释放双眼,带上耳机,听听看~!
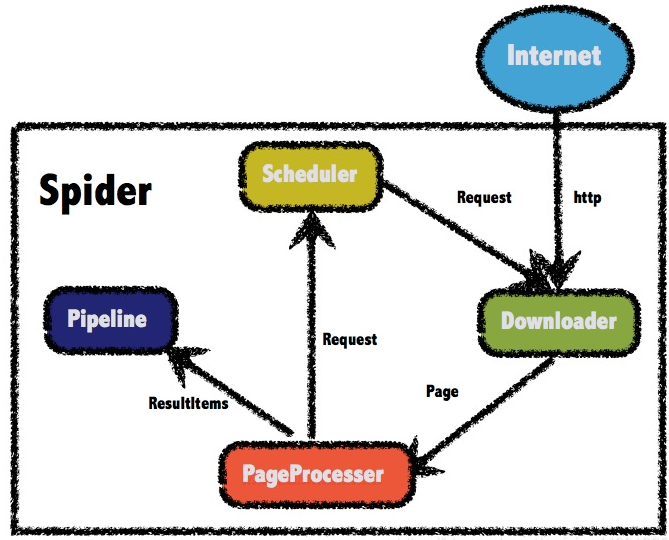
1.原理图
2.依赖
2
3
4
5
6
7
8
9
10
11
2 <groupId>us.codecraft</groupId>
3 <artifactId>webmagic-core</artifactId>
4 <version>0.7.3</version>
5 </dependency>
6 <dependency>
7 <groupId>us.codecraft</groupId>
8 <artifactId>webmagic-extension</artifactId>
9 <version>0.7.3</version>
10 </dependency>
11
3.爬取处理器
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
2import org.springframework.stereotype.Component;
3import us.codecraft.webmagic.Page;
4import us.codecraft.webmagic.Site;
5import us.codecraft.webmagic.Spider;
6import us.codecraft.webmagic.processor.PageProcessor;
7import us.codecraft.webmagic.scheduler.BloomFilterDuplicateRemover;
8import us.codecraft.webmagic.scheduler.QueueScheduler;
9import us.codecraft.webmagic.selector.Html;
10import us.codecraft.webmagic.selector.Selectable;
11
12import java.util.List;
13
14
15public class JobProcessor implements PageProcessor {
16 //前程无忧网站的职位列表地址
17 private static String url = "https://search.51job.com/list/170200,000000,0000,00,9,99,%2B,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99&degreefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=";
18 private Site site = Site.me()
19 .setCharset("gbk")//设置编码(页面是什么编码就设置成什么编码格式的)
20 .setTimeOut(10 * 1000)//设置超时时间
21 .setRetrySleepTime(3000)//设置重试的间隔时间
22 .setRetryTimes(3);//设置重试的次数
23
24 @Override
25 public void process(Page page) {
26 //解析页面,获取招聘信息详情的url地址
27 List<Selectable> list = page.getHtml().css("div#resultList div.el").nodes();
28 //判断集合是否为空
29 if (list.size() == 0) {
30 //如果为空,表示这是招聘详情页,解析页面,获取招聘详情信息,保存数据
31 this.saveJobInfo(page);
32 } else {
33 //如果不为空,表示这是列表页,解析出详情页的url地址,放到任务队列中
34 for (Selectable selectable : list) {
35 String jobInfoUrl = selectable.links().toString();
36 //把获取到的详情页的url地址放到任务队列中
37 page.addTargetRequest(jobInfoUrl);
38 }
39 //获取下一页按钮的url
40 String bkUrl = page.getHtml().css("div.p_in li.bk").nodes().get(1).links().toString();//get(1)拿到第二个
41 //把下一页的url放到任务队列中
42 page.addTargetRequest(bkUrl);
43 }
44 }
45
46 private void saveJobInfo(Page page) {
47 //拿到解析的页面,可通过css选择器,xpath,或id选择器等获取需要的元素
48 Html html = page.getHtml();
49 JobInfo jobInfo = new JobInfo();
50 jobInfo.setCompanyName(html.css("div.cn p.cname a", "text").toString());
51 String addrStr = Jsoup.parse(html.css("div.cn p.msg").toString()).text();//Jsoup.parse解析html字符串
52 String addr = addrStr.substring(0, addrStr.indexOf("|"));
53 jobInfo.setCompanyAddr(addr);
54 jobInfo.setCompanyInfo(html.css("div.tmsg", "text").toString());
55 jobInfo.setJobName(Jsoup.parse(html.css("div.cn h1", "title").toString()).text());
56 jobInfo.setJobAddr(addr);
57 jobInfo.setSalary(Jsoup.parse(html.css("div.cn strong").toString()).text());
58 // html.html.$("#languagelist").css("div.cn strong").xpath("//strong/text()");
59 //把结果保存起来,pipeline的ResultItems对象可取出该数据
60 page.putField("jobInfo", jobInfo);
61 }
62
63 @Override
64 public Site getSite() {
65 return site;
66 }
67
68
69 public static void main(String[] args) {
70
71 Spider.create(new JobProcessor())
72 .addUrl(url)
73 .setScheduler(new QueueScheduler().setDuplicateRemover(new BloomFilterDuplicateRemover(100000)))
74 .thread(10)
75 .addPipeline(new MyPipeline())
76 .run();
77 }
78}
79
80
4.爬取数据处理的pipeline,将数据存入DB或其它处理
2
3
4
5
6
7
8
9
10
11
2 @Override
3 public void process(ResultItems resultItems, Task task) {
4 JobInfo jobInfo=resultItems.get("jobInfo");
5 if(jobInfo!=null){
6 System.out.println("存入DB" );
7 }
8 }
9}
10
11
参考:https://blog.csdn.net/weixin_44001965/article/details/102535797
