一、自旋锁概述
- 如果每个临界区都能像增加变量这样简单就好了,可惜现实总是残酷的。现实世界里,临界区甚至可以跨越多个函数。举个例子,我们经常会碰到这种情况:先得从一个数据结构中移出 数据,对其进行格式转换和解析,最后再把它加入到另一个数据结构中。整个执行过程必须是原子的,在数据被更新完毕前,不能有其他代码读取这些数据。显然,
简单的原子操作对此无能为力,这就需要使用更为复杂的同步方法——锁来提供保护
-
Linux内核中最常见的锁是自旋锁(spin lock)。自旋锁最多只能被一个可执行线程持有:
-
如果一个执行线程试图获得一个被已经持有(即所谓的争用)的自旋锁,那么该线程就会一直进行忙循环一旋转一等待锁重新可用
- 要是锁未被争用,请求锁的执行线程便能立刻得到它,继续执行
-
在任意时间,
自旋锁都可以防止多于一个的执行线程同时进入临界区。同一个锁可以用在多个位置,例如,对于给定数据的所有访问都可以得到保护和同步
自旋与非自旋
自旋锁:
一个被争用的自旋锁使得请求它的线程在等待锁重新可用时自旋(特別浪费处理器时间),这种行为是自旋锁的要点。所以自旋锁不应该被长时间持有。事实上,这点正是使用自旋锁的初衷:在短期间内进行轻量级加锁
非自旋锁:
还可以采取另外的方式来处理对锁的争用:让请求线程睡眠,直到锁重新可用时再唤醒它。这样处理器就不必循环等待,可以去执行其他代码
- 这也会带来一 定的开销——这里有两次明显的上下文切换,被阻塞的线程要换出和换入,与实现自旋锁的少数 几行代码相比,上下文切换当然有较多的代码。因此,持有自旋锁的时间最好小于完成两次上下文切换的耗时。当然我们大多数人都不会无聊到去测量上下文切换的耗时,所以我们让持有自旋锁的时间应尽可能的短就可以了
后面的内容中我们将讨论信号最,便提供了上述第二种锁机制,它使得在发生争用时,等待的线程能投入睡眠,而不是旋转
二、自旋锁方法
- 自旋锁的实现和体系结构密切相关,
代码往往通过汇编实现。这些与体系结构
相关的代码定义在文件<asm/spinlock.h>中,实际需要用到的
接口定义在文件<linux/spinlock.h>中
- 自旋锁的基本使用形式如下:

