一个成熟的数据库架构并不是一开始设计就具备高可用、高伸缩等特性的,它是随着用户量的增加,基础架构才逐渐完善。这篇文章主要谈谈MySQL数据库在发展周期中所面临的问题及优化方案,暂且抛开前端应用不说,大致分为以下五个阶段:
阶段一:数据库表设计
项目立项后,开发部门根据产品部门需求开发项目。
开发工程师在开发项目初期会对表结构设计。对于数据库来说,表结构设计很重要,如果设计不当,会直接影响到用户访问网站速度,用户体验不好!这种情况具体影响因素有很多,例如慢查询(低效的查询语句)、没有适当建立索引、数据库堵塞(锁)等。当然,有测试部门的团队,会做产品测试,找Bug。
由于开发工程师重视点不同,初期不会考虑太多数据库设计是否合理,而是尽快完成功能实现和交付。等项目上线有一定访问量后,隐藏的问题就会暴露,这时再去修改就不是这么容易的事了!
阶段二:数据库部署
是时候运维工程师出场了,项目上线。
项目初期访问量一般是寥寥无几,此阶段Web+数据库单台部署足以应对在1000左右的QPS(每秒查询率)。考虑到单点故障,应做到高可用性,可采用MySQL主从复制+Keepalived实现双机热备。主流HA软件有:Keepalived(推荐)、Heartbeat。
阶段三:数据库性能优化
如果将MySQL部署到普通的X86服务器上,在不经过任何优化情况下,MySQL理论值正常可以处理1500左右QPS,经过优化后,有可能会提升到2000左右QPS。否则,访问量当达到1500左右并发连接时,数据库处理性能可能响应就会慢,而且硬件资源还比较富裕,这时就该考虑性能优化问题了。那么怎样能让数据库发挥最大性能呢?主要从硬件配置、数据库配置、架构方面着手,具体分为以下:
3.1 硬件配置
如果有条件一定要SSD固态硬盘代替SAS机械硬盘,将RAID级别调整为RAID1+0,相对于RAID1和RAID5有更好的读写性能,毕竟数据库的压力主要来自磁盘I/O方面。
Linux内核有一个特性,会从物理内存中划分出缓存区(系统缓存和数据缓存)来存放热数据,通过文件系统延迟写入机制,等满足条件时(如缓存区大小到达一定百分比或者执行sync命令)才会同步到磁盘。也就是说物理内存越大,分配缓存区越大,缓存数据越多。当然,服务器故障会丢失一定的缓存数据。建议物理内存至少富裕50%以上。
3.2 数据库配置优化
MySQL应用最广泛的有两种存储引擎:一个是MyISAM,不支持事务处理,读性能处理快,表级别锁。另一个是InnoDB,支持事务处理(ACID属性),设计目标是为大数据处理,行级别锁。
表锁:开销小,锁定粒度大,发生死锁概率高,相对并发也低。
行锁:开销大,锁定粒度小,发生死锁概率低,相对并发也高。
为什么会出现表锁和行锁呢?主要为保证数据完整性。举个例子,一个用户在操作一张表,其他用户也想操作这张表,那么就要等第一个用户操作完,其他用户才能操作,表锁和行锁就是这个作用。否则多个用户同时操作一张表,肯定会数据产生冲突或者异常。
根据这些方面看,使用InnoDB存储引擎是最好的选择,也是MySQL5.5+版本默认存储引擎。每个存储引擎相关运行参数比较多,以下列出可能影响数据库性能的参数。
公共参数默认值:
2
3
4
5
6
7
2# 同时处理最大连接数,建议设置最大连接数是上限连接数的80%左右
3sort_buffer_size = 2M
4# 查询排序时缓冲区大小,只对order by和group by起作用,建议增大为16M
5open_files_limit = 1024
6# 打开文件数限制,如果show global status like 'open_files'查看的值等于或者大于open_files_limit值时,程序会无法连接数据库或卡死
7
MyISAM参数默认值:
2
3
4
5
6
7
8
9
10
11
2# 索引缓存区大小,一般设置物理内存的30-40%
3read_buffer_size = 128K
4# 读操作缓冲区大小,建议设置16M或32M
5query_cache_type = ON
6# 打开查询缓存功能
7query_cache_limit = 1M
8# 查询缓存限制,只有1M以下查询结果才会被缓存,以免结果数据较大把缓存池覆盖
9query_cache_size = 16M
10# 查看缓冲区大小,用于缓存SELECT查询结果,下一次有同样SELECT查询将直接从缓存池返回结果,可适当成倍增加此值
11
InnoDB参数默认值:
2
3
4
5
6
7
8
9
10
11
2# 索引和数据缓冲区大小,建议设置物理内存的70%左右
3innodb_buffer_pool_instances = 1
4# 缓冲池实例个数,推荐设置4个或8个
5innodb_flush_log_at_trx_commit = 1
6# 关键参数,0代表大约每秒写入到日志并同步到磁盘,数据库故障会丢失1秒左右事务数据。1为每执行一条SQL后写入到日志并同步到磁盘,I/O开销大,执行完SQL要等待日志读写,效率低。2代表只把日志写入到系统缓存区,再每秒同步到磁盘,效率很高,如果服务器故障,才会丢失事务数据。对数据安全性要求不是很高的推荐设置2,性能高,修改后效果明显。
7innodb_file_per_table = OFF
8# 是否共享表空间,5.7+版本默认ON,共享表空间idbdata文件不断增大,影响一定的I/O性能。建议开启独立表空间模式,每个表的索引和数据都存在自己独立的表空间中,可以实现单表在不同数据库中移动。
9innodb_log_buffer_size = 8M
10# 日志缓冲区大小,由于日志最长每秒钟刷新一次,所以一般不用超过16M
11
3.3 系统内核参数优化
大多数MySQL都部署在linux系统上,所以操作系统的一些参数也会影响到MySQL性能,以下对Linux内核参数进行适当优化
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2# TIME_WAIT超时时间,默认是60s
3net.ipv4.tcp_tw_reuse = 1
4# 1表示开启复用,允许TIME_WAIT socket重新用于新的TCP连接,0表示关闭
5net.ipv4.tcp_tw_recycle = 1
6# 1表示开启TIME_WAIT socket快速回收,0表示关闭
7net.ipv4.tcp_max_tw_buckets = 4096
8# 系统保持TIME_WAIT socket最大数量,如果超出这个数,系统将随机清除一些TIME_WAIT并打印警告信息
9net.ipv4.tcp_max_syn_backlog = 4096
10# 进入SYN队列最大长度,加大队列长度可容纳更多的等待连接
11在Linux系统中,如果进程打开的文件句柄数量超过系统默认值1024,就会提示“too many files open”信息,所以要调整打开文件句柄限制。
12重启永久生效:
13# vi /etc/security/limits.conf
14* soft nofile 65535
15* hard nofile 65535
16当前用户立即生效:
17# ulimit -SHn 65535
18
阶段四:数据库架构扩展
随着业务量越来越大,单台数据库服务器性能已无法满足业务需求,该考虑增加服务器扩展架构了。主要思想是分解单台数据库负载,突破磁盘I/O性能,热数据存放缓存中,降低磁盘I/O访问频率。
4.1 增加缓存
给数据库增加缓存系统,把热数据缓存到内存中,如果缓存中有请求的数据就不再去请求MySQL,减少数据库负载。缓存实现有本地缓存和分布式缓存,本地缓存是将数据缓存到本地服务器内存中或者文件中。分布式缓存可以缓存海量数据,扩展性好,主流的分布式缓存系统:memcached、redis,memcached性能稳定,数据缓存在内存中,速度很快,QPS理论可达8w左右。如果想数据持久化就选择用redis,性能不低于memcached。
工作过程: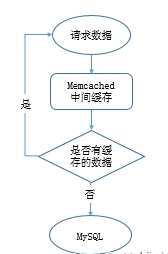
4.2 主从复制与读写分离
在生产环境中,业务系统通常读多写少,可部署一主多从架构,主数据库负责写操作,并做双机热备,多台从数据库做负载均衡,负责读操作。主流的负载均衡器:LVS、HAProxy、Nginx。
怎么来实现读写分离呢?大多数企业是在代码层面实现读写分离,效率高。另一个种方式通过代理程序实现读写分离,企业中应用较少,会增加中间件消耗。主流中间件代理系统有MyCat、Atlas等。
