候需要
是
Qucue with Variable Pod Count
是
/
/
是
Single Job with Work Assignment
是
/
是
/
考虑到批处理的并行问题,Kubernetes将Job分以下三种类型。
1.Non-parallel Jobs
通常一个Job只启动一个Pod,除非Pod异常,才会重启该Pod,一旦此Pod正常结束,Job将结束。
2.Parallel Jobs with a fixed completion count
并行Job会启动多个Pod,此时需要设定Job的.spec.completions参数为一个正数,当正常结束的Pod数量达至此参数设定的值后,Job结束。此外,Job的.spec.parallelism参数用来控制并行度,即同时启动几个Job来处理Work Item。
3.Parallel Jobs with a work queue
任务队列方式的并行Job需要一个独立的Queue,Work item都在一个Queue中存放,不能设置Job的.spec.completions参数,此时Job有以下特性。
◎ 每个Pod都能独立判断和决定是否还有任务项需要处理。
◎ 如果某个Pod正常结束,则Job不会再启动新的Pod。
◎ 如果一个Pod成功结束,则此时应该不存在其他Pod还在工作的情况,它们应该都处于即将结束、退出的状态。
◎ 如果所有Pod都结束了,且至少有一个Pod成功结束,则整个Job成功结束。
首先是Job Template Expansion模式,由于在这种模式下每个Work item对应一个Job实例,所以这种模式首先定义一个Job模板,模板里的主要参数是Work item的标识,因为每个Job都处理不同的Work item。如下所示的Job模板(文件名为job.yaml.txt)中的$ITEM可以作为任务项的标识:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2kind: Pod
3metadata:
4 name: process-item-$ITEM
5 labels:
6 jobgroup: jobexample
7spec:
8 template:
9 metadata:
10 name: jobexample
11 labels:
12 jobgroup: jobexample
13 spec:
14 containers:
15 - name: c
16 image: busybox
17 commadn: ["sh", "-c", "echo Processing item $ITEM && sleep 5"]
18 restartPolicy: Never
19
生成三个job.yaml
2
2
2
3
4
2
3kubectl get jobs
4

PS:k8s1.14 JOB属于那本版本呢?解决这个问题,可以联系博主哦。谢谢了。
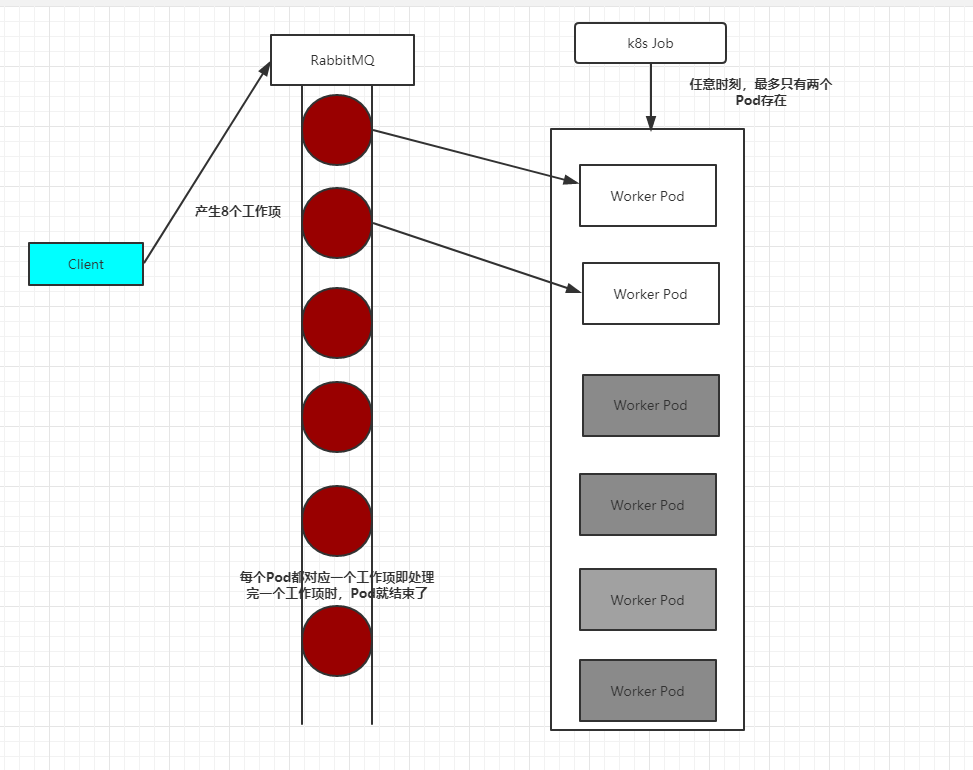
其次,我们看看Queue with Pod Per Work Item模式,在这种模式下需要一个任务队列存放Work item,比如RabbitMQ,客户端程序先把要处理的任务变成Work item放入任务队列,然后编写Worker程序、打包镜像并定义成为Job中的Work Pod。Worker程序的实现逻辑是从任务队列中拉取一个Work item并处理,在处理完成后即结束进程。并行度为2的Demo示意图如图
