此时你应该会收到一个Error的提示:
WrapperSimpleApp Error: Unable to locate the class org.elasticsearch.bootstrap.ElasticsearchF : java.lang.ClassNotFoundException: org.elasticsearch.bootstrap.ElasticsearchF
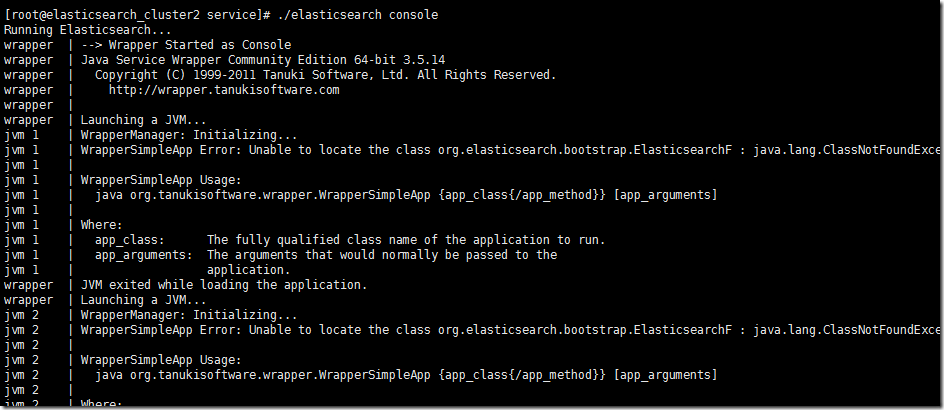
第一次看到这个我有点蒙,这个ElasticsearchF是个什么对象。命名有点特殊,再进一步查看Exception的信息,其实是一个ClassNotFoundException异常。说明找不到这个ElasticSearchF类。
两种可能性,第一就是java elasticsearch相关包的问题,确实缺少这个类。但是这个可能性很小,因为我们之前直接运行elasticsearch是成功的。我当时用jd-gui翻了下es的包,确实没有这个类。
第二就是这里的配置错误,应该就个手误,确实没有ElasticsearchF这个类。
我们查看下service/elasticsearch.conf配置文件里是不是有这个‘elasticsearchF’字符串。(wrapper包是使用当前目录下的elasticsearch.conf作为配置文件使用的)
grep –i elasticsearchf elasticsearch.conf

确实有这个字符串,我们进行编辑保存,去掉最后的‘F’。

然后我们在进行启动尝试。
./elasticsearch console
我不知道你是不是会和我的情况一样,提示相关命令都是不规范的。
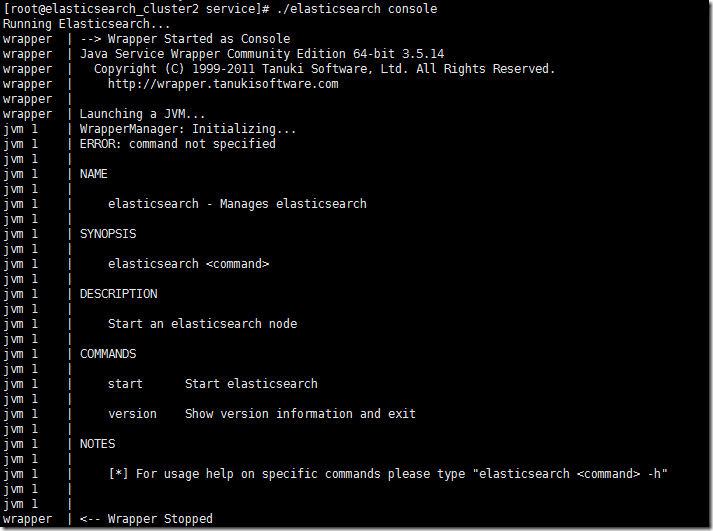
这个运行链路基本上经过三个路径,第一个就是service/elasticsearch shell启动脚本,然后获取命令分析命令再启动exec下的相关java servicewrapper程序。
这个java servicewrapper程序,版本是3.5.14。根据上述思路,通过查看elasticsearch shell程序,它在接收到外部的命令之后会启动exec下的java servicewrapper程序。我想试着编辑了下elasticsearch shell文件,输出一些信息出来,查看下是不是获取相关路径或者参数之类的导致错误。(遇到问题不怕,至少我们要一路跟下去,看下究竟是怎么回事。)
vim ./elasticsearch
esc
:/console
找下console在哪里,然后加上调试文本信息,输出到界面上。
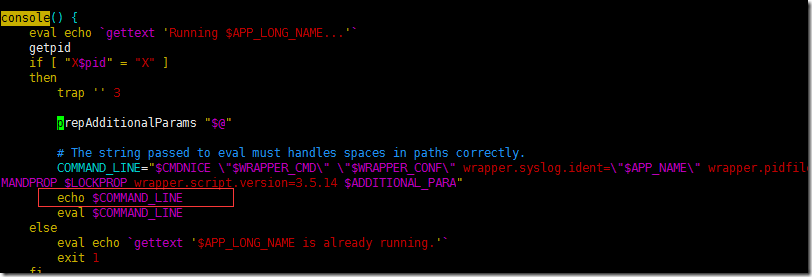
再运行,查看命令参数是否有问题。

