在Kubernetes集群环境中,一个完整的应用或服务都会涉及为数众多的组件运行,各组件所在的Node及实例数量都是可变的。日志子系统如果不做集中化管理,则会给系统的运维支撑造成很大的困难,因此有必要在集群层面对日志进行统一收集和检索等工作。
在容器中输出到控制台的日志,都会以*-json.log的命名方式保存在/var/lib/docker/containers/目录下,这就为日志采集和后续处理奠定了基础。
Kubernetes推荐采用Fluentd+Elasticsearch+Kibana完成对系统和容器日志的采集、查询和展现工作。
部署统一的日志管理系统,需要以下两个前提条件。
◎ API Server正确配置了CA证书。
◎ DNS服务启动、运行。
系统部署架构
该系统的逻辑架构如下图:
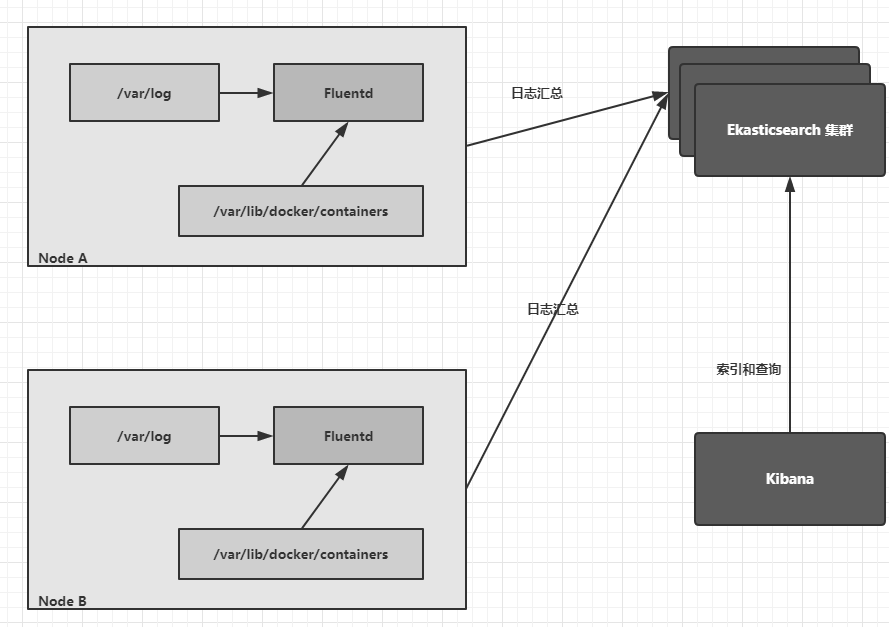
在各Node上都运行了一个Fluentd容器,采集本节点/var/log和/var/lib/docker/containers两个目录下的日志进程,将其汇总到Elasticsearch集群,最终通过Kibana完成和用户的交互工作。
这里有一个特殊的需求:Fluentd必须在每个Node上运行,为了满足这一需求,我们通过下面几种方式部署Fluentd。
◎ 直接在Node主机上部署Fluentd。
◎ 利用kubelet的–config参数,为每个Node都加载Fluentd Pod。
◎ 利用DaemonSet让Fluentd Pod在每个Node上运行。
创建Elasticsearch RC和Service
Elasticsearch的RC和Service定义如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
2apiVersion: v1
3kind: ReplicationController
4metadata:
5 name: elasticsearch-logging-v1
6 namespace: kube-system
7 labels:
8 k8s-app: elasticsearch-logging
9 version: v1
10 kubernetes.io/cluster-service: "true"
11spec:
12 replicas: 2
13 selector:
14 k8s-app: elasticsearch-logging
15 version: v1
16 template:
17 metadata:
18 labels:
19 k8s-app: elasticsearch-logging
20 version: v1
21 kubernetes.io/cluster-service: "true"
22 spec:
23 containers:
24 - image: gcr.io/google_containers/elasticsearch:1.8
25 name: elasticsearch-logging
26 resources:
27 # keep request = limit to keep this container in guaranteed class
28 limits:
29 cpu: 100m
30 requests:
31 cpu: 100m
32 ports:
33 - containerPort: 9200
34 name: db
35 protocol: TCP
36 - containerPort: 9300
37 name: transport
38 protocol: TCP
39 volumeMounts:
40 - name: es-persistent-storage
41 mountPath: /data
42 volumes:
43 - name: es-persistent-storage
44 emptyDir: {}
45---
46apiVersion: v1
47kind: Service
48metadata:
49 name: elasticsearch-logging
50 namespace: kube-system
51 labels:
52 k8s-app: elasticsearch-logging
53 kubernetes.io/cluster-service: "true"
54 kubernetes.io/name: "Elasticsearch"
55spec:
56 ports:
57 - port: 9200
58 protocol: TCP
59 targetPort: db
60 selector:
61 k8s-app: elasticsearch-logging
62
执行kubectl create -f elastic-search.yml命令完成创建。
在命令成功执行后,首先验证Pod的运行情况。通过kubectl get pods–namespaces=kube-system获取运行中的Pod。
接下来通过Elasticsearch页面验证其功能。
首先,执行# kubectl cluster-info命令获取Elasticsearch服务的地址。
然后,使用# kubectl proxy命令对API Server进行代理,在成功执行后输出如下内容:
这样就可以在浏览器上访问URL地址https://20.0.40.51:12567/api/v1/namespaces/kube-system/services/elasticsearch-logging/proxy,来验证Elasticsearch的运行情况了,返回的内容是一个JSON文档。
在每个Node上启动Fluentd
Fluentd的DaemonSet定义如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
2kind: DaemonSet
3metadata:
4 name: fluentd-cloud-logging
5 namespace: kube-system
6 labels:
7 k8s-app: fluentd-cloud-logging
8spec:
9 template:
10 metadata:
11 namespace: kube-system
12 labels:
13 k8s-app: fluentd-cloud-logging
14 spec:
15 containers:
16 - name: fluentd-cloud-logging
17 image: gcr.io/google_containers/fluentd-elasticsearch:1.17
18 resources:
19 limits:
20 cpu: 100m
21 memory: 200Mi
22 env:
23 - name: FLUENTD_ARGS
24 value: -q
25 volumeMounts:
26 - name: varlog
27 mountPath: /var/log
28 readOnly: false
29 - name: containers
30 mountPath: /var/lib/docker/containers
31 readOnly: false
32 volumes:
33 - name: containers
34 hostPath:
35 path: /var/lib/docker/containers
36 - name: varlog
37 hostPath:
38 path: /var/log
39
40
通过kubectl create命令创建Fluentd容器:
查看创建的结果:
结果显示Fluentd DaemonSet正常运行,还启动了3个Pod,与集群中的Node数量一致。
接下来使用# kubectl logs fluentd-cloud-logging-7tw9z命令查看Pod的日志,在Elasticsearch正常工作的情况下,我们会看到类似下面这样的日志内容:
2
3
4
5
2
3 Connection opened to Elasticsearch cluster =>
4{:host => "elasticsearch-logging", :port=>9200, :scheme=>"http"}
5
运行Kibana
至此已经运行了Elasticsearch和Fluentd,数据的采集和汇聚已经完成,接下来使用Kibana展示和操作数据。
Kibana的RC和Service定义如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
2apiVersion: v1
3kind: ReplicationController
4metadata:
5 name: kibana-logging-v1
6 namespace: kube-system
7 labels:
8 k8s-app: kibana-logging
9 version: v1
10 kubernetes.io/cluster-service: "true"
11spec:
12 replicas: 1
13 selector:
14 k8s-app: kibana-logging
15 version: v1
16 template:
17 metadata:
18 labels:
19 k8s-app: kibana-logging
20 version: v1
21 kubernetes.io/cluster-service: "true"
22 spec:
23 containers:
24 - name: kibana-logging
25 image: gcr.io/google_containers/kibana:1.3
26 resources:
27 # keep request = limit to keep this container in guaranteed class
28 limits:
29 cpu: 100m
30 requests:
31 cpu: 100m
32 env:
33 - name: "ELASTICSEARCH_URL"
34 value: "http://elasticsearch-logging:9200"
35 ports:
36 - containerPort: 5601
37 name: ui
38 protocol: TCP
39---
40apiVersion: v1
41kind: Service
42metadata:
43 name: kibana-logging
44 namespace: kube-system
45 labels:
46 k8s-app: kibana-logging
47 kubernetes.io/cluster-service: "true"
48 kubernetes.io/name: "Kibana"
49spec:
50 ports:
51 - port: 5601
52 protocol: TCP
53 targetPort: ui
54 selector:
55 k8s-app: kibana-logging
56
通过kubectl create -f kibana-rc-svc.yml命令创建Kibana的RC和Service。
查看Kibana的运行情况。
结果表明运行均已成功。通过kubectl cluster-info命令获取Kibana服务的URL地址。
同样通过kubectl proxy命令启动代理,在出现“Starting to serve on 127.0.0.1:8001”字样之后,用浏览器访问URL地址http://ip:port/api/v1/proxy/namespaces/kube-system/services/kibana-logging即可访问Kibana页面。
第1次进入页面时需要进行一些设置,选择所需选项后单击create按钮。
然后单击discover按钮,就可以正常查询日志了。
在搜索栏输入“error”关键字,可以搜索出包含该关键字的日志记录。
同时,通过左边菜单中Fields相关的内容对查询的内容进行限定。
至此,Kubernetes集群范围内的统一日志收集和查询系统就搭建完成了。
Kubernetes的审计机制
Kubernetes为了加强对集群操作的安全监管,从1.4版本开始引入审计机制,主要体现为审计日志(Audit Log)。审计日志按照时间顺序记录了与安全相关的各种事件,这些事件有助于系统管理员快速、集中了解以下问题:
◎ 发生了什么事情?
◎ 作用于什么对象?
◎ 在什么时间发生?
◎ 谁(从哪儿)触发的?
◎ 在哪儿观察到的?
◎ 活动的后继处理行为是怎样的?
下面是两条Pod操作的审计日志示例。
第一条:

第二条:

API Server把客户端的请求(Request)的处理流程视为一个“链条”,这个链条上的每个“节点”就是一个状态(Stage),从开始到结束的所有Request Stage如下。
◎ RequestReceived:在Audit Handler收到请求后生成的状态。
◎ ResponseStarted:响应的Header已经发送但Body还没有发送的状态,仅对长期运行的请求(Long-running Requests)有效,例如Watch。
◎ ResponseComplete:Body已经发送完成。
◎ Panic:严重错误(Panic)发生时的状态。
Kubernets从1.7版本开始引入高级审计特性(AdvancedAuditing),可以自定义审计策略(选择记录哪些事件)和审计存储后端(日志和Webhook)等,开启方法为增加kube-apiserver的启动参数–feature-gates=AdvancedAuditing=true。注意:在开启AdvancedAuditing后,日志的格式有一些修改,例如新增了上述Stage信息;从Kubernets 1.8版本开始,该参数默认为true。
kube-apiserver在收到一个请求后(如创建Pod的请求),会根据Audit Policy(审计策略)对此请求做出相应的处理。
我们可以将Audit Policy视作一组规则,这组规则定义了有哪些事件及数据需要记录(审计)。当一个事件被处理时,规则列表会依次尝试匹配该事件,第1个匹配的规则会决定审计日志的级别(Audit Level),目前定义的几种级别如下(按级别从低到高排列)。
◎ None:不生成审计日志。
◎ Metadata:只记录Request请求的元数据如requesting user、timestamp、resource、verb等,但不记录请求及响应的具体内容。
◎ Request:记录Request请求的元数据及请求的具体内容。
◎ RequestResponse:记录事件的元数据,以及请求与应答的具体内容。
None以上的级别会生成相应的审计日志并将审计日志输出到后端,当前的后端实现如下。
(1)Log backend:以本地日志文件记录保存,为JSON日志格式,我们需要对API Server的启动命令设置下列参数。
◎ –audit-log-path:指定日志文件的保存路径。
◎ –audit-log-maxage:设定审计日志文件保留的最大天数。
◎ –audit-log-maxbackup:设定审计日志文件最多保留多少个。
◎ –audit-log-maxsize:设定审计日志文件的单个大小,单位为MB,默认为100MB。
审计日志文件以audit-log-maxsize设置的大小为单位,在写满后,kube-apiserver将以时间戳重命名原文件,然后继续写入audit-log-path指定的审计日志文件;audit-log-maxbackup和audit-log-maxage参数则用于kube-apiserver自动删除旧的审计日志文件。
(2)Webhook backend:回调外部接口进行通知,审计日志以JSON格式发送(POST方式)给Webhook Server,支持batch和blocking这两种通知模式,相关配置参数如下。
◎ –audit-webhook-config-file:指定Webhook backend的配置文件。
◎ –audit-webhook-mode:确定采用哪种模式回调通知。
◎ –audit-webhook-initial-backoff:指定回调失败后第1次重试的等待时间,后继重试等待时间则呈指数级递增。
Webhook backend的配置文件采用了kubeconfig格式,主要内容包括远程审计服务的地址和相关鉴权参数,配置示例如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
2clusters:
3 - name: name-of-remote-audit-service
4 cluster:
5 certificate-authority: /path/to/ca.pem # CA for verifying the remote service.
6 server: https://audit.example.com/audit # URL of remote service to query. Must use 'https'.
7
8# users refers to the API server's webhook configuration.
9users:
10 - name: name-of-api-server
11 user:
12 client-certificate: /path/to/cert.pem # cert for the webhook plugin to use
13 client-key: /path/to/key.pem # key matching the cert
14
15# kubeconfig files require a context. Provide one for the API server.
16current-context: webhook
17contexts:
18- context:
19 cluster: name-of-remote-audit-service
20 user: name-of-api-sever
21 name: webhook
22
–audit-webhook-mode则包括以下选项。
◎ batch:批量模式,缓存事件并以异步批量方式通知,是默认的工作模式。
◎ blocking:阻塞模式,事件按顺序逐个处理,这种模式会阻塞API Server的响应,可能导致性能问题。
◎ blocking-strict:与阻塞模式类似,不同的是当一个Request在RequestReceived阶段发生审计失败时,整个Request请求会被认为失败。
(3)Batching Dynamic backend:一种动态配置的Webhook backend,是通过AuditSink API 动态配置的,在Kubernetes 1.13版本中引入。
需要注意的是,开启审计功能会增加API Server的内存消耗量,因为此时需要额外的内存来存储每个请求的审计上下文数据,而增加的内存量与审计功能的配置有关,比如更详细的审计日志所需的内存更多。我们可以通过kube-apiserver中的–audit-policy-file参数指定一个Audit Policy文件名来开启API Server的审计功能。
通常审计日志可以以本地日志文件方式保存,然后使用Fluentd作为Agent采集该日志并存储到Elasticsearch,用Kibana等UI界面对日志进行展示和查询。
小结: 今天的内容到此结束
谢谢大家的浏览。
