一、介绍
Lucene是一款高性能的、可扩展的
信息检索(IR)工具库。信息检索是指文档搜索、文档内信息搜索或者文档相关的元数据搜索等操作。
简单的说,搜索就是搜寻、查找,在IT行业中就是指用户输入关键字,通过相应的算法,查询并返回用户所需要的信息。
传统的模糊查询方法在处理大数据的时候效率低、耗时长(select * from 表名 where 字段名 like ‘%关键字%’),所以lucene应运而生,也有了倒排索引的概念
二、倒排索引:
** 又称为反向索引: 以字或者词,甚至是一句话一段话作为一个关键字进行索引, 每一个关键字都会对应着一个记录项, 记录项中记录了这个关键字出现在那些文档中, 在此文档的什么位置上**
在实际的运用中,我们可以对数据库中原始的数据结构(左图),在业务空闲时事先根据左图内容,创建新的倒排索引结构的数据区域(右图)。用户有查询需求时,先访问倒排索引数据区域(右图),得出文档id后,通过文档id即可快速,准确的通过左图找到具体的文档内容。

Lucene、Solr、Elasticsearch关系
Lucene:底层的API,工具包
Solr:基于Lucene开发的企业级的搜索引擎产品
Elasticsearch:基于Lucene开发的企业级的搜索引擎产品
创建索引流程:
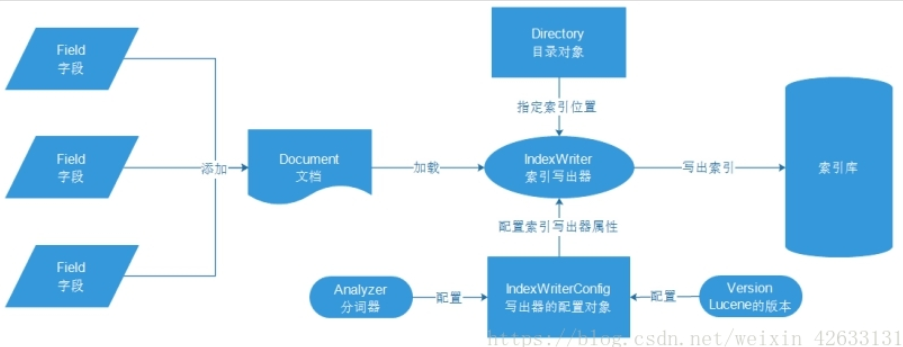
文档Document:数据库中一条具体的记录
字段Field:数据库中的每个字段
目录对象Directory:物理存储位置
写出器的配置对象:需要分词器和lucene的版本
三、Java API实现
API来实现对索引的增(创建索引)、删(删除索引)、改(修改索引)、查(搜索数据)。
**1、IndexWriter:**索引写入器对象,添加索引, 修改索引和删除索引。
需要传入Directory和indexWriterConfig对象 ,即索引的目录和配置
**2、FSDirectory:**用来指定文件系统的目录, 将索引信息保存到磁盘上
RAMDriectory: 内存目录, 将索引库信息存放到内存中
3、IndexWriterConfig: 索引写入器的配置类,需要传递Lucene的版本和分词器4、QueryParser(查询解析器)
5、Query(查询对象,包含要查询的关键词信息)
6、IndexSearch(索引搜索对象,执行搜索功能)
7、TopDocs(查询结果对象)
8、 ScoreDoc(得分文档对象)
代码实现:
依赖:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
2 <lunece.version>4.10.2</lunece.version>
3
4 </properties>
5 <dependencies>
6 <dependency>
7 <groupId>junit</groupId>
8 <artifactId>junit</artifactId>
9 <version>4.12</version>
10 </dependency>
11 <!-- lucene核心库 -->
12 <dependency>
13 <groupId>org.apache.lucene</groupId>
14 <artifactId>lucene-core</artifactId>
15 <version>${lunece.version}</version>
16 </dependency>
17 <!-- Lucene的查询解析器 -->
18 <dependency>
19 <groupId>org.apache.lucene</groupId>
20 <artifactId>lucene-queryparser</artifactId>
21 <version>${lunece.version}</version>
22 </dependency>
23 <!-- lucene的默认分词器库 -->
24 <dependency>
25 <groupId>org.apache.lucene</groupId>
26 <artifactId>lucene-analyzers-common</artifactId>
27 <version>4.10.1</version>
28 </dependency>
29 <!-- lucene的高亮显示 -->
30 <dependency>
31 <groupId>org.apache.lucene</groupId>
32 <artifactId>lucene-highlighter</artifactId>
33 <version>${lunece.version}</version>
34 </dependency>
35 <!-- IK分词器 中文 -->
36 <dependency>
37 <groupId>com.janeluo</groupId>
38 <artifactId>ikanalyzer</artifactId>
39 <version>2012_u6</version>
40 </dependency>
41 </dependencies>
42
1、创建倒排索引
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
2 @Test
3 public void simpleCreate() {
4 try {
5 //1 创建文档对象
6 Document ducument = new Document();
7 // 添加字段信息。参数:字段的名称、字段的值、是否存储,yes储存,no不储存
8 ducument.add(new StringField("id", "1", Field.Store.YES));
9 // title字段用TextField,创建索引被分词。StringField创建索引,但不会被分词
