文章目录
-
写在前面
-
- NCF 原理
-
1.1 GMF模型
- 1.2 MLP
- 1.3 NeuMF
-
- 几个重点
-
2.1 显性反馈和隐性反馈
- 2.2 逐点损失和成对损失
- 2.2 正例和负例的选择
- 2.3 训练集和测试集的划分
- 2.4 预训练机制
-
- LFM和NCF的区别
-
3.1 概述
- 3.2 相同点
- 3.3 不同点
-
3.3.1 建模思想
* 3.3.2 求解结果
* 3.3.3 泛化能力
* 3.3.4 实现方法
* 3.3.5 学习能力 -
- 大家一起找茬
-
4.1 user embedding & item embedding
- 4.2 泛化能力
-
- keras手撸ncf
-
引用
-
公众号
写在前面
这篇文章发表在《World Wide Web》(2017)上,论文链接:https://arxiv.org/pdf/1708.05031.pdf
文章提出,神经网络已经被证明可以近似模拟任意连续函数[1],并且深度学习在很多领域的成功应用也证明了其有效性。而一些近期的研究也将深度学习应用到了推荐中,然而很多工作都是将深度学习作为辅助工作,比如提取文本和图像的特征,而对于推荐的关键特征处理,user特征和item特征的交互,仍使用MF的思想。