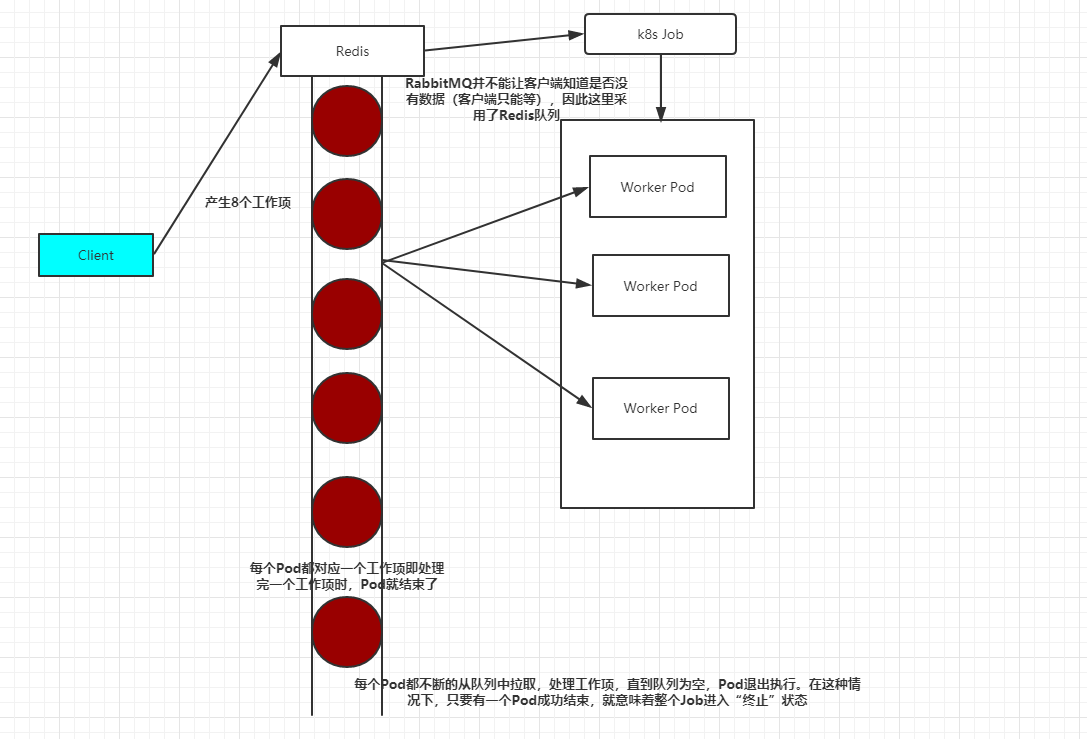
最后,我们看看Queue with Variable Pod Count模式,如图3.6所示。由于这种模式下,Worker程序需要知道队列中是否还有等待处理的Work item,如果有就取出来处理,否则就认为所有工作完成并结束进程,所以任务队列通常要采用Redis或者数据库来实现。
CronJob:定时任务
Kubernetes从1.5版本开始增加了一种新类型的Job,即类似Linux Cron的定时任务Cron Job,下面看看如何定义和使用这种类型的Job。
首先,确保Kubernetes的版本为1.8及以上。
其次,需要掌握Cron Job的定时表达式,它基本上照搬了Linux Cron的表达式,区别是第1位是分钟而不是秒,格式如下:
2
2
其中每个域都可出现的字符如下。
◎ Minutes:可出现“,”“-”“*”“/”这4个字符,有效范围为0~59的整数。
◎ Hours:可出现“,”“-”“*”“/”这4个字符,有效范围为0~23的整数。
◎ DayofMonth:可出现“,”“-”“*”“/”“?”“L”“W”“C”这8个字符,有效范围为0~31的整数。
◎ Month:可出现“,”“-”“*”“/”这4个字符,有效范围为1~12的整数或JAN~DEC。
◎ DayofWeek:可出现“,”“-”“*”“/”“?”“L”“C”“#”这8个字符,有效范围为1~7的整数或SUN~SAT。1表示星期天,2表示星期一,以此类推。
表达式中的特殊字符“*”与“/”的含义如下。
◎ *:表示匹配该域的任意值,假如在Minutes域使用“*”,则表示每分钟都会触发事件。
◎ /:表示从起始时间开始触发,然后每隔固定时间触发一次,例如在Minutes域设置为5/20,则意味着第1次触发在第5min时,接下来每20min触发一次,将在第25min、第45min等时刻分别触发。
比如,我们要每隔1min执行一次任务,则Cron表达式如下:
2
2
Cron Job的配置文件格式如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2kind: CronJob
3metadata:
4 name: hello
5spec:
6 schedule: "*/1 * * * *"
7 jobTemplate:
8 spec:
9 template:
10 spec:
11 containers:
12 - name: hello
13 image: busybox
14 args:
15 - /bin/sh
16 - -c
17 - date; echo Hello from the Kubernetes cluster
18 restartPolicy: OnFailure
19
该例子定义了一个名为hello的Cron Job,任务每隔1min执行一次,运行的镜像是busybox,执行的命令是Shell脚本,脚本执行时会在控制台输出当前时间和字符串“Hello from the Kubernetes cluster”。

还是同样的错误,需要k8s1.8以上。
然后每隔1min执行kubectl get cronjob hello查看任务状态,发现的确每分钟调度了一次:
2
2
下面的命令,可以更直观地了解Cron Job定期触发任务执行的历史和现状:
2
2
当不需要某个Cron Job时,可以通过下面的命令删除它:
2
2
在Kubernetes 1.9版本后,kubectrl命令增加了别名cj来表示cronjob,同时kubectl set image/env命令也可以作用在CronJob对象上了。