10 ducument.add(new TextField("title", "谷歌地图之父跳槽facebook", Field.Store.YES));
11
12 //2 创建存储目录,本地
13 FSDirectory directory = FSDirectory.open(new File("e:/hadoop/hdpdata/lucene"));
14 //3 创建分词器
15 StandardAnalyzer analyzer = new StandardAnalyzer();
16 //4 创建索引写入器的配置对象
17 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
18
19 //5 创建索引写入器对象
20 IndexWriter indexWriter = new IndexWriter(directory, config);
21 //6 将文档交给索引写入器
22 indexWriter.addDocument(ducument);
23 //7 提交
24 indexWriter.commit();
25 //8 关闭
26 indexWriter.close();
27 }catch (Exception e){
28 e.printStackTrace();
29 }
30 }
31
32 //创建多个文档的文件
33 @Test
34 public void manyCreate() {
35 try {
36 //1 创建文档对象集合
37 Collection<Document> documents = new ArrayList<Document>();
38
39 Document ducument = new Document();
40 // 添加字段信息。参数:字段的名称、字段的值、是否存储,yes储存,no不储存
41 ducument.add(new StringField("id", "1", Field.Store.YES));
42 // title字段用TextField,创建索引被分词。StringField创建索引,但不会被分词
43 ducument.add(new TextField("title", "谷歌地图之父跳槽facebook", Field.Store.YES));
44 documents.add(ducument);
45
46 Document ducument2 = new Document();
47 // 添加字段信息。参数:字段的名称、字段的值、是否存储,yes储存,no不储存
48 ducument2.add(new StringField("id", "1", Field.Store.YES));
49 // title字段用TextField,创建索引被分词。StringField创建索引,但不会被分词
50 ducument2.add(new TextField("title", "谷歌地图之父加盟FaceBook", Field.Store.YES));
51 documents.add(ducument2);
52
53 Document ducument3 = new Document();
54 // 添加字段信息。参数:字段的名称、字段的值、是否存储,yes储存,no不储存
55 ducument3.add(new StringField("id", "1", Field.Store.YES));
56 // title字段用TextField,创建索引被分词。StringField创建索引,但不会被分词
57 ducument3.add(new TextField("title", "谷歌地图创始人拉斯离开谷歌加盟Facebook", Field.Store.YES));
58 documents.add(ducument3);
59
60 Document ducument4 = new Document();
61 // 添加字段信息。参数:字段的名称、字段的值、是否存储,yes储存,no不储存
62 ducument4.add(new StringField("id", "1", Field.Store.YES));
63 // title字段用TextField,创建索引被分词。StringField创建索引,但不会被分词
64 ducument4.add(new TextField("title", "谷歌地图之父跳槽Facebook与Wave项目取消有关", Field.Store.YES));
65 documents.add(ducument4);
66
67 Document ducument5 = new Document();
68 // 添加字段信息。参数:字段的名称、字段的值、是否存储,yes储存,no不储存
69 ducument5.add(new StringField("id", "1", Field.Store.YES));
70 // title字段用TextField,创建索引被分词。StringField创建索引,但不会被分词
71 ducument5.add(new TextField("title", "谷歌地图之父拉斯加盟社交网站Facebook", Field.Store.YES));
72 documents.add(ducument5);
73
74 //2 创建存储目录,本地
75 FSDirectory directory = FSDirectory.open(new File("e:/hadoop/hdpdata/lucene"));
76 //3 创建分词器
77 StandardAnalyzer analyzer = new StandardAnalyzer();
78// IKAnalyzer ikAnalyzer = new IKAnalyzer();
79 //4 创建索引写入器的配置对象
80 IndexWriterConfig config = new IndexWriterConfig(Version.LATEST, analyzer);