查看了下,输出的参数基本都没有问题。一时无解。好奇心作怪,本想再进一步看下exec/elasticsearch-linux-x86-64.so文件的,后来发现打开根本就看不懂。所以就另寻其他方法,我找了windows版本servicewrapper,发现windows的elasticsearchservicewrapper是没有32位的servicewrapper的。我试着运行起来基本上也是报相同的错误,但是windows的wrapper的error信息比较多点,提示出错的原因在哪里。
我想修改下日志的输出级别,看能否输出一些可以用的信息。编辑service/elasticsearch.conf wrapper包专用配置。
# Log Level for console output. (See docs for log levels) wrapper.console.loglevel=TRACE
# Log Level for console output. (See docs for log levels) wrapper.console.loglevel=TRACE
我们将日志输出级别设置成trace,有两处需要设置,我们再看输出信息。
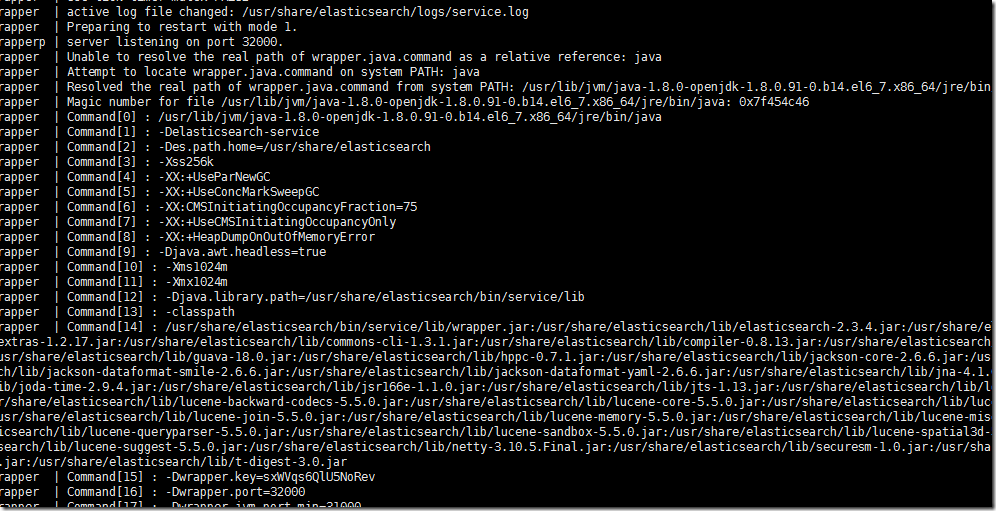
是输出了一些有用的信息,可以查看log文件详情。
WrapperManager Debug: Received a packet LOGFILE : /usr/share/elasticsearch/logs/service.log
但是有关于error的信息还是只有一条。
这里就告一段落。我们的目的是为了使用console来运行,想查看下一些运行日志,但是跑不起来也无所谓,我们继续执行安装操作。
(哪位博友如果知道问题在哪里的可以分享出来,我觉得这个问题不是一个偶发性问题,应该都会遇到。我先抛出问题,至少可以服务将来的使用者。这里先谢谢了。)
其实,如果你不使用elasticsearch servicewrapper来包装而是自己去下载java serivcewrapper来包装elasticsearch也是可以的,实现起来也很方便。
我们回到主题,既然我们无法console运行,也看不了一些wrapper console执行时的情况,那我们就只能进行安装了。
2.5.3 servicewrapper安装 (elasticsearch init.d 启动文件设置user、openfile、configpath)
按照elasticsearch servicewrapper parameter参数指示,我们执行安装。
./elasticsearch install
Installing the Elasticsearch daemon..
