文章目录
-
- PageRank算法
-
- TextRank算法提取关键词
-
- TextRank算法提取关键词短语
-
- TextRank生成摘要
-
- 共现矩阵
$~~~~~~~~$今天要介绍的TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要。因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法。
1. PageRank算法
PageRank设计之初是用于Google的网页排名的,以该公司创办人拉里·佩奇(Larry Page)之姓来命名。Google用它来体现网页的相关性和重要性,在搜索引擎优化操作中是经常被用来评估网页优化的成效因素之一。PageRank通过互联网中的超链接关系来确定一个网页的排名,其公式是通过一种投票的思想来设计的:如果我们要计算网页A的PageRank值(以下简称PR值),那么我们需要知道有哪些网页链接到网页A,也就是要首先得到网页A的入链,然后通过入链给网页A的投票来计算网页A的PR值。这样设计可以保证达到这样一个效果:当某些高质量的网页指向网页A的时候,那么网页A的PR值会因为这些高质量的投票而变大,而网页A被较少网页指向或被一些PR值较低的网页指向的时候,A的PR值也不会很大,这样可以合理地反映一个网页的质量水平。那么根据以上思想,佩奇设计了下面的公式:
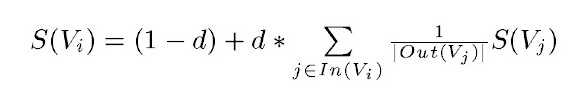
该公式中,V
i表示某个网页,V
j表示链接到Vi的网页(即V
i的入链),S(V
i)表示网页V
i的PR值,In(V
i)表示网页V
i的所有入链的集合,Out(V
j)表示网页,d表示阻尼系数,是用来克服这个公式中“d *”后面的部分的固有缺陷用的:如果仅仅有求和的部分,那么该公式将无法处理没有入链的网页的PR值,因为这时,根据该公式这些网页的PR值为0,但实际情况却不是这样,所有加入了一个阻尼系数来确保每个网页都有一个大于0的PR值,根据实验的结果,在0.85的阻尼系数下,大约100多次迭代PR值就能收敛到一个稳定的值,而当阻尼系数接近1时,需要的迭代次数会陡然增加很多,且排序不稳定。公式中S(V
j)前面的分数指的是V
j所有出链指向的网页应该平分V
j的PR值,这样才算是把自己的票分给了自己链接到的网页。
2. TextRank算法提取关键词
TextRank是由PageRank改进而来,其公式有颇多相似之处,这里给出TextRank的公式:
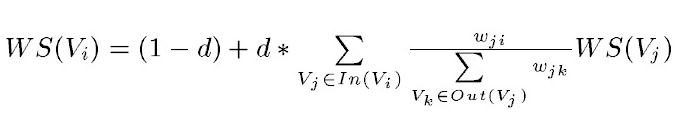
可以看出,该公式仅仅比PageRank多了一个权重项W
ji,用来表示两个节点之间的边连接有不同的重要程度。TextRank用于关键词提取的算法如下:
$~~~~~~~~$ 1)把给定的文本T按照完整句子进行分割
$~~~~~~~~$ 2)对于每个句子进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词。
$~~~~~~~~$ 3)构建候选关键词图G = (V,E),其中V为节点集,由(2)生成的候选关键词组成,然后采用共现关系(co-occurrence)构造任两点之间的边(下面会讲),两个节点之间存在边仅当它们对应的词汇在长度为K的窗口中共现,K表示窗口大小,即最多共现K个单词。
4)根据上面公式,迭代传播各节点的权重,直至收敛。
5)对节点权重进行倒序排序,从而得到最重要的T个单词,作为候选关键词。
6)由5得到最重要的T个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
3. TextRank算法提取关键词短语
提取关键词短语的方法基于关键词提取,可以简单认为:如果提取出的若干关键词在文本中相邻,那么构成一个被提取的关键短语。
4. TextRank生成摘要
将文本中的每个句子分别看做一个节点,如果两个句子有相似性,那么认为这两个句子对应的节点之间存在一条无向有权边。考察句子相似度的方法是下面这个公式:
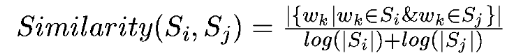
公式中,S
i,S
j分别表示两个句子,W
k表示句子中的词,那么分子部分的意思是同时出现在两个句子中的同一个词的个数,分母是对句子中词的个数求对数之和。分母这样设计可以遏制较长的句子在相似度计算上的优势。
我们可以根据以上相似度公式循环计算任意两个节点之间的相似度,根据阈值去掉两个节点之间相似度较低的边连接,构建出节点连接图,然后计算TextRank值,最后对所有TextRank值排序,选出TextRank值最高的几个节点对应的句子作为摘要。
5. 共现矩阵
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
2get_set_key returns:
3['f', 'd', 'c', 'a', 'b']
4-------------------------------------------------------------------
5Document:格式化需要计算的数据,将原始数据格式转换成二维数组
6format_data returns:
7[['a', 'b', 'c'], ['b', 'a', 'f'], ['a', 'd', 'c']]
8-------------------------------------------------------------------
9Document:建立矩阵,矩阵的高度和宽度为关键词集合的长度+1
10build_matirx returns:
11[['' '' '' '' '' '']
12 ['' '' '' '' '' '']
13 ['' '' '' '' '' '']
14 ['' '' '' '' '' '']
15 ['' '' '' '' '' '']
16 ['' '' '' '' '' '']]
17-------------------------------------------------------------------
18Document:初始化矩阵,将关键词集合赋值给第一列和第二列
19init_matrix returns:
20[['' 'f' 'd' 'c' 'a' 'b']
21 ['f' '' '' '' '' '']
22 ['d' '' '' '' '' '']
23 ['c' '' '' '' '' '']
24 ['a' '' '' '' '' '']
25 ['b' '' '' '' '' '']]
26-------------------------------------------------------------------
27Document:计算各个关键词共现次数
28count_matrix returns:
29[['' 'f' 'd' 'c' 'a' 'b']
30 ['f' '0' '0' '0' '1' '1']
31 ['d' '0' '0' '1' '1' '0']
32 ['c' '0' '1' '0' '2' '1']
33 ['a' '1' '1' '2' '0' '2']
34 ['b' '1' '0' '1' '2' '0']]
35
36