自定义调度器
如果Kubernetes调度器的众多特性还无法满足我们的独特调度需求,则还可以用自己开发的调度器进行调度。从1.6版本开始,Kubernetes的多调度器特性也进入了快速发展阶段。
一般情况下,每个新Pod都会由默认的调度器进行调度。但是如果在Pod中提供了自定义的调度器名称,那么默认的调度器会忽略该Pod,转由指定的调度器完成Pod的调度。
在下面的例子中为Pod指定了一个名为my-scheduler的自定义调度器:
2
3
4
5
6
7
8
9
10
11
12
2kind: Pod
3metadata:
4 name: nginx
5 labels:
6 app: nginx
7spec:
8 shedulerName: my-sheduler
9 containers:
10 - name: nginx
11 image: nginx
12
如果自定义的调度器还未在系统中部署,则默认的调度器会忽略这个Pod,这个Pod将会永远处于Pending状态。
下面看看如何创建一个自定义的调度器。
可以用任何语言来实现简单或复杂的自定义调度器。下面的简单例子使用Bash脚本进行实现,调度策略为随机选择一个Node(注意,这个调度器需要通过kubectl proxy来运行):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2SERVER='localhost:8001'
3while true;
4do
5 for PODNAME in $(kubectl --server $SERVER get pods -o json | jq '.items[] | select(.spec.schedulerName == "my-scheduler") | select(.spec.nodeName == null) | .metadata.name' | tr -d '"');
6 do
7 NODES=($(kubectl --server $SERVER get nodes -o json | jq '.items[].metadata.name' | tr -d '"'))
8 NUMNODES=${#NODES[@]}
9 CHOSEN=${NODES[$[ $RANDOM % $NUMNODES ]]}
10 curl --header "Content-Type:application/json" --request POST --data '{"apiVersion":"v1", "kind": "Binding", "metadata": {"name": "'$PODNAME'"}, "target": {"apiVersion": "v1", "kind"
11: "Node", "name": "'$CHOSEN'"}}' http://$SERVER/api/v1/namespaces/default/pods/$PODNAME/binding/
12 echo "Assigned $PODNAME to $CHOSEN"
13 done
14 sleep 1
15done
16
17
一旦这个自定义调度器成功启动,前面的Pod就会被正确调度到某个Node上。
小结:
由于k8s版本问题,导致我们今天的很多实例都失败了,后续我们会对版本升级,解决这些问题。这里只是让大家有个概念,能看到yaml文件,知道Job是做什么的。
谢谢大家的支持、