守护进程安装完成。我们还是前去系统目录下查看是不是安装成功(技术人员始终保持一个严谨的心态是有必要的。)前往/etc/init.d/目录下查看。
ll /etc/init.d/
-rwxrwxr–. 1 root root 4496 10月 4 01:43 elasticsearch
我这里设置过chmod u+x ./elasticsearch。别忘记设置文件的执行权限,这在我们【2.1节】里将结果,这里就不重复了。
我们开始编辑elasticsearch启动文件。
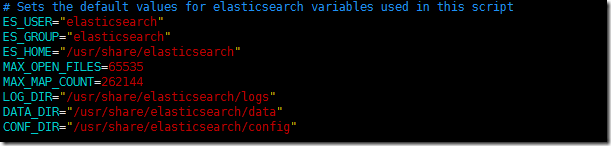
主要就是这段,填写好配置的es的专用账户(elasticsearch【2.2.节】),还有相应的文件路径。这里先忽略MAX_OPEN_FILES、MAX_MAP_COUNT两个配置项,在后面【3.3.节】配置部分会讲解到。
2.5.4 chkconfig -add 加入linux启动服务列表
将其添加到系统服务中,以便被系统自动启动。
chkconfig –add elasticsearch
chkconfig –list
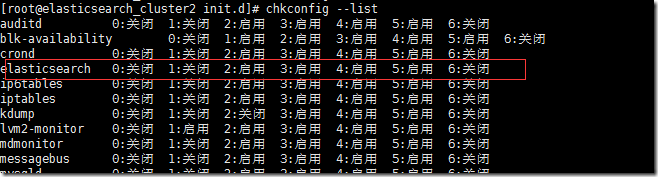
已经添加好系统自启动服务列表中。
service elasticsearch start
启动es实例,等待端口启动完成,稍等片刻查看端口情况。
netstat –tnl
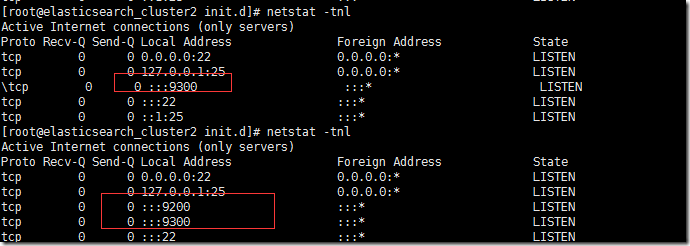
9300端口比9200端口先启动,因为9300端口是 cluster内部管理端口。9200是rest endpoint 服务端口。当然,这个时间延长不会很长。
端口都启动成功之后,我们查看下能否正常访问es实例。
curl -get http://192.168.0.103:9200/ { "name" : "node-1", "cluster_name" : "orderSearch_cluster", "version" : { "number" : "2.3.4", "build_hash" : "e455fd0c13dceca8dbbdbb1665d068ae55dabe3f", "build_timestamp" : "2016-06-30T11:24:31Z", "build_snapshot" : false, "lucene_version" : "5.5.0" }, "tagline" : "You Know, for Search" }
我们还是使用_cat rest endpoint来查看。
curl -get http://192.168.0.103:9200/_cat/nodes 192.168.0.103 192.168.0.103 4 61 0.00 d * node-1
