Lucene的学习第四篇——入门代码
需求:
通过关键字搜索文件,凡是文件名或文件内容包括关键字的文件都需要找出来:下图(是一堆文件列表)
本人使用版本与环境:
lucene4.10.2
Jdk:1.8(Jdk要求:1.7以上)
SpringBoot:2.1.3
IDE:IntelliJ IDEA
Pom.xml
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
2 <groupId>org.apache.lucene</groupId>
3 <artifactId>lucene-core</artifactId>
4 <version>4.10.2</version>
5 </dependency>
6 <dependency>
7 <groupId>org.apache.lucene</groupId>
8 <artifactId>lucene-analyzers-common</artifactId>
9 <version>4.10.2</version>
10 </dependency>
11 <dependency>
12 <groupId>org.apache.lucene</groupId>
13 <artifactId>lucene-queryparser</artifactId>
14 <version>4.10.2</version>
15 </dependency>
16 <dependency>
17 <groupId>com.janeluo</groupId>
18 <artifactId>ikanalyzer</artifactId>
19 <version>2012_u6</version>
20 </dependency>
21
22 <!--中文分词器-->
23 <dependency>
24 <groupId>org.apache.lucene</groupId>
25 <artifactId>lucene-analyzers-smartcn</artifactId>
26 <version>7.6.0</version>
27 </dependency>
28 <!--文件IO操作-->
29 <dependency>
30 <groupId>commons-io</groupId>
31 <artifactId>commons-io</artifactId>
32 <version>2.6</version>
33 </dependency>
34
35
代码
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
2
3import ch.qos.logback.core.net.SyslogOutputStream;
4import org.apache.commons.io.FileUtils;
5import org.apache.lucene.analysis.Analyzer;
6import org.apache.lucene.analysis.standard.StandardAnalyzer;
7import org.apache.lucene.document.*;
8import org.apache.lucene.index.*;
9import org.apache.lucene.search.IndexSearcher;
10import org.apache.lucene.search.ScoreDoc;
11import org.apache.lucene.search.TermQuery;
12import org.apache.lucene.search.TopDocs;
13import org.apache.lucene.store.Directory;
14import org.apache.lucene.store.FSDirectory;
15import org.apache.lucene.util.Version;
16import org.junit.Test;
17
18import java.io.File;
19
20public class FileTest {
21 /**
22 * 创建索引
23 * @throws Exception
24 */
25 @Test
26 public void createIndex() throws Exception{
27 //索引库存放的位置,也可以放在硬盘
28 Directory directory= FSDirectory.open(new File("./index"));
29 //标准的分词器
30 Analyzer analyzer =new StandardAnalyzer();
31 //创建输出流write
32 IndexWriterConfig config =new IndexWriterConfig(Version.LUCENE_4_10_2,analyzer);
33 IndexWriter indexWriter = new IndexWriter(directory,config);
34
35
36 //创建Filed域
37 File f=new File("F:\\a");
38 //找到下面的所有待搜索的文件
39 File[] listFiles=f.listFiles();
40 for (File file:listFiles){
41 //创建文档对象
42 Document document=new Document();
43 //文件名称
44 String file_name=file.getName();
45 Field fileNameFiled=new TextField("fileName",file_name, Field.Store.YES);
46 //文件大小
47 long file_size= FileUtils.sizeOf(file);