在这种MySQL主从复制拓扑架构中,分散单台负载,大大提高数据库并发能力。如果一台从服务器能处理1500 QPS,那么3台就能处理4500 QPS,而且容易横向扩展。
有时,面对大量写操作的应用时,单台写性能达不到业务需求。就可以做双向复制(双主),但有个问题得注意:两台主服务器如果都对外提供读写操作,就可能遇到数据不一致现象,产生这个原因是程序有同时操作两台数据库几率,同时的更新操作会造成两台数据库数据发生冲突或者不一致。
可设置每个表ID字段自增唯一:auto_increment_increment和auto_increment_offset,也可以写算法生成随机唯一。
官方近两年推出的MGR(多主复制)集群也可以考虑下。
4.3 分库
分库是根据业务将数据库中相关的表分离到不同的数据库中,例如web、bbs、blog等库。如果业务量很大,还可将分离后的数据库做主从复制架构,进一步避免单库压力过大。
4.4 分表
数据量的日剧增加,数据库中某个表有几百万条数据,导致查询和插入耗时太长,怎么能解决单表压力呢?你应该考虑把这个表拆分成多个小表,来减轻单个表的压力,提高处理效率,此方式称为分表。
分表技术比较麻烦,要修改程序代码里的SQL语句,还要手动去创建其他表,也可以用merge存储引擎实现分表,相对简单许多。分表后,程序是对一个总表进行操作,这个总表不存放数据,只有一些分表的关系,以及更新数据的方式,总表会根据不同的查询,将压力分到不同的小表上,因此提高并发能力和磁盘I/O性能。
分表分为垂直拆分和水平拆分:
垂直拆分:把原来的一个很多字段的表拆分多个表,解决表的宽度问题。你可以把不常用的字段单独放到一个表中,也可以把大字段独立放一个表中,或者把关联密切的字段放一个表中。
水平拆分:把原来一个表拆分成多个表,每个表的结构都一样,解决单表数据量大的问题。
4.5 分区
分区就是把一张表的数据根据表结构中的字段(如range、list、hash等)分成多个区块,这些区块可以在一个磁盘上,也可以在不同的磁盘上,分区后,表面上还是一张表,但数据散列在多个位置,这样一来,多块硬盘同时处理不同的请求,从而提高磁盘I/O读写性能。
注:增加缓存、分库、分表和分区主要由程序猿或DBA来实现。
阶段五:数据库维护
数据库维护是数据库工程师或运维工程师的工作,包括系统监控、性能分析、性能调优、数据库备份和恢复等主要工作。
5.1 性能状态关键指标
专业术语:QPS(Queries Per Second,每秒查询书)和TPS(Transactions Per Second)
通过show status查看运行状态,会有300多条状态信息记录,其中有几个值帮可以我们计算出QPS和TPS,如下:
2
3
4
5
6
7
8
9
2Questions:已经发送给数据库查询数
3Com_select:查询次数,实际操作数据库的
4Com_insert:插入次数
5Com_delete:删除次数
6Com_update:更新次数
7Com_commit:事务次数
8Com_rollback:回滚次数
9
那么,计算方法来了,基于Questions计算出QPS
2
3
4
2mysql> show global status like 'Uptime';
3QPS = Questions / Uptime
4
基于Com_commit和Com_rollback计算出TPS:
2
3
4
5
2mysql> show global status like 'Com_rollback';
3mysql> show global status like 'Uptime';
4TPS = (Com_commit + Com_rollback) / Uptime
5
另一计算方式:
2
3
4
2mysql> show global status where Variable_name in('com_select','com_insert','com_delete','com_update');
3等待1秒再执行,获取间隔差值,第二次每个变量值减去第一次对应的变量值,就是QPS。
4
TPS计算方法:
2
3
2计算TPS,就不算查询操作了,计算出插入、删除、更新四个值即可。
3
经网友对这两个计算方式的测试得出,当数据库中myisam表比较多时,使用Questions计算比较准确。当数据库中innodb表比较多时,则以Com_*计算比较准确。
5.2 开启慢查询日志
MySQL开启慢查询日志,分析出哪条SQL语句比较慢,支持动态开启:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2# 开启慢查询日志
3mysql> set global slow_query_log_file='/var/log/mysql/mysql-slow.log';
4# 指定慢查询日志文件位置
5mysql> set global log_queries_not_using_indexes=on;
6# 记录没有使用索引的查询
7mysql> set global long_query_time=1;
8# 只记录处理时间1s以上的慢查询
9分析慢查询日志,可以使用MySQL自带的mysqldumpslow工具,分析的日志较为简单。
10mysqldumpslow -t 3 /var/log/mysql/mysql-slow.log
11# 查看最慢的前三个查询
12也可以使用percona公司的pt-query-digest工具,日志分析功能全面,可分析slow log、binlog、general log。
13分析慢查询日志:pt-query-digest /var/log/mysql/mysql-slow.log
14分析binlog日志:mysqlbinlog mysql-bin.000001 >mysql-bin.000001.sql
15pt-query-digest --type=binlog mysql-bin.000001.sql
16分析普通日志:pt-query-digest --type=genlog localhost.log
17
5.3 数据库备份
备份数据库是最基本的工作,也是最重要的,否则后果很严重,你懂得!高频率的备份策略,选用一个稳定快速的工具至关重要。数据库大小在2G以内,建议使用官方的逻辑备份工具mysqldump。超过2G以上,建议使用percona公司的物理备份工具xtrabackup,否则慢的跟蜗牛似得。这两个工具都支持InnoDB存储引擎下热备,不影响业务读写操作。
5.4 数据库修复
有时候MySQL服务器突然断电、异常关闭,会导致表损坏,无法读取表数据。这时就可以用到MySQL自带的两个工具进行修复,myisamchk和mysqlcheck。前者只能修复MyISAM表,并且停止数据库,后者MyISAM和InnoDB都可以,在线修复。
注意:修复前最好先备份数据库。
2
3
4
5
6
7
8
9
10
2 -f --force 强制修复,覆盖老的临时文件,一般不使用
3 -r --recover 恢复模式
4 -q --quik 快速恢复
5 -a --analyze 分析表
6 -o --safe-recover 老的恢复模式,如果-r无法修复,可以使用此参数试试
7 -F --fast 只检查没有正常关闭的表
8
9例如:myisamchk -r -q *.MYI
10
2
3
4
5
6
7
8
9
10
11
2 -a --all-databases 检查所有的库
3 -r --repair 修复表
4 -c --check 检查表,默认选项
5 -a --analyze 分析表
6 -o --optimize 优化表
7 -q --quik 最快检查或修复表
8 -F --fast 只检查没有正常关闭的表
9
10例如:mysqlcheck -r -q -uroot -p123456 weibo
11
5.5 MySQL服务器性能分析
重点关注:
id:CPU利用率百分比,平均小于60%正常,但已经比较繁忙了。
wa:CPU等待磁盘IO响应时间,一般大于5说明磁盘读写量大。
KB_read/s、KB_wrtn/s 每秒读写数据量,主要根据磁盘每秒最高读写速度评估。
r/s、w/s:每秒读写请求次数,可以理解为IOPS(每秒输入输出量),是衡量磁盘性能的主要指标之一。
await:IO平均每秒响应时间,一般大于5说明磁盘响应慢,超过自身性能。
util:磁盘利用率百分比,平均小于60%正常,但已经比较繁忙了。