如果你可以在本机访问,但是在外部浏览器中无法访问,很可能是防火墙的设置问题,你可以去设置下防火墙。
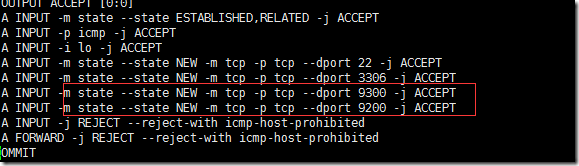
vim /etc/sysconfig/iptables
重启网络服务,以便加载防火墙设置项。
service network restart
然后再尝试看能否外部访问,如果不行你就telnet端口下。
因为访问不了还有一个原因是和elasticsearch.yml一个配置项有关系。见【3.1.1节】。
重启机器,查看es实例是否会自动启动。
shutdown –r now
稍等片刻,然后尝试连接机器。
如果没出什么意外,都应该正常的,端口也启动成功了。说明我们完成了es实例自启动功能,它现在作为linux系统服务被自动管理。
安装成服务之后,elasticsearch servicewrapper和我们就没有太多关系了。因为它的parameter都是围绕者我们基于servicewrapper来使用的。
2.6.安装_plugin/head管理插件(辅助管理)
为了很好的管理集群,我们需要相应的工具,head是比较流行和通用的,而且是免费的。当然还有很多好用的其他工具,如,Bigdesk、Marvel(商用收费)。plugin的安装都大同小异,我们这里就使用通用的head工具。
先看下,head给我们带来的清晰的集群节点管理视图。
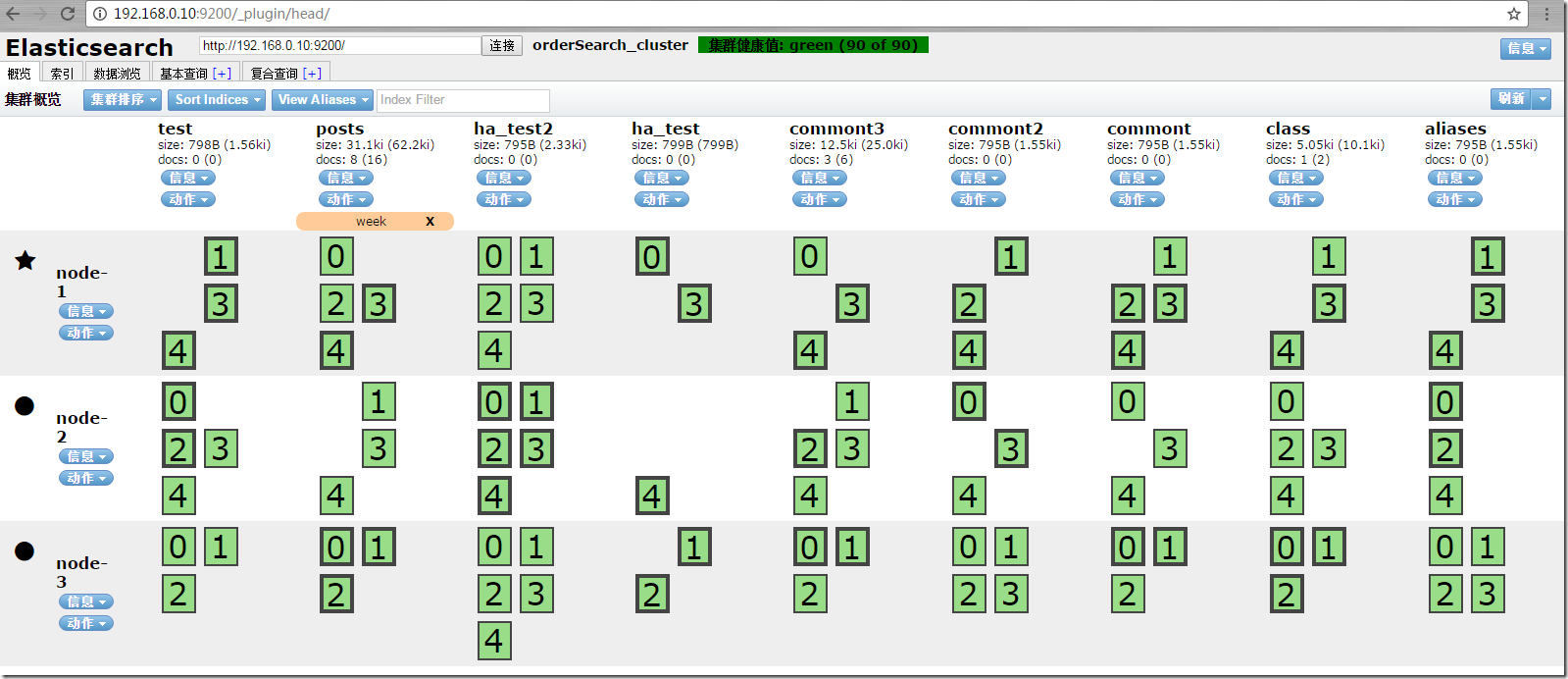
这是有三个节点的es集群实例。它是一个二维矩阵排列,最上面横向是索引,最左边是节点,交叉的地方是索引的分片信息和分片比例。
安装head插件还是比较方便的,你也可以直接copy文件的方式使用。在elasticsearch的home目录下有一个plugins目录,它是所有插件的目录,所有的插件都会在这个文件夹查找和加载。
我们看下安装head插件方法。在elasticsearch/bin 目录下有一个plugin可执行文件,它是专门用来安装插件用的程序。
./plugin -install mobz/elasticsearch-head
插件的查找路径有几个elasticsearch官网是一个,github是一个。这里会先尝试在github上查找,稍等片刻,等待安装完成。我们尝试访问head插件地址rest地址/_plugin/head。
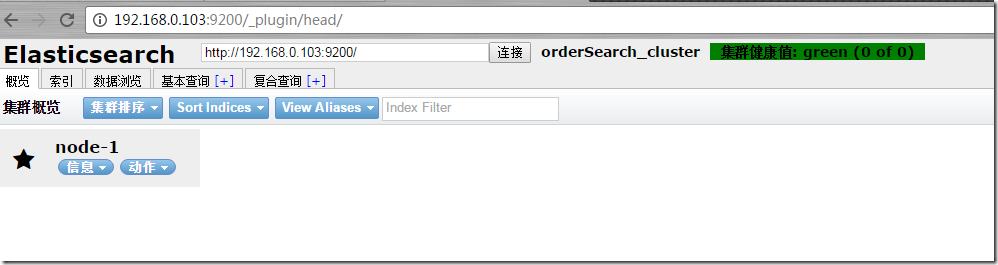
看到这个界面基本安装成功了,node-1默认是master节点。
2.7.安装chrom中的elasticsearch客户端插件
