首先介绍聚类中的层次聚类算法。层次法又分为凝聚的层次聚类和分裂的层次聚类。
凝聚的方法:也称自底向上的方法,首先将每个对象作为单独的一个聚类,然后根据性质和规则相继地合并相近的类,直到所有的对象都合并为一个聚类中,或者满足一定的终止条件。经典的层次凝聚算法以AGNES算法为代表,改进的层次凝聚算法主要以BIRCH,CURE,ROCK,CHAMELEON为代表。(后面详细介绍)
分裂的方法:也称自顶向下的方法,正好与凝聚法相反,首先将所有的对象都看作是一个聚类,然后在每一步中,上层类被分裂为下层更小的类,直到每个类只包含一个单独的对象,或者也满足一个终止条件为止。分裂算法将生成与凝聚方法完全相同的类集,只是生成过程的次序完全相反。经典的层次分裂算法以DIANA算法为代表。
AGNES算法
AGNES(AGglomerative NESting)
- 算法最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并
- 两个簇间的相似度由这两个不同簇中距离最近的数据点对的相似度来确定
- 聚类的合并过程反复进行直到所有的对象最终满足簇数目
算法过程
输入:n个对象,终止条件,簇的数目K
输出:K个簇,达到终止条件规定簇数目
- 将每个对象当成一个初始簇
- 根据两个簇中最近的数据点找到最近的两个簇
- 合并两个簇,生成新的簇的集合
- 直到达到定义的簇的数目
AGNES算法例题
| 序号 | 属性1 | 属性2 |
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 2 | 2 |
| 5 | 3 | 4 |
| 6 | 3 | 5 |
| 7 | 4 | 4 |
| 8 | 4 | 5 |
1 | 1 |
第1步:根据初始簇计算每个簇之间的距离,随机找出距离最小的两个簇进行合并,最小距离为1,合并后1,2两个点合并为一个簇。
第2步:对上一次合并后的簇计算簇间距离,找出距离最近的两个簇进行合并,合并后3,4两个点成为一个簇,
第3步:重复第2步,5,6点成为一个簇。
第4步:重复第2步,7,8点成为一个簇。
第5步:合并{1,2}、{3,4},使之成为一个包含4个点的簇。
第6步:合并{5,6}、{7,8},由于合并后的簇的数目达到用户输入的终止条件,程序终止。
| 步骤 | 最近的簇距离 | 最近的两个簇 | 合并后的新簇 |
| 1 | 1 | {1}、{2} | {1、2}、{3}、{4}、{5}、{6}、{7}、{8} |
| 2 | 1 | {3}、{4} | {1、2}、{3、4}、{5}、{6}、{7}、{8} |
| 3 | 1 | {5}、{6} | {1、2}、{3、4}、{5、6}、{7}、{8} |
| 4 | 1 | {7}、{8} | {1、2}、{3、4}、{5、6}、{7、8} |
| 5 | 1 | {1、2}、{3、4} | {1、2、3、4}、{5、6}、{7、8} |
| 6 | 1 | {5、6}、{7、8} | {1、2、3、4}、{5、6、7、8} |
1 | 1 |
AGNES特点:
AGNES实现简单,但经常会遇到合并点难以选择的困难。若一旦一组对象被合并,下一步的处理将在新生成的簇上进行。已经做的处理不能撤销,聚类之间也不能交换对象。一步合并错误,可能会导致低质量的聚类结果。
层次凝聚改进算法之BIRCH算法
转载了大牛的博客,在理解MinCluster时,个人觉得树图中最底一层的每一个椭圆形都是一个MinCluster,并不是一个Leaf的所有孩子为一个MinCluster。所以MinCluster的个数不会超过L个,与树图吻合。
转自:http://www.kuqin.com/algorithm/20111016/312976.html
http://www.cnblogs.com/zhangchaoyang/articles/2200800.html
层次凝聚改进算法之CURE算法
绝大多数聚类算法或者擅长处理球形与相似大小的聚类,或者在存在孤立点时变得比较脆弱。CURE( Clustering Using Representatives)算法较好的解决了偏好球形和相似大小的问题,在处理孤立点上也更加健壮。CURE 算法采用了一种新颖的层次聚类算法,该算法选择基于质心和基于代表对象方法之间的中间策略。它不用单个质心或对象来代表一个簇,而是选择数据空间中固定数目的具有代表性的点。每一个簇有多于一个的代表点使得 CURE 可以适应非球形的几何形状。簇的收缩或凝聚可以有助于控制孤立点的影响。因此,CURE 对于孤立点的处理更加好,而且能够识别非球形和大小变化较大的簇。对于大型数据库,它也具有良好的伸缩性,而且没有牺牲聚类质量。针对大型数据库,CURE 采用随机取样和划分两种方法的结合:一个随机样本首先被划分,每个划分被部分聚类。这些结果簇然后被聚类产生希望的结果。
基本步骤:
⑴ 对数据库抽样,得到一个样本;
⑵ 将样本划分为 p 个分区,每个分区的规模为n/p。因为聚类首先在每个分区上进行,所以这样做可以起到加速算法的作用;
⑶ 对每一分区,利用层次算法进行聚类。这提供了关于簇的组成的首次猜测。簇的数目为 n/pq,其中 q为某一常数;
⑷ 删除异常点。利用两种不同的技术删除异常点。第一种技术是将增长缓慢的簇删除。当簇的数目低于某一阈值时,将仅含有一两个成员的簇删除。有可能较近的异常点会成为样本的一部分,而不能被第一种异常点删除技术识别出来。第二种技术是在聚类的最后阶段,将非常小的簇删除;
⑸ 为了保证可以在内存中处理,输入只包括在步骤 3 中各个分区独自聚类时发现的簇的代表性点;
⑹ 使用 c 个点代表每个簇,对磁盘上的整个数据库进行聚类。数据库中的数据项被分配到与其最近的
代表性点表示的簇中。代表性点的集合必须足够小以适应主存的大小,所以 n 个点中的每一个都要与 ck 个代表性点相比较。
层次凝聚改进算法之ROCK算法
ROCK(Robust Clustering using links)算法采用一种新方法来计算相似形,即基于元组之间的连接数目。如果一对元组的相似形超过某一阈值,则称这一对元组为邻居。两个元组之间的连接数目由它们共同的邻居数目来定义。ROCK 属于层次凝聚算法,其相似性度量采用的是连接数目而不是距离的量度。首先数据库中的数据随机取出作为样本,使用“link”将数据进行聚类,最后将数据库中的其余数据指派到样本数据完成的簇中,得到最终的聚类结果。
为了进一步了解ROCK算法,我们需要定义几个变量,并阐述这些变量的含义。
定义1.Θ为使用者自定义的邻居阈值,相似度函数sim(pi,pj)>=Θ,其中sim(pi,pj)的相似度取值范围为[0,1],值越大表示越相似。
定义2.pi,pj这两个数点的相似度采用Jaccard系数,则sim(pi,pj)=(pi∩pj)/(piUpj)。
定义3.link pi¯,pj¯为集合Ni,Nj交叉连接数,其中Ni,Nj分别为pi,pj的邻居表。
定义4.适合函数(goodness function)
g(Ci,Cj)=link[Ci,Cj]/((ni+nj)1+2f(θ)-ni1+2f(θ)-nj1+2f(θ)),其中Ci,Cj是两个簇,ni,nj分别是两个簇中的点的数目,假设以Ci为参考点,每个点概略
有nif(θ),专家选择的阈值是:f(θ)=(1-θ)/(1+θ)
层次凝聚改进算法之Chameleon
Chameleon采用动态建模来确定一对簇之间的相似度。
在Chameleon中簇的相似度依据如下两点评估:
- 簇中对象的连接情况
- 簇的邻近性
也就是说,如果两个簇的互连性都很高并且它们又很靠近就将其合并。
Chameleon算法的思想是:
- 首先使用一种图划分算法将k最近邻图划分成大量相对较小的子簇
- 然后使用凝聚层次聚类算法,基于子簇的相似度反复地合并子簇
- 为了确定最相似的子簇对,它既考虑每个子簇的互连性,又考虑簇的邻近性
- 图划分算法划分k最近邻图,使得割边最小化。也就是说,簇C划分为两个子簇Ci,Cj时需要切断的加权和最小。割边用EC(Ci,Cj)表示,用于评估簇Ci,Cj之间的绝对互连性。
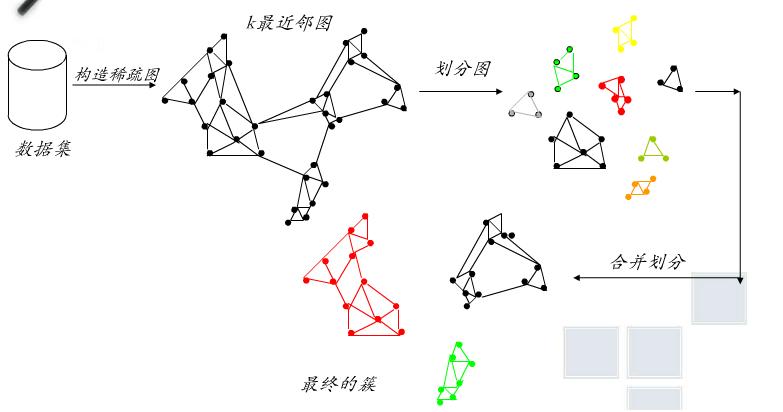
图1 Chameleon工作过程图
优点:Chameleon在发现高质量的任意形状的簇方面具有很强的能力。
缺点:高维数据的处理代价较高,对n个对象最坏情况下需要O(n2)的时间。
聚类算法层次分裂之DIANA
算法思想:
输入:n个对象,终止条件簇的数目k
输出:k个簇,达到终止条件规定簇数目
- 将所有对象当成一个初始簇
- for(i=1;i≠k;i++) do begin
- 在所有簇中挑选出具有最大直径的簇C
- 找出C中与其它点平均相异度最大的一个点P并把P放入splinter group,剩余的放在old party中
- repeat
- 在old party中找出到最近的splinter group中的点的距离不大于到old party中最近点的距离的点,并将该点加入splinter group
- until没有新的old party的点被分配给spilnter group
- spilnter group和old party为被选中的簇分裂成的2个簇与其它簇一起组成新的簇集合
- end
分裂的层次聚类算法一般较少使用。