作者利用深度学习来对user和item特征进行建模,使模型具有非线性表达能力。具体来说使用多层感知机来学习user-item交互函数。
1. NCF 原理
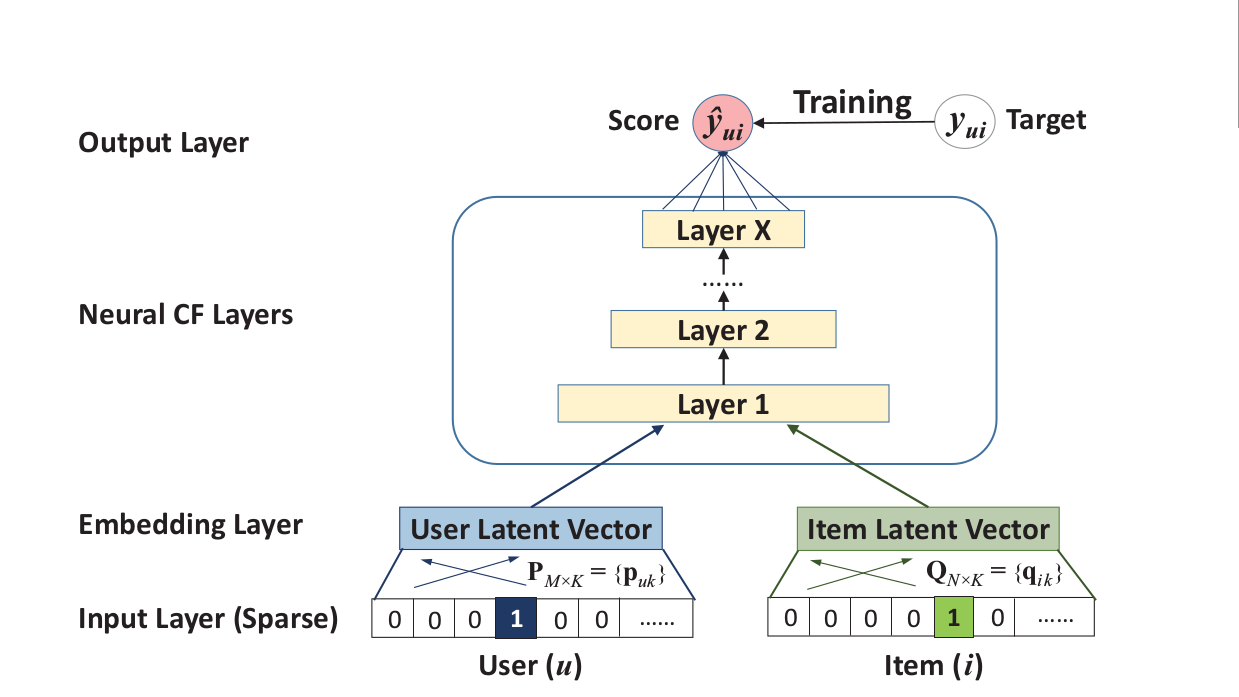
这是论文中给出的NCF的通用框架,试验中使用one-hot编码进行映射为user和item latent vector,然后输入到MLP中进行训练。这个user和item可以泛化地理解,比如使用基于内容的方式,就可以去解决冷启动问题。
个人拙见,论文中的NCF通用模型并不能实例化成论文中说的GMF,因为通用模型中讲了是利用多层感知机,而GMF显然和这没什么关系。并且GMF那部分只证明了MF是GMF的特例,而不能证明GMF是NCF的特例。
1.1 GMF模型
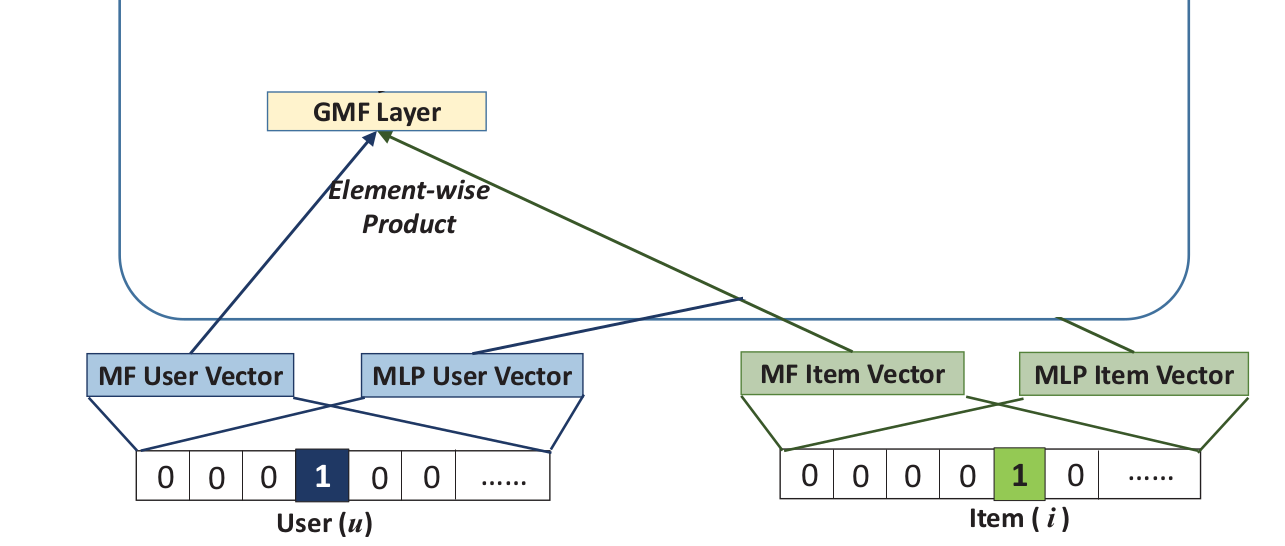
从论文中的解释看,user和item都通过one-hot编码得到稀疏向量,然后通过一个embedding层映射为user vector和item vector。