48 Field fileSizeField=new LongField("fileSize",file_size,Field.Store.YES);
49 //文件路径
50 String file_path=file.getPath();
51 Field filePathField=new StoredField("filePath",file_path);
52 //文件内容
53 String file_content = FileUtils.readFileToString(file,"utf8");
54 Field fileContentField=new TextField("fileContent",file_content, Field.Store.YES);
55
56 //保存到文件对象里
57 document.add(fileNameFiled);
58 document.add(fileSizeField);
59 document.add(filePathField);
60 document.add(fileContentField);
61
62 //写到索引库
63 indexWriter.addDocument(document);
64 }
65 //关闭
66 indexWriter.close();
67 }
68
69 /**
70 * 查询索引
71 * @throws Exception
72 */
73 @Test
74 public void searchIndex() throws Exception{
75 //第一步,查询准备工作,创建Directory对象
76 Directory dir = FSDirectory.open(new File("./index"));
77 //创建IndexReader对象
78 IndexReader reader= DirectoryReader.open(dir);
79 //创建IndexSearch对象
80 IndexSearcher search =new IndexSearcher(reader);
81
82 //第二步,闯将查询条件对象
83 TermQuery query=new TermQuery(new Term("fileContent","what"));
84 //第三步:执行查询,参数(1:查询条件对象,2:查询结果返回的最大值)
85 TopDocs topDocs=search.search(query,10);
86 //第四步:处理查询结果
87 //输出结果数量
88 System.out.print("查询结果数量:"+topDocs.totalHits);
89 //取得结果集
90 ScoreDoc[] scoreDocs=topDocs.scoreDocs;
91 for (ScoreDoc scoreDoc:scoreDocs){
92 System.out.println("当前doc得分:"+scoreDoc.score);
93 //根据文档对象ID取得文档对象
94 Document doc=search.doc(scoreDoc.doc);
95 System.out.println("文件名称:"+doc.get("fileName"));
96 System.out.println("文件路径:"+doc.get("filePath"));
97 System.out.println("文件大小:"+doc.get("fileSize"));
98 System.out.println("=======================================");
99 }
100 //关闭IndexReader对象
101 reader.close();
102 }
103}
104
105
106
searchIndex()方法运行后出现类似的索引库,则表示成功
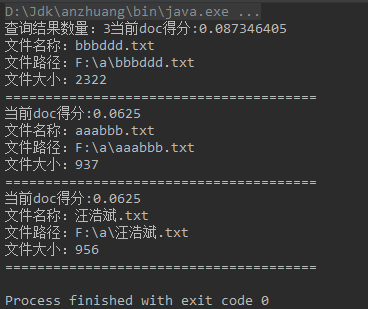
searchIndex执行相应的搜索条件之后:
通过以上的两段代码我们实现了创建索引与查询索引。
第一段代码做了这么几个事:
将我们要查询的每个文档,构建了了文档对象。文档对象里面存放的就是该文档的信息。(文件名,大小,内容,路径等)
将该文档对象扔进索引库(自动创建了索引)
索引库存放在./index 目录下
第二段代码:
就是到索引库的目录下 找fileContent里面有:whatt的文档。然后输出了该文档的信息。
更换查询条件,如查询名称为aaabbb.txt,aaabbb,汪浩斌.txt的文档,再去看上一篇文章开篇的疑问
中文分词器:
我们还是面临一个问题:
如何通过“全文” 搜到我们想要的“全文检索.txt”文档?
我们通过lukeall查看索引,找到了原因。那就是没有正确的分词,是因为我们在代码中使用的是官方推荐的标准分词器,而这个分词器,是老外的,不能对中文进行分词,所以我们要使用中文分词器。而现在lucene的中文分词器:CJK词器,smartChinese分词器。
CJK分词器:是二分法:举例:我爱写代码:分成:我爱,爱写,写代,代码。
smartChinese:扩展性不太好,
市场用的有:庖丁解牛,mmseg4j。但是这两个作者多年没有更新了。这里主要介绍IK 分词器。
这里仅仅介绍IK分词器的使用:
2
3
4
5
6
7
2 <groupId>com.janeluo</groupId>
3 <artifactId>ikanalyzer</artifactId>
4 <version>2012_u6</version>
5 </dependency>
6
7
之前的代码里用的是标准分词器,老外的,不支持中文分词,下面换Ik分词器
2
3
4
5
6
2 //Analyzer analyzer =new StandardAnalyzer();
3 //下面替换为ik分词器
4 Analyzer analyzer =new IKAnalyzer();
5
6
再执行查询方法,可以看到中文查询条件也可以的到结果