- 因为自旋锁在同一时刻至多被一个执行线程持有,所以
一个时刻只能有一个线程位于临界区内,这就为多处理器机器提供了防止并发访问所需的保护机制。注意
在单处理器机器上,编译的时候并不会加入自旋锁。它仅仅被当做一个设置内核抢占机制是否被启用的开关。如果禁止内核抢占,那么在编译时自旋锁会被完全剔除出内核
警告:自旋锁是不可递归的
- Linux内核实现的自旋锁是不可递归的,这点不同于自旋锁在其他操作系统中的实现。所以如果你试图得到一个你正持有的锁,你必须自旋,等待你自己释放这个锁。但你处于自旋忙等待中,所以你永远没有机会释放锁,于是你被自己锁死了。千万小心自旋锁
自旋锁在中断处理程序中的应用
- 自旋锁可以使用在中断处理程序中(此处不能使用信号量,因为它们会导致睡眠)。在
中断处理程序中使用自旋锁时,一定要在获取锁之前,首先禁止本地中断(在当前处理器上的中断请求),否则,中断处理程序就会打断正持有锁的内核代码,有可能会试图去争用这个已经被持有的自旋锁。这样一来,中断处理程序就会自旋,等待该锁重新可用,但是锁的持有者在这个中断处理程序执行完毕前不可能运行。这正是我们在前面的内容中提到的双重请求死锁。注意,需要关闭的只是当前处理器上的中断。如果中断发生在不同的处理器上,即使中断处理程序在同一锁上自旋,也不会妨碍锁的持有者(在不同处理器上)最终释放锁
**内核提供的禁止中断同时请求锁的接口,**使用起来很方便,方法如下:
spin_lock_irqsave():此函数保存中断的当前状态,并禁止本地中断,然后再去获取指定的锁
spin_unlock_irqrestore():对指定的锁解锁,然后让中断恢复到加锁前的状态
所以即使中断最初是禁止的,代码也不会错误地激活它们,相反,会继续让它们禁止
flags变量看起来像是由数值传递的,这是因为这些锁函数有些部分是通过宏的方式实现的
- 在单处理器系统上,虽然在编译时抛弃掉了锁机制,但在上面例子中仍需要关闭中断,以禁止中断处理程序访问共享数据。加锁和解锁分别可以禁止和允许内核抢占
锁什么?
- 使用锁的时候一定要对症下药,要有针对性。要知道
需要保护的是数据而不是代码。尽管本章的例子讲的都是保护临界区的重要性,但是真正保护的其实是临界区中的数据,而不是代码
大原则:针对代码加锁会使得程序难以理解,并且容易引发竞争条件,正确的做法应该是对数据而不是代码加锁
既然不是对代码加锁,那就一定要用特定的锁来保护自己的共享数据。例如,“struct foo由loo_lock加锁”。无论你何时需要访问共享数据,一定要先保证数据是安全的。而保证数据安全往往就意味着在对数据进行操作前,首先占用恰当的锁,完成操作后再释放它
如果你能确定中断在加锁前是激活的,那就不需要在解锁后恢复中断以前的状态了。你可以无条件地在解锁时激活中断。这时,使用ppin_lock_irq()和spin_unlock_irq()会更好一些
- 由于内核变得庞大而复杂,因此,在内核的执行路线上,你很难搞清楚中断在当前调用点上 到底是不是处于激活状态。也正因为如此,我们并不提倡使用spin_lock_irq()方法。如果你一定要使用它,那你应该确定中断原来就处于激活状态,否则当其他人期望中断处于未激活状态时却发现处于激活状态,可能会非常不开心
调试自旋锁
- 配置选项CONFIG_DEBUG_SPINLOCK为使用自旋锁的代码加入了许多调试检测手段。 例如,激活了该选项,内核就会检査是否使用了未初始化的锁,是否在还没加锁的时候就要对锁执行开锁操作。在测试代码时,总是应该激活这个选项。如果需要进一步全程调试锁,还应该打开CONFIG_DEBUG_LOCK_ALLOC选项


三、其他针对自旋锁的操作
- 你可以使用spin_lock_init()方法来初始化动态创建的自旋锁(此时你只有一个指向spinlock_t类型的指针,没有它的实体)
- spin_try_lock()试图获得某个特定的自旋锁,如果该锁已经被争用,那么该方法会立刻返回一个非0值,而不会自旋等待锁被释放;如果成功地获得了这个自旋锁,该函数返回0。同理,spin_is_locked()方法用于检査特定的锁当前是否已被占用,如果已被占用,返回非0值 ;否则返回0。该方法只做判断,并不实际占用
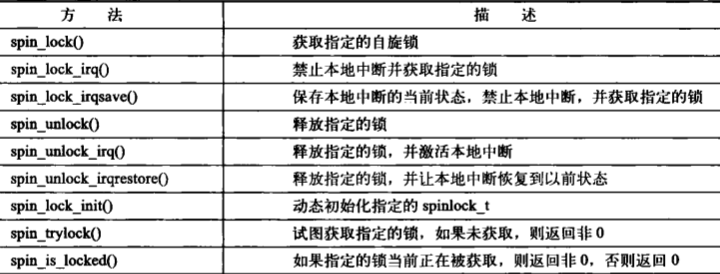
- 下图给出了标准的自旋锁操作的完整列表
四、自旋锁和下半部
- 在前面文章中曾经提到,在与下半部配合使用时,必须小心地使用锁机制。函数spin_lock_bh()用于获取指定锁,同时它会禁止所有下半部的执行。相应的spin_unlock_bh()函数执行相反的操作
- 由于下半部可以抢占进程上下文中的代码,所以当下半部和进程上下文共享数据时
,必须对进程上下文中的共享数据进行保护,所以需要加锁的同时还要禁止下半部执行。同样,由于中断处理程序可以抢占下半部,所以如果中断处理程序和下半部共享数据,那么就必须在获取恰当的锁的同时还要禁止中断
- 回忆一下,
同类的tasklet不可能同时运行,所以对于同类tasklet中的共享数据不需要保护。 但是当数据被两个不同种类的tasklet共享时,就需要在访问下半部中的数据前先获得一个普通的自旋锁。这里不需要禁止下半部,因为在同一个处理器上绝不会有tasklet相互强占的情况
- 对于软中断,无论是否同种类型,如果数据被软中断共享,那么它必须得到锁的保护。这是因为,即使是同种类型的两个软中断也可以同时运行在一个系统的多个处理器上。但是,同一处理器上的一个软中断绝不会抢占另一个软中断,因此,根本没必要禁止下半部
五、读写自旋锁
- 有时,锁的用途可以明确地分为读取和写入两个场景。例如,对一个链表可能既要更新又要检索。当更新(写入)链表时,不能有其他代码并发地写链表或从链表中读取数据,写操作要求完全互斥。另一方面,当对去检索(读取)链表时,只要其他程序不对链表进行写操作就行了。 只要没有写操作,多个并发的读操作都是安全的。任务链表的存取模式就非常类似于这种情况,它就是通过读写自旋锁获得保护的
- 读/写自旋锁的使用方法类似于普通自旋锁,它们通过下面的方法初始化:

- 然后,在读者的代码分支中使用如下函数:

- 最后,在写者的代码分支中使用如下函数:

- 通常情况下,读锁和写锁会位干完全分割开的代码分支中,如上例所示
- 注意,不能把一个读锁“升级”为写锁。比如考虑下面这段代码:
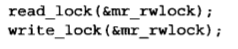
- 执行上述两个函数将会带来死锁,因为写锁会不断自旋,等待所有的读者释放锁,其中也 包括它自己。所以当确实需要写操作时,要在一开始就请求写锁。如果写和读不能清晰地分开的 话,那么使用一般的自旋锁就行了,不要使用读写自旋锁
- 多个读者可以安全地获得同一个读锁,事实上,即使一个线程递归地获得同一读锁也是安 全的。这个特性使得读写自旋锁真正成为一种有用并且常用的优化手段。如果在中断处理程 序中只有读操作而没有写操作,那么,就可以混合使用“中断禁止”锁,使用read_lock()而不是read_lock_irqsave()对读进行保护。不过,你还是需要用write_lock_irqsave()禁止有写操作的中断,否则,中断里的读操作就有可能锁死在写锁上
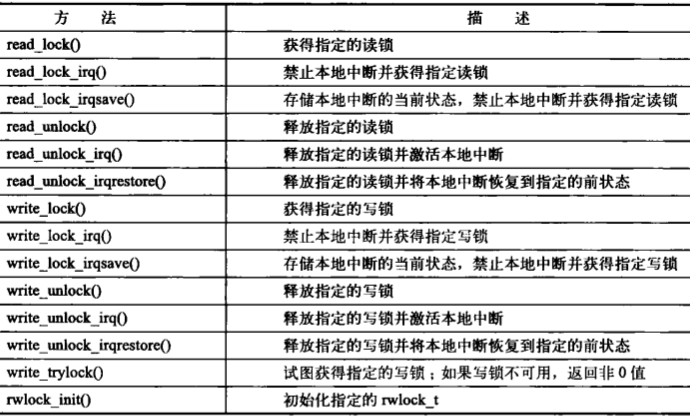
- 下标列出了针对读写自旋锁的所有操作
- 在使用Linux读写自旋锁时,最后要考虑的一点是这种锁机制照顾读比照顾写要多一点。 当读锁被持有时,写操作为了互斥访问只能等待,但是,读者却可以继续成功地作占用锁。而自旋等待的写者在所有读者释放锁之前是无法获得锁的。所以,大量读者必定会使挂起的写者处于饥饿状态,在你自己设计锁时一定要记住这一点——有些时候这种行为是有益的,有时则会带来灾难
- 自旋锁提供了一种快速简单的锁实现方法。如果加锁时间不长并且代码不会睡眠(比如中断处理程序),利用自旋锁是最佳选择。如果加锁时间可能很长或者代码在持有锁时有可能睡眠, 那么最好使用信号量来完成加锁功能