chrom中有很多可以使用的elasticsearch客户端插件,便于开发和维护,建议直接使用chrom中的插件。只要搜索下elasticsearch关键字就会出来很多。

有两个比较常用,也比较好用,EalsticSearch Toolbox、Sense(自动提示dsl编辑工具)。chrom插件都是那么的酷,使用起来都很赏心悦目。
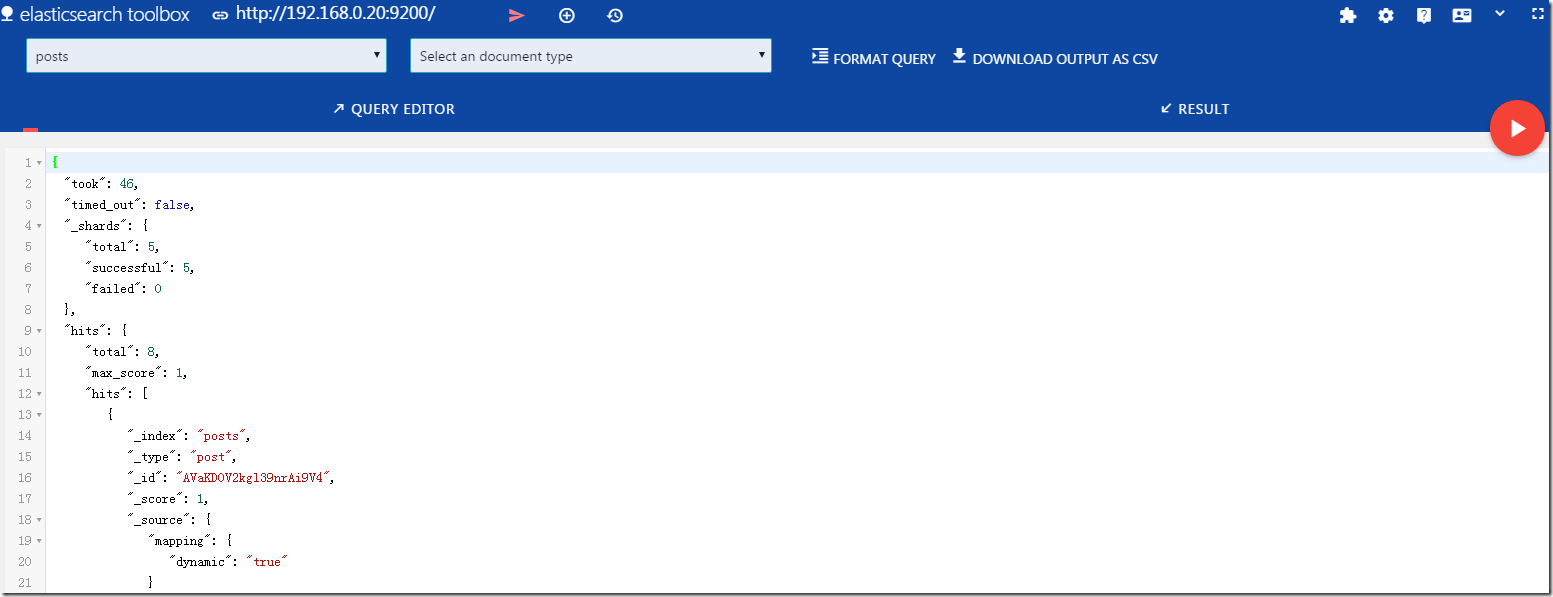
elasticsearch toolbox 可以很方便的查询和导出数据。
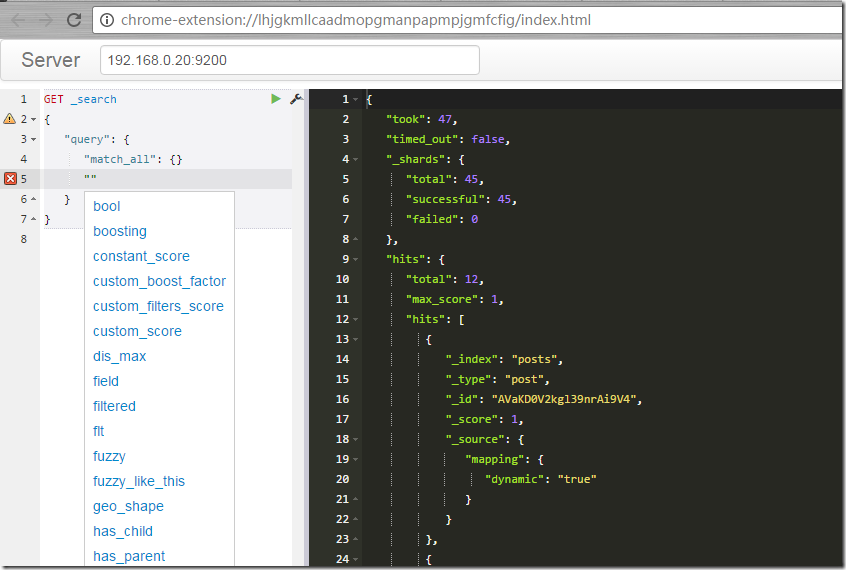
sense可以让你编辑elasticsearch dsl 特定语言会有启动提示帮助,这样编写起复杂的dsl效率会高而且不易出错。其他的工具我也没用过,感觉都可以尝试用用看。
(备注:如果你无法访问chrom商店中心就需要特殊处理下,这里就不解释了。)
2.8.使用elasticsearch自带的_cat工具
在一些特殊的情况下你可能无法直接使用plugin来帮你管理或者查看集群情况。此时你可以直接使用elasticsearch自带的rest _cat查看集群情况,比如,你可能发现_plugin/head有一些节点没有上来,但是你又不确定发生了什么情况,你就可以使用/_cat/nodes来查看所有node的情况。有时候确实有的节点没有启动起来,但是大多数情况下都是各自为政(脑裂),你可能需要让他们重新选举或者加快的选举过程。
http://192.168.0.20:9200/_cat/nodes?v (查看nodes情况)
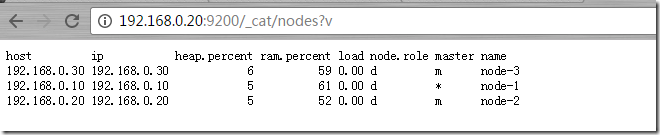
_cat rest端点带有一个v的参数,这个参数是帮助你阅读的参数。_search rest端点带有pretty参数,这个参数是帮助查询数据阅读的。每一个端点基本上都有各自的辅助阅读参数。
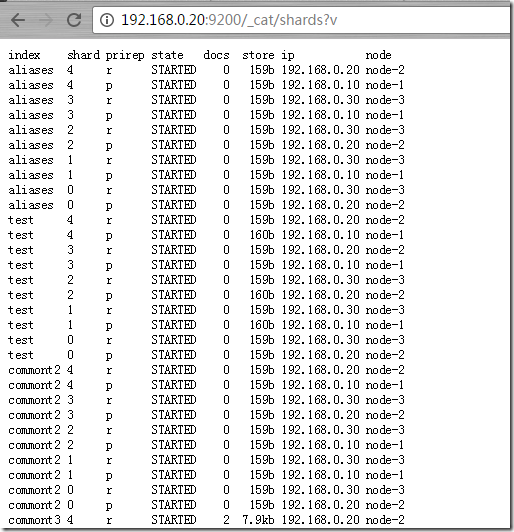
http://192.168.0.20:9200/_cat/shards?v(查看shards情况)
http://192.168.0.20:9200/_cat/ (查看所有可以cat的功能)
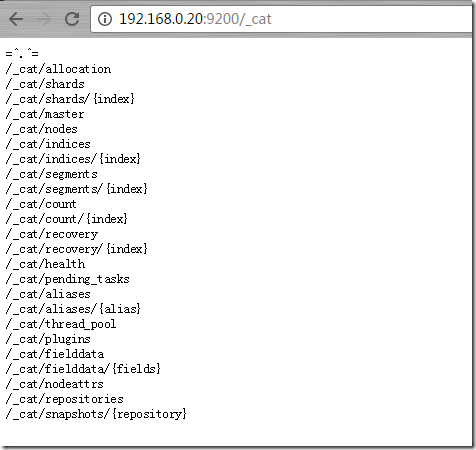
你可以查看系统 aliases别名、segments片段(看下每个片段的提交版本一致性)、indices索引集合等等。
2.9.clone 虚机(修改IP、HWaddr、UUID配置,最后修改下系统时间)