81 //如果有数据,覆盖
82 config.setOpenMode(IndexWriterConfig.OpenMode.CREATE);
83
84 //5 创建索引写入器对象
85 IndexWriter indexWriter = new IndexWriter(directory, config);
86 //6 将文档交给索引写入器
87 indexWriter.addDocuments(documents);
88 //7 提交
89 indexWriter.commit();
90 //8 关闭
91 indexWriter.close();
92 }catch (Exception e){
93 e.printStackTrace();
94 }
95 }
96
2、查询索引
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
2 @Test
3 public void search() {
4 try {
5 //1 创建查询文件
6 Directory dir = FSDirectory.open(new File("e:/hadoop/hdpdata/lucene"));
7 //2 索引读取工具
8 DirectoryReader reader = DirectoryReader.open(dir);
9 //搜索工具
10 IndexSearcher indexSearcher = new IndexSearcher(reader);
11
12 // 创建查询解析器,参数:查询的字段的名称,分词器
13 QueryParser queryParser = new QueryParser("title", new IKAnalyzer()); //new StandardAnalyzer()
14 //查询对象
15 Query query = queryParser.parse("谷歌");
16
17 //搜索工具查询,参数:查询对象,最大结果条数
18 //结果topdoc:按照匹配度排名得分前N名的文档信息(包含查询到的总条数信息、所有符合条件的文档的编号信息)
19 TopDocs search = indexSearcher.search(query, 10);
20
21 //获取总条数
22 System.out.println("一共有:"+search.totalHits+"条数据");
23
24 // 获取得分文档对象(ScoreDoc)数组.SocreDoc中包含:文档的编号、文档的得分
25 ScoreDoc[] scoreDocs = search.scoreDocs;
26 for(ScoreDoc scoreDoc : scoreDocs){
27 //文档编号
28 int id=scoreDoc.doc;
29 //文档编号对应文档
30 Document doc = reader.document(id);
31
32 System.out.println("id: "+doc.get("id")+" title: "+doc.get("title"));
33 // 取出文档得分
34 System.out.println("得分: " + scoreDoc.score);
35 }
36
37 }catch (Exception e){
38 e.printStackTrace();
39 }
40 }
41
3高亮显示
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
2 @Test
3 public void testHighlighter() throws Exception {
4 // 目录对象
5 Directory directory = FSDirectory.open(new File("e:/hadoop/hdpdata/lucene"));
6 // 创建读取工具
7 IndexReader reader = DirectoryReader.open(directory);
8 // 创建搜索工具
9 IndexSearcher searcher = new IndexSearcher(reader);
10
11 QueryParser parser = new QueryParser("title", new StandardAnalyzer());
12 Query query = parser.parse("谷歌");
13
14 // 格式化器
15 Formatter formatter = new SimpleHTMLFormatter("<body>", "</body>");
16 QueryScorer scorer = new QueryScorer(query);
17 // 准备高亮工具
18 Highlighter highlighter = new Highlighter(formatter, scorer);
19 // 搜索
20 TopDocs topDocs = searcher.search(query, 10);
21 System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
22
23 ScoreDoc[] scoreDocs = topDocs.scoreDocs;
24 for (ScoreDoc scoreDoc : scoreDocs) {
25 // 获取文档编号
26 int docID = scoreDoc.doc;
27 Document doc = reader.document(docID);
28 System.out.println("id: " + doc.get("id"));
29
30 String title = doc.get("title");
31 // 用高亮工具处理普通的查询结果,参数:分词器,要高亮的字段的名称,高亮字段的原始值
32 String hTitle = highlighter.getBestFragment(new StandardAnalyzer(), "title", title);
33
34 System.out.println("title: " + hTitle);
35 // 获取文档的得分
36 System.out.println("得分:" + scoreDoc.score);
37 }
38 }
39
4、排序
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
2 @Test
3 public void testSortQuery() throws Exception {
4 // 目录对象
5 Directory directory = FSDirectory.open(new File("e:/hadoop/hdpdata/lucene"));
6 // 创建读取工具
7 IndexReader reader = DirectoryReader.open(directory);
8 // 创建搜索工具
9 IndexSearcher searcher = new IndexSearcher(reader);
10
11 QueryParser parser = new QueryParser("title", new StandardAnalyzer());
12 Query query = parser.parse("谷歌");
13
14 // 创建排序对象,需要排序字段SortField,参数:字段的名称、字段的类型、是否反转如果是false,升序。true降序
15 Sort sort = new Sort(new SortField("id", SortField.Type.LONG, true));
16 // 搜索
17 TopDocs topDocs = searcher.search(query, 10,sort);
18 System.out.println("本次搜索共" + topDocs.totalHits + "条数据");
19
20 ScoreDoc[] scoreDocs = topDocs.scoreDocs;
21 for (ScoreDoc scoreDoc : scoreDocs) {
22 // 获取文档编号
23 int docID = scoreDoc.doc;
24 Document doc = reader.document(docID);
25 System.out.println("id: " + doc.get("id"));
26 System.out.println("title: " + doc.get("title"));
27 }
28 }
29
5、分页
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
2 @Test
3 public void testPageQuery() throws Exception {
4 // 实际上Lucene本身不支持分页。因此我们需要自己进行逻辑分页。我们要准备分页参数:
5 int pageSize = 2;// 每页条数
6 int pageNum = 3;// 当前页码
7 int start = (pageNum - 1) * pageSize;// 当前页的起始条数
8 int end = start + pageSize;// 当前页的结束条数(不能包含)
9
10 // 目录对象
11 Directory directory = FSDirectory.open(new File("e:/hadoop/hdpdata/lucene" ));
12 // 创建读取工具
13 IndexReader reader = DirectoryReader.open(directory);
14 // 创建搜索工具
15 IndexSearcher searcher = new IndexSearcher(reader);
16
17 QueryParser parser = new QueryParser("title", new StandardAnalyzer());
18 Query query = parser.parse("谷歌");
19
20 // 创建排序对象,需要排序字段SortField,参数:字段的名称、字段的类型、是否反转如果是false,升序。true降序
21 Sort sort = new Sort(new SortField("id", SortField.Type.LONG, false));
22 // 搜索数据,查询0~end条
23 TopDocs topDocs = searcher.search(query, end,sort);
24 int count = topDocs.totalHits;
25 System.out.println("本次搜索共" + count + "条数据"+"当前页: "+pageNum);
26
27 ScoreDoc[] scoreDocs = topDocs.scoreDocs;
28 for (int i = start; i < end; i++) {
29 if(i == count ){
30 return;
31 }
32 ScoreDoc scoreDoc = scoreDocs[i];
33 // 获取文档编号
34 int docID = scoreDoc.doc;
35 Document doc = reader.document(docID);
36 System.out.println("id: " + doc.get("id"));
37 System.out.println("title: " + doc.get("title"));
38 }
39 }
40