这样就获得了user和item的隐向量,就可以使用哈达马积(Element-wise Produce)来交互user和item向量了。不过后面多了一个全连接层:
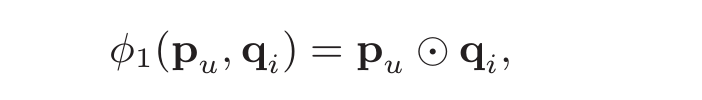
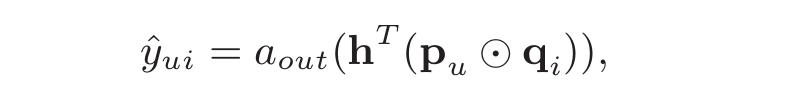
我们可以发现,LFM模型的user和item隐向量是随机初始化然后训练出来,而这里是使用one-hot稀疏向量做embedding映射。
1.2 MLP
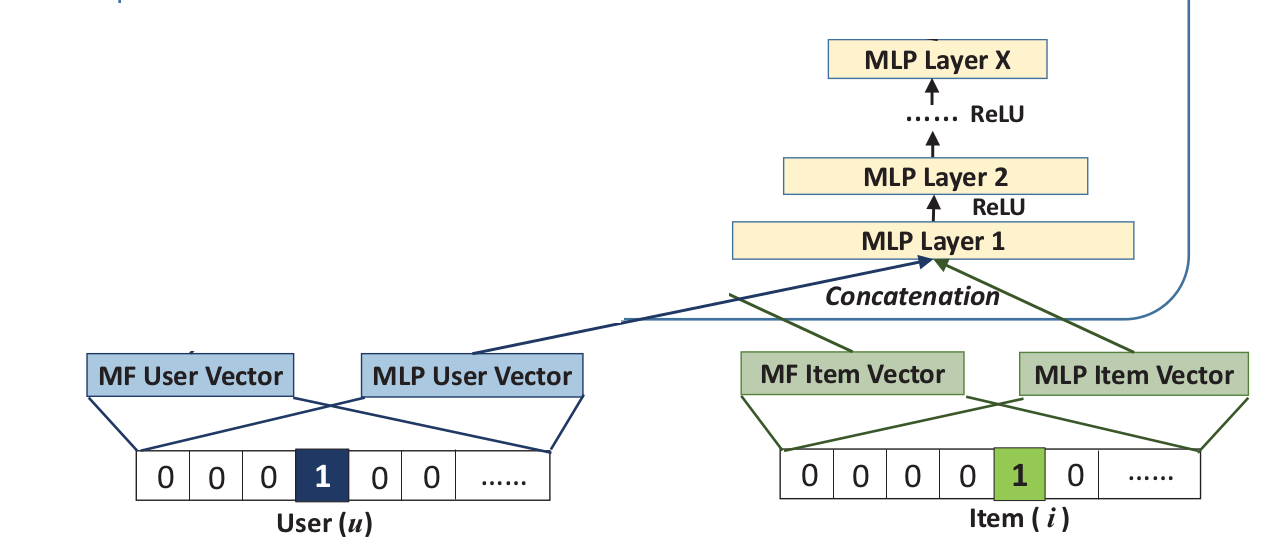
这里同样先通过映射获得user和item vector,但要注意,之前的MF vector和MLP vector虽然同为映射的向量,但绝对不一样,因为模型对隐向量的维度等要求是不一样的。
然后将user和item vector输入到MLP中进行训练,MLP大家都知道,重点是如何处理user和item vector,作者是直接将两个向量串联起来。文中指出这是借鉴了多模态中的做法,我之前做过点多模态的研究,实际上,多模态中这是最常见的一种做法,还有很多其他方式,比如简单的串联后加个正则,或者找个建模能力更强的神经网络模型(可能需要自己设计)。作者在当时采用的这种直接串联的方式虽然简单,但是可以说是个“划时代”的做法。
这样串联起来后,输入到MLP中,可以学习出user和item之间的非线性交互函数。具体MLP过程是这么做的:
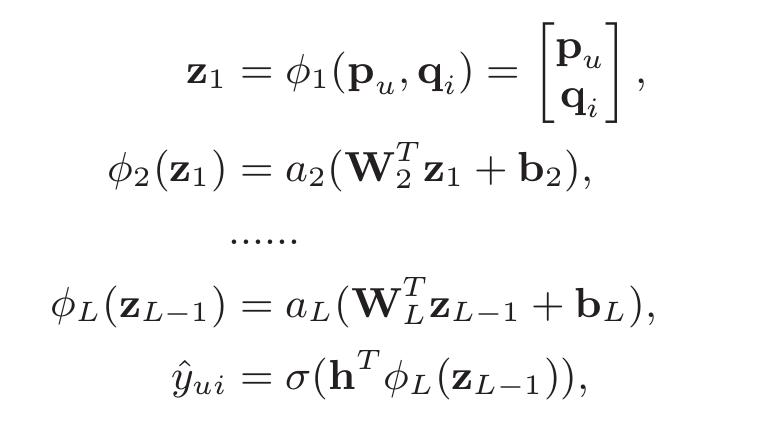
1.3 NeuMF
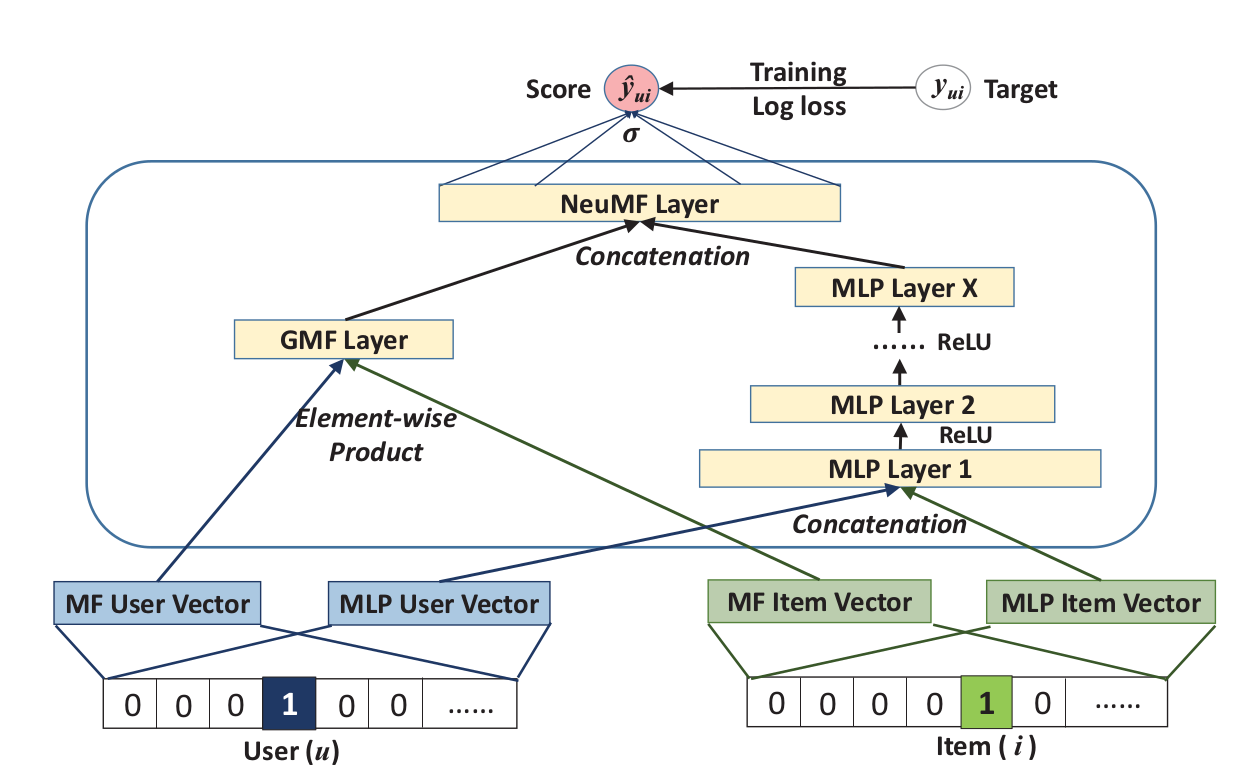
上图所示的框架被称为“Neural matrix factorization model”,简称为NeuMF。但实际上,提起NCF可能我们想到的就是这个模型,有时候和别人交流,说的NCF就是指这个模型。
首先想到的是将两个模型进行结果融合,就是将两个模型的“输出”结果相加后套个激活函数,然后加一层感知机获得最终结果:
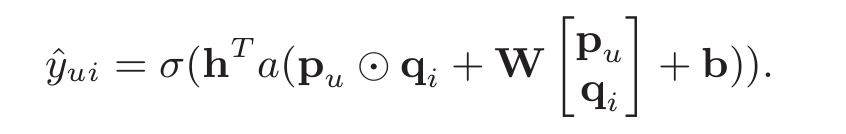
个人拙见,即使进行结果融合也应该将MF的部分放在a(wx+b)的外部,最后一起加一层感知机。毕竟wx+b加上激活函数才是MLP倒数第二层的输出。不知道为什么要写在一个括号里。可能是实验效果更好?
其实无所谓,这个公式已经被作者鄙视后抛弃。因为这种共享最后一层嵌入层的方式可能限制模型的表达性能。看公式就知道,嵌入层的输入要求pq和wx+b具有相同的维度,才能进行向量相加。
之前讲过,不能强行要求GMF和MLP在输入时的隐向量维度一致,毕竟是两个不同的模型,所以分别做embedding。现在对两个模型的“输出”也不能做这种要求,因此作者想了个更好的办法:将两个模型的倒数第二层特征串联为一个特征,然后加层感知机:
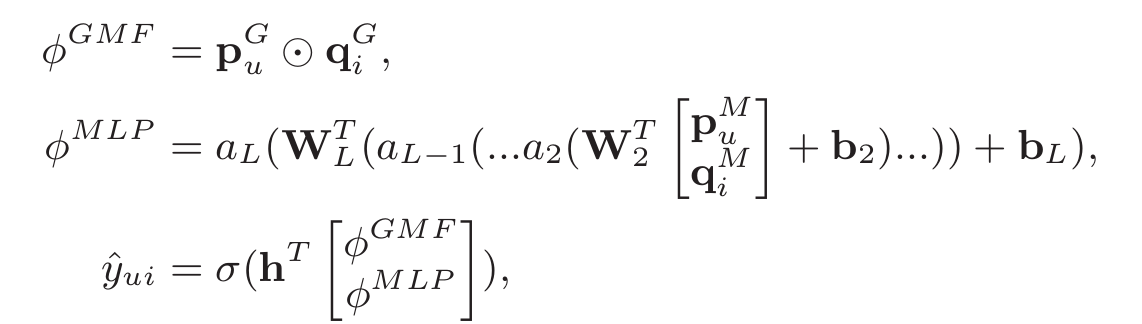
实际上,h是个权重向量,相当于对两个模型倒数第二层的结果进行加权。我们知道,集成模型中一般对最后一层的输出结果进行加权,现在换成倒数第二层,就变成了“特征”融合,最后的performance肯定也是大不相同的。
2. 几个重点
2.1 显性反馈和隐性反馈
NCF专注于专注于隐性反馈,通过参考观看视频,购买产品和点击项目等间接反映用户偏好的行为。无论你是评过分,收藏过,看过有关内容,都可以作为隐性反馈。与显性反馈(评分和评级)不同,隐性反馈可以更容易收集。
对于有评分这样的显性反馈,有评分就用,没有评分的数据也要处理,一般就是记分值为0。而对于隐性反馈,为了处理没有观察到的数据,可以将所有无交互的条目视为负反馈,也可以从中抽样作为负反馈实例,NCF中也记为0。
令 ? 和 ? 分别表示用户和项目的数量,通过从用户的隐性反馈学习user-item交互矩阵:

这里y为 1 表示用户 ? 和项目 ? 存在交互记录;然而这并不意味着 ? 真的喜欢 ?。同样的,值 0 也不是表明 ? 不喜欢 ?,也有可能是这个用户根本不知道有这个项目。这对隐性反馈的学习提出了挑战,因为它提供了关于用户偏好的噪声信号。虽然观察到的条目至少反映了用户对项目的兴趣,但是未查看的条目可能只是丢失数据,并且这其中存在自然稀疏的负反馈[2]。显然隐性反馈不能反映用户的满意度,还是显性的评分更好用。
2.2 逐点损失和成对损失
文献中常用的有两种函数:逐点损失(pointwise loss)和成对损失(pairwise loss)。逐点损失一般通过最小化预测值y和目标值y之间的平方误差,使用回归的框架来估计参数。而成对损失的思想是观察到的条目应该比未观察到的条目的评分更高,推荐看一看BPR(Bayesian personalized ranking)更进一步了解pairwise loss。
考虑到隐性反馈的一类性质,我们可以将 ??? 的值作为一个标签————1表示项目 ? 和用户 ? 相关,否则为0。这样一来预测分数 ?ˆ?? 就代表了项目 ? 和用户 ? 相关的可能性大小。为了赋予NCF这样的概率解释,我们需要将网络输出限制到[0,1]的范围内,通过使用概率函数(e.g. 逻辑函数sigmoid或者probit函数)作为激活函数作用在输出层 ??? ,我们可以很容易地实现数据压缩。经过以上设置后,我们这样定义似然函数[2]:
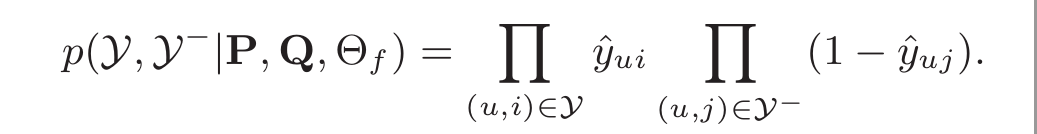
上面的这段解释实在是经典。这句话对理解逻辑回归中的损失函数也有帮助。《传统推荐算法(五) FFM模型(1) 逻辑回归损失函数》中我们讲了获得似然函数后如何推导最小化损失函数,这里不再多说,极小化损失函数的表达式是:
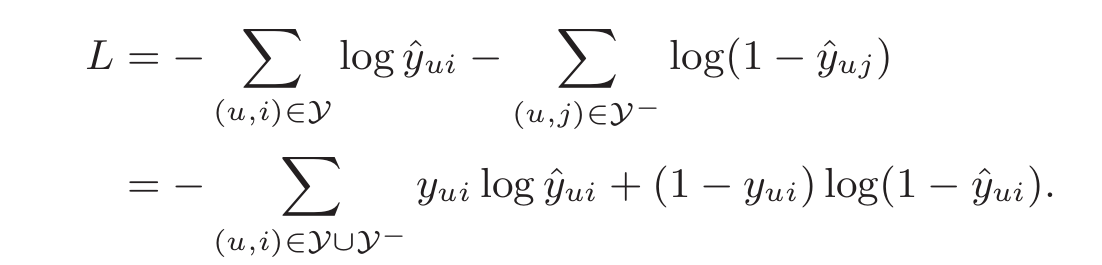
2.2 正例和负例的选择
NCF使用逐点损失函数,为了处理没有观察到的数据,要么将所有未观察到的条目视作负反馈,要么从没有观察到条目中抽样作为负反馈实例。而正例就是那些有记录的交互。
2.3 训练集和测试集的划分
论文使用留一机制,就是将用户最近的那次交互作为测试集,当然交互的物品基本不会相同,比如用户1是25,用户2是133。
测试的时候,并不排列所有的item,而是抽样100个做top k(比如10)推荐,只要测试的物品在top 10里就算推荐成功。当然了,为了防止随机抽样没有抽中测试的那个物品(肯定推荐不到),论文从无交互的物品中抽样99个,加上测试的物品,凑成100个,做top10推荐。然后计算HR和NDCG指标的值做评估。
2.4 预训练机制
首先单独使用GMF和MLP进行训练,并获得最后感知机层的权重和偏置项,然后将这些参数用来初始化NeuMF中GMF和MLP部分。当然,给了一个$\alpha$控制两个权重的贡献。
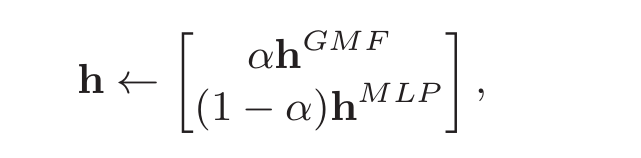
3. LFM和NCF的区别
3.1 概述
LFM常用的实现方式是基于矩阵分解技术,通过损失函数加正则的反向梯度下降来优化模型参数。求解出来的是用户-隐类矩阵和物品-隐类矩阵,可以理解为物品对各隐类的偏爱程度和物品对各隐类的归属程度。最后求出这两个矩阵,然后就可以计算用户对物品的评分。
NCF是通过神经网络从数据中学习用户和物品的交互关系,最后要训练出一个模型。
3.2 相同点
核心思想都是模拟用户和物品间的交互关系。
都可以使用梯度下降来求解参数。
3.3 不同点
3.3.1 建模思想
LFM通过隐特征将用户与物品联系起来,求解能最大似然联系用户和物品的隐空间的特征表达,而NCF使用NN来学习用户和物品的交互函数,其中包括隐特征的求解过程(one-hot到隐特征的映射关系);
3.3.2 求解结果
LFM求解的是用户-隐类矩阵和物品-隐类矩阵,而NCF求解得到的是一个模型;
3.3.3 泛化能力
lfm只能根据两个矩阵,计算已出现的用户和已出现但没评分的物品的评分,只能填补原先用户-物品矩阵的空白,ncf的模型是通用的,可以计算新用户和新物品(这里能实现的原因是ncf在输入层有一个映射层,学得参数后可以获得一个通用映射关系,可以映射新用户或新物品到隐特征空间,而lfm新用户新物品没法获得隐特征向量的表示形式)。
3.3.4 实现方法
lfm实现方式最广的是矩阵分解(也是它的思想来源)加梯度下降。其中的优化过程,矩阵分解的优化可以使用梯度下降,也可以使用最小二乘法。而ncf实现过程论文给出了,神经网络协同过滤用梯度下降。
3.3.5 学习能力
lfm只考虑了各隐类间的线性关系,隐类间一般都是非线性关系的尤其是在隐类数较少的时候;ncf结合一个推广的矩阵分解GMF,考虑各隐类间的线性关系的同时,还使用MLP来学习用户和物品间潜在特征之间的非线性关系。非常灵活。
4. 大家一起找茬
4.1 user embedding & item embedding
像论文中所说的,用户只有id信息时,通过id来进行映射是否有必要呢?这个id是人为赋予,id只能帮我们记录是哪个用户,本身不含有任何信息,实际上,数组下标可以一一对应,已经可以帮助我们记录是哪个用户。
当然,论文中考虑了这点,并说明底部输入层的两个user和item向量,可以进行定制,用以支持广泛的user和item的建模,比如上下文感知,基于内容等。
但是,只有id的情况下,和LFM的训练类似,隐性向量随机初始化已经足够了。感兴趣可以自己做下实验。
4.2 泛化能力
正如之前所说,如果user和item只有id的情况下,这个模型泛华能力太弱。因为id本身包含的信息太少,无论新来的是哪个用户,id都是第k个,获得的user latent vector都是同一个,item同理。
因此,如果只考虑user-item这样的评分矩阵,NCF的泛华能力有待商榷(和LFM有一拼,至少还能embedding一个隐向量出来),但是考虑到论文所说的,两个user和item向量,可以进行定制,比如user是一串文本来表示,那就有泛化能力。
5. keras手撸ncf
论文作者给了python2源码:
https://github.com/hexiangnan/neural_collaborative_filtering我的实验环境:
keras: 2.6.4
python: 3.6.4
numpy: 1.14.0可能版本不对,跑的时候有很多错,我改了些错并改成python3版本:
https://github.com/wyl6/Recommender-Systems-Samples/tree/master/RecSys%20And%20Deep%20Learning/DNN/ncf
引用
[1] Hornik, K., Stinchcombe, M., & White, H. (1989). Multilayer feedforward networks are universal approximators. Neural networks, 2(5), 359-366.