当我们完成了对一台机器的安装之后,接下来就需要搭建分布式系统。分布式系统就需要多节点机器,按照es分布式集群搭建最佳实践,你至少需要三个节点。所以我们将已经安装完成的这个机器clone出来两台,一共三台组成可以工作的三个节点的分布式系统。
首先clone当前安装完成的机器,192.168.0.103,clone好之后启动起来修改几个配置即可。(因为你是clone出来的,所以配置已经重复,比如,网卡地址、IP地址)
编辑网卡配置文件:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth3 HWADDR=00:0C:29:CF:48:23 TYPE=Ethernet UUID=b848e750-d491-4c9d-b2ca-c853f21bf40b ONBOOT=yes NM_CONTROLLED=yes BOOTPROTO=static BROADCAST=192.168.233.255 IPADDR=192.168.0.103 NETMASK=255.255.255.0 GATEWAY=192.168.0.1
DEVICE 是网卡标示,根据你本地的网卡标识修改成对应的即可,可以通过ifconfig查看。HWADDR网卡地址,随意修改下,保证在你的网段内不重复即可。UUID也是和HWADDR一样修改。
IP地址修改成你自己觉得合适的IP,最好参考你当前物理机器的相关配置。GATEWAY网关地址要参考你物理机器的网关地址,如果你的虚拟机使用的是桥接模式的网络连接,这里就需要设置,要不然网络就连接不上。
重启网络服务:
service network restart
稍等片刻,ssh重新连接,然后ifconfig看下网络相关参数是否正确,最后再ping一下外部网址和你当前物理机器的IP,保证网络都是通畅的。
最后我们需要修改下linux的系统时间,这是为了防止服务器时间不一致,导致很多细微的问题,比如,es集群master选举的时间戳问题、log4j输出的日志的记录问题等等。在分布式系统中,时钟非常重要。
date -s '20161008 20:47:00'
时区的话如果你需要也可以设置,这里暂时不需要。
根据你自己的需要,你clone几台机器。按照默认的方式我们大概约定为,192.168.0.10、192.168.0.20、192.168.0.30,这三台机器将组成一个es分布式集群。
3.配置
集群的各个节点我们已经准备好了,我们接下来准备配置集群,让这三个节点可以连接在一起。这里涉及的配置比较简单,只是完成集群的一个基本常用功能,如有特殊的需求可以自行查看elasticsearch官网或者百度,这方面的资料已经很丰富了。
这里的一些配置我们其实已经受益于elasticsearch servicewrapper简化了很多。
从这里开始,我们将对三台机器进行配置,192.168.160.10、192.168.160.20、192.168.160.30。
3.1.elasticsearch.yml配置
在elasticsearch的config目录下都是配置文件。导航到 cd /usr/share/elasticsearch/config目录。
3.1.1.IP访问限制、默认端口修改9200
这里有两个需要提醒下,第一个就是IP访问限制,第二个就是es实例的默认端口号9200。IP访问限制可以限定具体的IP访问服务器,这有一定的安全过滤作用。
# Set the bind address to a specific IP (IPv4 or IPv6): # network.host: 0.0.0.0
如果设置成0.0.0.0则是不限制任何IP访问。一般在生产的服务器可能会限定几台IP,通常用于管理使用。
默认的端口9200在一般情况下也有点风险,可以将默认的端口修改成另外一个,这还有一个原因就是怕开发人员误操作,连接上集群。当然,如果你的公司网络隔离做的很好也无所谓。
# # Set a custom port for HTTP: # http.port: 9200 transport.tcp.port: 9300
这里的9300是集群内部通讯使用的端口,这个也可以修改掉。因为连接集群的方式有两种,通过扮演集群node也是可以进入集群的,所以还是安全起见,修改掉默认的端口。
(备注:记得修改三个节点的相同配置,要不然节点之间无法建立连接工作,也会报错。)
3.1.2.集群发现IP列表、node、cluster名称
紧接着修改集群节点IP地址,这样可以让集群在规定的几个节点之间工作。elasticsearch,默认是使用自动发现IP机制。就是在当前网段内,只要能被自动感知到的IP就能自动加入到集群中。这有好处也有坏处。好处就是自动化了,当你的es集群需要云化的时候就会非常方便。但是也会带来一些不稳定的情况,如,master的选举问题、数据复制问题。
导致master选举的因素之一就是集群有节点进入。当数据复制发生的时候也会影响集群,因为要做数据平衡复制和冗余。这里面可以独立master集群,剔除master集群的数据节点能力。
固定列表的IP发现有两种配置方式,一种是互相依赖发现,一种是全量发现。各有优势吧,我是使用的依赖发现来做的。这有个很重要的参考标准,就是你的集群扩展速度有多快。因为这有个问题就是,当全量发现的时候,如果是初始化集群会有很大的问题,就是master全局会很长,然后节点之间的启动速度各不一样。所以我采用了靠谱点的依赖发现。
你需要在192.168.0.20的elasticsearch中配置成:
# ——————————— Discovery ———————————- # # Pass an initial list of hosts to perform discovery when new node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # discovery.zen.ping.unicast.hosts: [ "192.168.0.10:9300" ]
让他去发现10的机器,以此内推,完成剩下的30的配置。
(备注:网上有很多针对不同场景的发现配置,大家可以就此抛砖引玉,对这个主题感兴趣的可以百度很多资料的。)
然后你需要配置下集群名称,就是你当前节点所在集群的名称,这有助于你规划你的集群。只有集群名称一样才能组成一个逻辑集群。
# ———————————- Cluster ———————————– # # Use a descriptive name for your cluster: # cluster.name: orderSearch_cluster # # ———————————— Node ———————————— # # Use a descriptive name for the node: # node.name: node-2
以此类推,完成另外两个节点的配置。cluster.name的名称必须保持一样。然后分别设置node.name。
3.1.3.master node 启动切换
这里有一个小小的经验分享下,就是我在使用集群的时候,因为我是虚拟化出来的机器所以经常会关闭和重启集群。有时候发现集群master宣酒会有一个问题就是,如果你的集群关闭的方式不对,会直接影响下个master选举的逻辑。
我查了下选举的大概逻辑,它会根据分片的数据的前后新鲜程度来作为选举的一个重要逻辑。(日志、数据、时间都会作为集群master全局的重要指标)
因为考虑到数据一致性问题,当然是用最新的数据节点作为master,然后进行新数据的复制和刷新其他node。
如果你发现有一个节点迟迟进不了集群,可以尝试重启下es服务,让集群master重新全局。
3.2.linux 打开最大文件数设置(用作index时候的系统阀值)
在linux系统中,要想使用最大化的系统资源需要向操作系统去申请。由于elasticsearch需要在index的时候用到大量的文件句柄资源,在原来linux默认的资源下可能会不够用。所以这里就需要我们在使用的时候事先设置好。
这个配置在《ElasticSearch 可扩展的开源弹性搜索解决方案》一书中作为重点配置介绍,可想而知还是有不少人踩到过的坑。
这个配置在elasticsearch service wrapper中帮我们配置好了。
