MySQL扩展具体的实现方式
随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量。
关于数据库的扩展主要包括:业务拆分、主从复制,数据库分库与分表。文章主要讲述数据库分库与分表
(1)业务拆分
业务起步初始,为了加快应用上线和快速迭代,很多应用都采用集中式的架构。随着业务系统的扩大,系统变得越来越复杂,越来越难以维护,开发效率变得越来越低,并且对资源的消耗也变得越来越大,通过硬件提高系统性能的方式带来的成本也越来越高。
因此,在选型初期,一个优良的架构设计是后期系统进行扩展的重要保障。
例如:电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表。
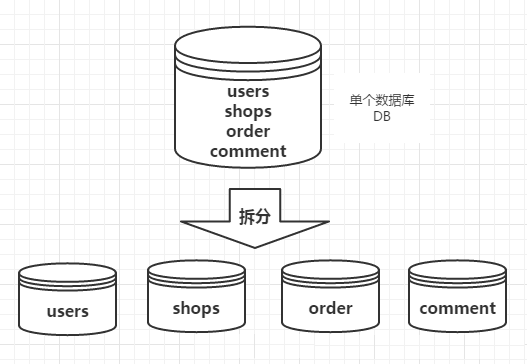
但是,随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,系统的吞吐量自然就提高了。
(2)主从复制
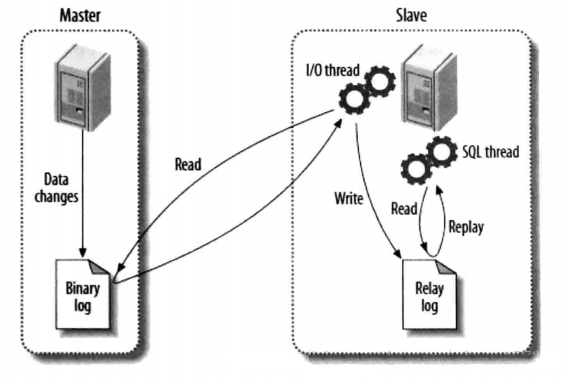
上图是网上的一张关于MySQL的Master和Slave之间数据同步的过程图。
主要讲述了MySQL主从复制的原理:数据复制的实际就是Slave从Master获取Binary log文件,然后再本地镜像的执行日志中记录的操作。由于主从复制的过程是异步的,因此Slave和Master之间的数据有可能存在延迟的现象,此时只能保证数据最终的一致性。
(3)数据库分库与分表
我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是通过添加更多的机器来共同承担压力。
我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?因此,使用数据库的分库分表,能够立竿见影的提升系统的性能,关于为什么要使用数据库的分库分表的其他原因这里不再赘述,主要讲具体的实现策略。
分表实现策略
关键字:用户ID、表容量
对于大部分数据库的设计和业务的操作基本都与用户的ID相关,因此使用用户ID是最常用的分库的路由策略。用户的ID可以作为贯穿整个系统用的重要字段。因此,使用用户的ID我们不仅可以方便我们的查询,还可以将数据平均的分配到不同的数据库中。(当然,还可以根据类别等进行分表操作,分表的路由策略还有很多方式)
说到这里顺便给大家推荐一个Java架构方面的交流学习群:473984645,里面会分享一些资深架构师录制的视频录像:有Spring,MyBatis,Netty源码分析,高并发、高性能、分布式、微服务架构的原理,JVM性能优化这些成为架构师必备的知识体系。还能领取免费的学习资源和前辈的面试经验和面试题,相信对于已经工作和遇到技术瓶颈的码友,在这个群里会有你需要的内容。
接着上述电商平台假设,订单表order存放用户的订单数据,sql脚本如下(只是为了演示,省略部分细节):
2
3
4
5
2 `order_id` bigint(32) primary key auto_increment,
3 `user_id` bigint(32),
4 ...)
5
当数据比较大的时候,对数据进行分表操作,首先要确定需要将数据平均分配到多少张表中,也就是:表容量。
这里假设有100张表进行存储,则我们在进行存储数据的时候,首先对用户ID进行取模操作,根据 user_id%100 获取对应的表进行存储查询操作,示意图如下:
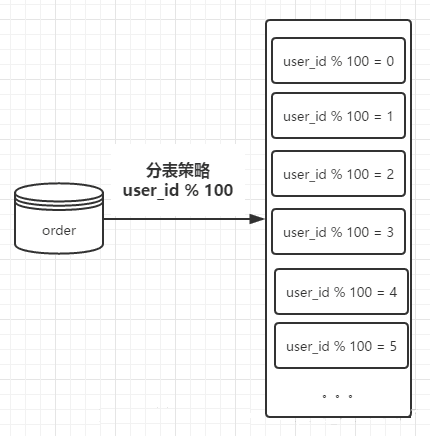
例如,user_id = 101 那么,我们在获取值的时候的操作,可以通过下边的sql语句:
2
2
其中,order_1是根据 101%100 计算所得,表示分表之后的第一章order表。
注意:在实际的开发中,如果你使用MyBatis做持久层的话,MyBatis已经提供了很好得支持数据库分表的功能,例如上述sql用MyBatis实现的话应该是:
接口定义:
2
3
4
5
6
7
8
9
2 * 获取用户相关的订单详细信息
3 * @param tableNum 具体某一个表的编号
4 * @param userId 用户ID
5 * @return 订单列表
6 */
7public List<Order> getOrder(@Param("tableNum") int
8 tableNum,@Param("userId") int userId);
9
xml配置映射文件:
2
3
4
5
2 select * from order_${tableNum}
3 where user_id = #{userId}
4 </select>
5
其中${tableNum} 含义是直接让参数加入到sql中,这是MyBatis支持的特性。
注意:另外,在实际的开发中,我们的用户ID更多的可能是通过UUID生成的,这样的话,我们可以首先将UUID进行hash获取到整数值,然后在进行取模操作。
分库实现策略
数据库分表能够解决单表数据量很大的时候数据查询的效率问题,但是无法给数据库的并发操作带来效率上的提高,因为分表的实质还是在一个数据库上进行的操作,很容易受数据库IO性能的限制。
因此,如何将数据库IO性能的问题平均分配出来,很显然将数据进行分库操作可以很好地解决单台数据库的性能问题。
分库策略与分表策略的实现很相似,最简单的都是可以通过取模的方式进行路由。还是上例,将用户ID进行取模操作,这样的话获取到具体的某一个数据库,同样关键字有:
用户ID、库容量
路由的示意图如下:
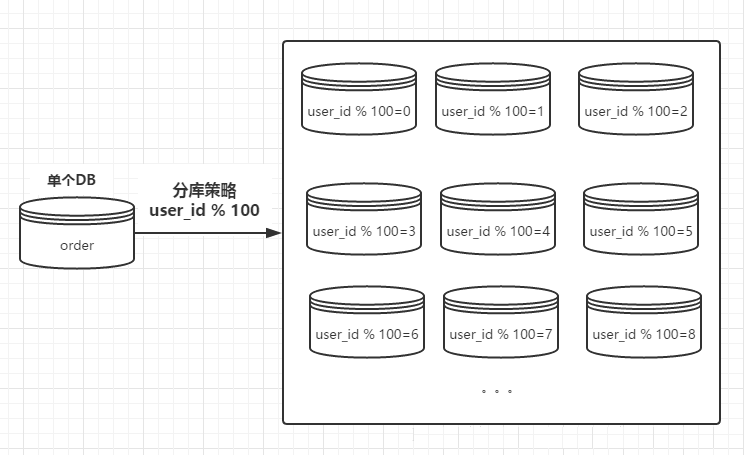
上图中库容量为100。同样,如果用户ID为UUID请先hash然后在进行取模。
分库与分表实现策略
上述的配置中,数据库分表可以解决单表海量数据的查询性能问题,分库可以解决单台数据库的并发访问压力问题。
有时候,我们需要同时考虑这两个问题,因此,我们既需要对单表进行分表操作,还需要进行分库操作,以便同时扩展系统的并发处理能力和提升单表的查询性能,就是我们使用到的分库分表。
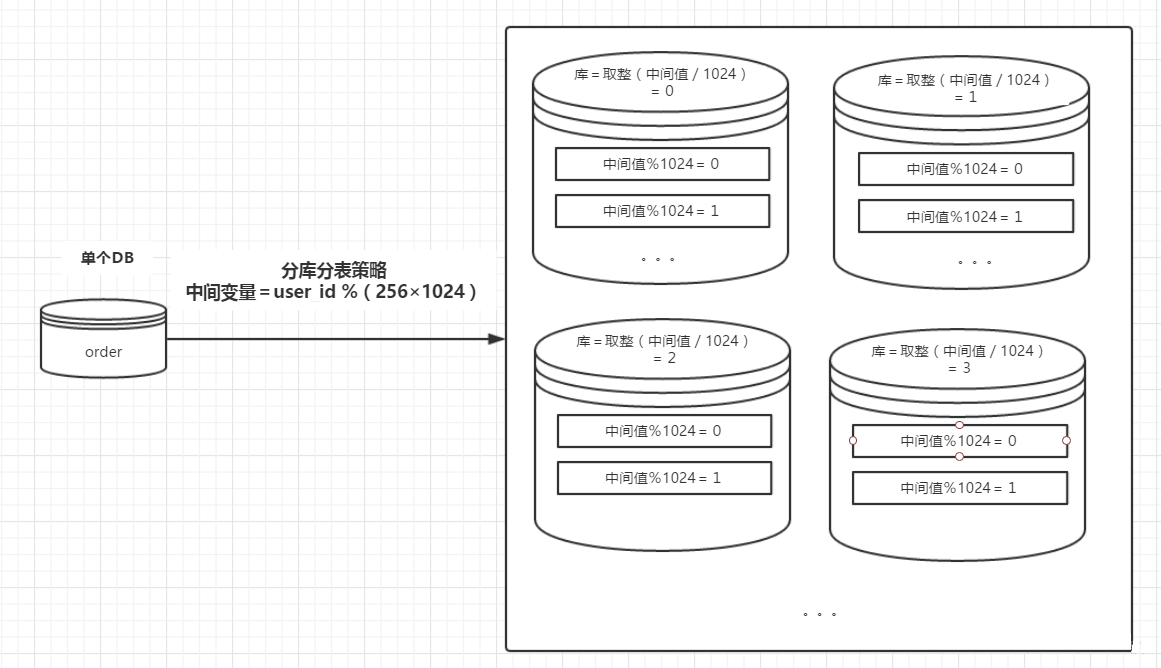
分库分表的策略相对于前边两种复杂一些,一种常见的路由策略如下:
2
3
4
5
22、库序号 = 取整(中间变量/每个库的表数量);
33、表序号 = 中间变量%每个库的表数量;
4
5
例如:数据库有256 个,每一个库中有1024个数据表,用户的user_id=262145,按照上述的路由策略,可得:
2
3
4
5
22、库序号 = 取整(1/1024)= 0;
33、表序号 = 1%1024 = 1;
4
5
这样的话,对于user_id=262145,将被路由到第0个数据库的第1个表中。示意图如下: